
超有趣!手把手教你用Python實現實時“人臉檢測”

Instagram 的聯合創始人兼首席技術官 Mike Kreiger 說:“計算機視覺和機器學習其實已開始流行起來,但是對於大多數人來說,計算機看了影象後看到了什麼這方面還是比較模糊。”


近年來,計算機視覺這個神奇的領域已漸成氣候。該技術在世界各地已有廣泛的應用,而我們才開了個頭!
我在這個領域最喜歡的事情之一是我們的社群擁抱開源這個概念。連各大科技巨頭也願意與每個人分享新的突破和創新,以便這項技術不會成為“有錢人的玩物”。
人臉檢測就是這樣一種技術,它在實際用例下擁有廣泛的潛在用途(如果使用得當且符合倫理道德)。在本文中我將介紹如何使用開源工具構建一種功能強大的人臉檢測演算法。
人臉檢測大有前景的應用
讓我舉幾個表明人臉檢測技術在普遍使用的典例。我確信你肯定在某個時候碰到過這些用例,只是沒有意識到幕後使用了什麼技術!
比如,Facebook 把影象手動標記換成了為上傳到平臺的每張圖片建議自動生成的標記。
Facebook 使用一種簡單的人臉檢測演算法來分析影象中人臉的畫素,並將其與相關使用者進行比較。
我們將學習如何自行構建一個人臉檢測模型,但在深入介紹這方面的技術細節之前,不妨討論另外幾個用例。
我們習慣於使用最新的“人臉解鎖”功能解鎖手機。這是表明如何使用人臉檢測技術來保持個人資料安全性的一個很小的例子。
同樣技術可以在更大的規模內予以實現,使攝像頭能夠捕捉影象、檢測人臉。
在廣告、醫療保健和銀行等行業,有另外幾個鮮為人知的人臉檢測應用。在大多數公司或甚至在許多會議中,你需要攜帶身份證件才能進入。
但如果我們能找到一種方法,不需要攜帶任何身份證件就能進入,將會怎麼樣?
人臉檢測有助於使這個過程流暢簡單。人只要看一眼攝像頭,它就會自動檢測要不要允許他/她進入。
人臉檢測的另一個值得關注的應用是可以計算參加活動(比如會議或音樂會)的人數。
我們安裝了一個可以捕獲參與者影象併為我們提供總人數的攝像頭,而不是手動計算參與者。這有助於使整個過程自動化,並節省大量手動工作。是不是覺得很有用?
在本文中我將著重介紹人臉檢測的實際應用,簡單介紹其中的演算法是如何工作的。
如何使用手頭開源工具實現人臉檢測
你已瞭解了人臉檢測技術的潛在應用場景,不妨看看我們如何使用手頭的開源工具來實現這項技術。
具體就本文而言,這是我使用和推薦使用的軟硬體:
- 用來在聯想 E470 ThinkPad 膝上型電腦(酷睿 i5 第 7 代)上構建實時人臉檢測系統的網路攝像頭(羅技 C920)。
你還可以在其他任何適當的系統上使用膝上型電腦的內建攝像頭或閉路電視攝像頭用於實時視訊分析,而不是採用我使用的這套設定。
- 使用 GPU 進行更快速的視訊處理始終是額外好處。
- 在軟體方面,我們使用了已安裝所有必備軟體的 Ubuntu 18.04 作業系統。
不妨更深入一點地探討這幾點,確保在構建人臉檢測模型之前已正確設定好了一切。
第 1 步:硬體設定
你要做的第一件事是檢查網路攝像頭是否設定正確。Ubuntu 中的一個簡單技巧是檢視裝置是否已被作業系統註冊。
可以按照下列步驟來操作:
- 將網路攝像頭連線到膝上型電腦之前,進入到命令提示符並輸入 ls /dev/video*,檢查所有已連線的視訊裝置。這會輸出顯示已連線到系統的視訊裝置。
- 連線網路攝像頭,並再次執行上述命令。如果網路攝像頭已成功連線,命令會顯示一個新裝置。
- 可以做的另一件事是使用任何網路攝像頭軟體來檢查網路攝像頭是否正常工作。你可以在 Ubuntu 中使用“Cheese”來執行這番操作。
這裡我們可以看到網路攝像頭已正確設定。硬體方面就是這些!
第 2 步:軟體設定
①安裝 Python
本文中的程式碼是用 Python 版本 3.5 構建的。雖然有多種方法來安裝 Python,但我建議使用 Anaconda,這是最流行的資料科學 Python 發行版。
這是系統中安裝 Anaconda 的連結:
https://www.anaconda.com/download
②安裝 OpenCV
OpenCV(開源計算機視覺)是一個旨在構建計算機視覺應用程式的庫。它有許多用於影象處理任務的預編寫函式。
想安裝 OpenCV,對庫進行 pip 安裝:
pip3 install opencv-python
③安裝 face_recognition API
最後,我們將使用 face_recognition,這號稱是世界上最簡單的面向 Python 的人臉識別 API。
想安裝它,請執行下列命令:
pip install dlib pip install face_recognition
深入瞭解實現方式
現在你已設定好了系統,終於可以深入瞭解實際的實現方式。首先,我們將迅速構建程式,然後對其分解以瞭解我們所做的工作。
先建立一個檔案 face_detector.py,然後拷貝如下所示的程式碼:
# import libraries
import cv2
importface_recognition
# Get a reference towebcam
video_capture =cv2.VideoCapture("/dev/video1")
# Initialize variables
face_locations = []
while True:
# Grab a single frame of video
ret, frame = video_capture.read()
# Convert the image from BGR color (whichOpenCV uses) to RGB color (which face_recognition uses)
rgb_frame = frame[:, :, ::-1]
# Find all the faces in the current frameof video
face_locations =face_recognition.face_locations(rgb_frame)
# Display the results
for top, right, bottom, left inface_locations:
# Draw a box around the face
cv2.rectangle(frame, (left, top),(right, bottom), (0, 0, 255), 2)
# Display the resulting image
cv2.imshow('Video', frame)
