
Fine-tuning Approaches -- OpenAI GPT 學習筆記
1、Fine-tuning Approaches
從語言模型轉移學習的一個趨勢是,在監督的下游任務中相同模型的微調之前,一個語言模型目標上預訓練一些模型體系結構。這些方法的優點是幾乎沒有什麼引數需要從頭學習。至少部分由於這一優勢,OpenAI GPT在GLUE benchmark的許多句子級別任務上取得了以前最先進的結果。
微調是必須非常精確地調整模型引數以適應某些觀察的過程。在沒有已知機制來解釋為什麼引數恰好具有它們返回的觀察值的情況下,需要微調的理論被認為是有問題的。
2、OpenAI GPT
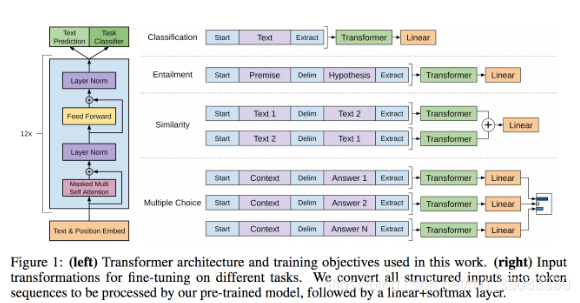
該方法主要結合了Transfromer和無監督預訓練。
主要分為兩個階段:
(1)首先以無監督的方式在大型資料集上訓練一個 Transformer,即使用語言建模作為訓練訊號。
(2)然後在小得多的有監督資料集上精調模型以解決具體任務。
這一項研究任務建立在Semi-supervised Sequence Learning論文中所提出的方法,該方法展示瞭如何通過無監督預訓練的 LSTM 與有監督的精調提升文字分類效能。這一項研究還擴充套件了論文Universal Language Model Fine-tuning for Text Classification所提出的 ULMFiT 方法,它展示了單個與資料集無關的 LSTM 語言模型如何進行精調以在各種文字分類資料集上獲得當前最優的效能。
OpenAI 的研究工作展示瞭如何使用基於 Transformer 的模型,並在精調後能適應於除文字分類外其它更多的任務,例如常識推理、語義相似性和閱讀理解。
該方法與 ELMo 相似但更加通用,ELMo 同樣也結合了預訓練,但需要使用為任務定製的架構以在各種任務中取得當前頂尖的效能。
OpenAI 只需要很少的調整就能實現最後的結果。所有資料集都使用單一的前向語言模型,且不使用任何整合方法,超參配置也與大多數研究成果相同。