# Hit 'q' on the keyboard to quit!
if cv2.waitKey(1) & 0xFF == ord('q'):
break
# Release handle tothe webcam
video_capture.release()
cv2.destroyAllWindows()
然後,輸入以下命令,執行該 Python 檔案:
python face_detector.py
如果一切正常,會彈出一個新視窗,實時人臉檢測在執行中
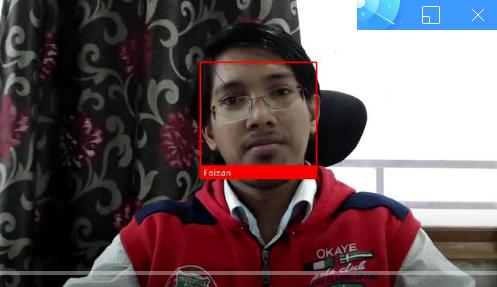
總結一下,這是我們上述程式碼執行的操作:
- 首先,我們定義了將進行視訊分析的硬體。
- 此後,我們實時捕捉視訊,逐幀捕捉。
- 然後,我們處理每幀,並提取影象中所有人臉的位置。
- 最後,我們以視訊形式渲染這些幀以及人臉位置。
是不是很簡單?如果你想了解更具體的細節,我已在每個程式碼部分中包含註釋。你可以隨時返回檢視。
人臉檢測的用例
樂趣並不僅限於此!我們能做的另一件很酷的事情就是圍繞上述程式碼構建完整的用例。而且你無需從頭開始,我們只要對程式碼進行幾處小小的改動即可。
比如說,假設你想構建一個基於攝像頭的自動系統來實時跟蹤說話人的位置。根據其位置,系統轉動攝像頭,以便說話人始終在視訊的中間。
我們該如何解決這個問題?第一步是構建識別視訊中一個人或多個人的系統,並關注說話人的位置。
不妨看看我們如何實現這一點。為了本文需要,我從 Youtube 上下載了一段視訊(https://youtu.be/A_-KqX-RazQ),視訊中有個人在 2017 年 DataHack 峰會上講話。
首先,我們匯入必要的庫:
import cv2 importface_recognition
然後,閱讀視訊並獲取長度:
input_movie =cv2.VideoCapture("sample_video.mp4")
length = int(input_movie.get(cv2.CAP_PROP_FRAME_COUNT))
之後,我們建立一個擁有所需解析度和幀速率的輸出檔案,與輸入檔案類似。
載入說話人的示例影象以便在視訊中識別他:
image =face_recognition.load_image_file("sample_image.jpeg")
face_encoding =face_recognition.face_encodings(image)[0]
known_faces = [
face_encoding,
]
這一切都已完成,現在我們執行一個迴圈,它將執行以下操作:
- 從視訊中提取幀。
- 找到所有人臉,並識別它們。
- 建立一個新視訊,將原始幀與標註的說話人人臉位置相結合。
不妨看看這個程式碼:
# Initialize variables
face_locations = []
face_encodings = []
face_names = []
frame_number = 0
while True:
# Grab a single frame of video
ret, frame = input_movie.read()
frame_number += 1
# Quit when the input video file ends
if not ret:
break
# Convert the image from BGR color (whichOpenCV uses) to RGB color (which face_recognition uses)
rgb_frame = frame[:, :, ::-1]
# Find all the faces and face encodings inthe current frame of video
face_locations =face_recognition.face_locations(rgb_frame, model="cnn")
face_encodings =face_recognition.face_encodings(rgb_frame, face_locations)
face_names = []
for face_encoding in face_encodings:
# See if the face is a match for theknown face(s)
match =face_recognition.compare_faces(known_faces, face_encoding, tolerance=0.50)
name = None
if match[0]:
name = "Phani Srikant"
face_names.append(name)
# Label the results
for (top, right, bottom, left), name inzip(face_locations, face_names):
if not name:
continue
# Draw a box around the face
cv2.rectangle(frame, (left, top),(right, bottom), (0, 0, 255), 2)
# Draw a label with a name below theface
cv2.rectangle(frame, (left, bottom -25), (right, bottom), (0, 0, 255), cv2.FILLED)
font = cv2.FONT_HERSHEY_DUPLEX
cv2.putText(frame, name, (left + 6,bottom - 6), font, 0.5, (255, 255, 255), 1)
# Write the resulting image to the outputvideo file
print("Writing frame {} /{}".format(frame_number, length))
output_movie.write(frame)
# All done!
input_movie.release()
cv2.destroyAllWindows()
然後程式碼會給出這樣的輸出:

人臉檢測真是了不起的本領。
結論
恭喜!你現在知道如何為許多潛在用例構建人臉檢測系統了。深度學習是非常迷人的領域,我很期望下一步的方向。
我們在本文中學習瞭如何利用開源工具構建具有實際用途的實時人臉檢測系統。
我鼓勵各位構建眾多這樣的應用,並自己試一試。相信我,你能學到好多東西,而且蠻有意思。