
keras-遷移學習(fine-tuning)
阿新 • • 發佈:2019-01-07
不同修改預訓練模型方式的情況:
- 特徵提取
我們可以將預訓練模型當做特徵提取裝置來使用。具體的做法是,將輸出層去掉,然後將剩下的整個網路當做一個固定的特徵提取機,從而應用到新的資料集中。 - 採用預訓練模型的結構
我們還可以採用預訓練模型的結構,但先將所有的權重隨機化,然後依據自己的資料集進行訓練。 - 訓練特定層,凍結其它層
另一種使用預訓練模型的方法是對它進行部分的訓練。具體的做法是,將模型起始的一些層的權重保持不變,重新訓練後面的層,得到新的權重。在這個過程中,我們可以多次進行嘗試,從而能夠依據結果找到frozen layers和retrain layers之間的最佳搭配。
如何使用與訓練模型,是由資料集大小和新舊資料集(預訓練的資料集和我們要解決的資料集)之間資料的相似度來決定的。
下圖表展示了在各種情況下應該如何使用預訓練模型:
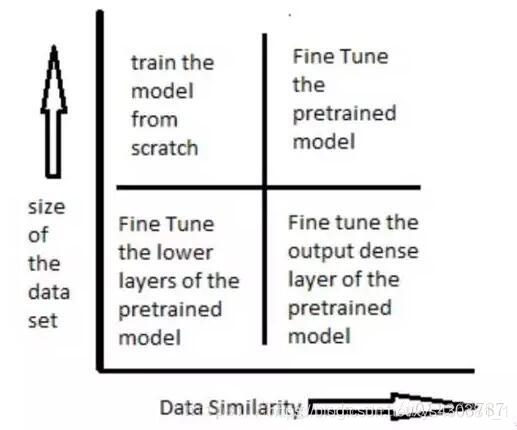
原文:https://blog.csdn.net/u011268787/article/details/80170482
fine-tuning方式一:使用預訓練網路的bottleneck特徵
先看VGG-16的網路結構如下:
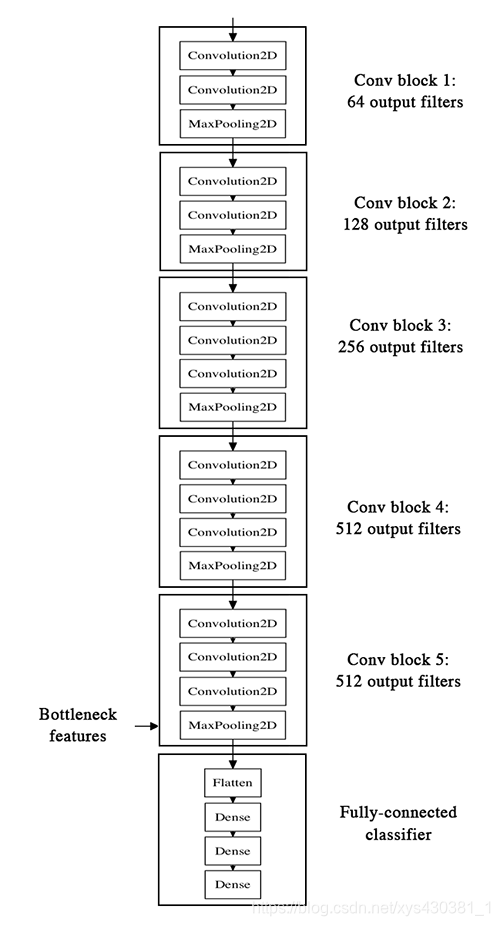
本節主要是通過已經訓練好的模型,把bottleneck特徵抽取出來,然後滾到下一個“小”模型裡面,也就是全連線層。
實施步驟為:
1、把訓練好的模型的權重拿來,model; 2、執行,提取bottleneck feature(網路在全連線之前的最後一層啟用的feature map,卷積-全連線層之間),單獨拿出來,並儲存 3、bottleneck層資料,之後 + dense全連線層,進行fine-tuning
1、匯入預訓練權重與網路框架
WEIGHTS_PATH = '/home/ubuntu/keras/animal5/vgg16_weights_tf_dim_ordering_tf_kernels.h5' WEIGHTS_PATH_NO_TOP = '/home/ubuntu/keras/animal5/vgg16_weights_tf_dim_ordering_tf_kernels_notop.h5' from keras.applications.vgg16_matt import VGG16 model = VGG16(include_top=False, weights='imagenet')
其中WEIGHTS_PATH_NO_TOP 就是去掉了全連線層,可以用他直接提取bottleneck的特徵
2、提取圖片的bottleneck特徵
需要步驟:
1. 載入圖片;
2. 灌入pre-model的權重;
3. 得到bottleneck feature
程式碼:
#如何提取bottleneck feature
from keras.models import Sequential
from keras.layers import Conv2D, MaxPooling2D
from keras.layers import Activation, Dropout, Flatten, Dense
# (1)載入圖片
# 影象生成器初始化
from keras.preprocessing.image import ImageDataGenerator
import numpy as np
datagen = ImageDataGenerator(rescale=1./255)
# 訓練集影象生成器
generator = datagen.flow_from_directory( '/home/ubuntu/keras/animal5/train',
target_size=(150, 150), batch_size=32, class_mode=None, shuffle=False)
# 驗證集影象生成器
generator = datagen.flow_from_directory( '/home/ubuntu/keras/animal5/validation',
target_size=(150, 150), batch_size=32, class_mode=None, shuffle=False)
#(2)灌入pre-model的權重
model.load_weights('/.../vgg16_weights_tf_dim_ordering_tf_kernels_notop.h5')
#(3)得到bottleneck feature
bottleneck_features_train = model.predict_generator(generator, 500)
#核心,steps是生成器要返回資料的輪數,每個epoch含有500張圖片,與model.fit(samples_per_epoch)相對
np.save(open('bottleneck_features_train.npy', 'w'), bottleneck_features_train)
bottleneck_features_validation = model.predict_generator(generator, 100)
#與model.fit(nb_val_samples)相對,一個epoch有800張圖片,驗證集
np.save(open('bottleneck_features_validation.npy', 'w'), bottleneck_features_validation)
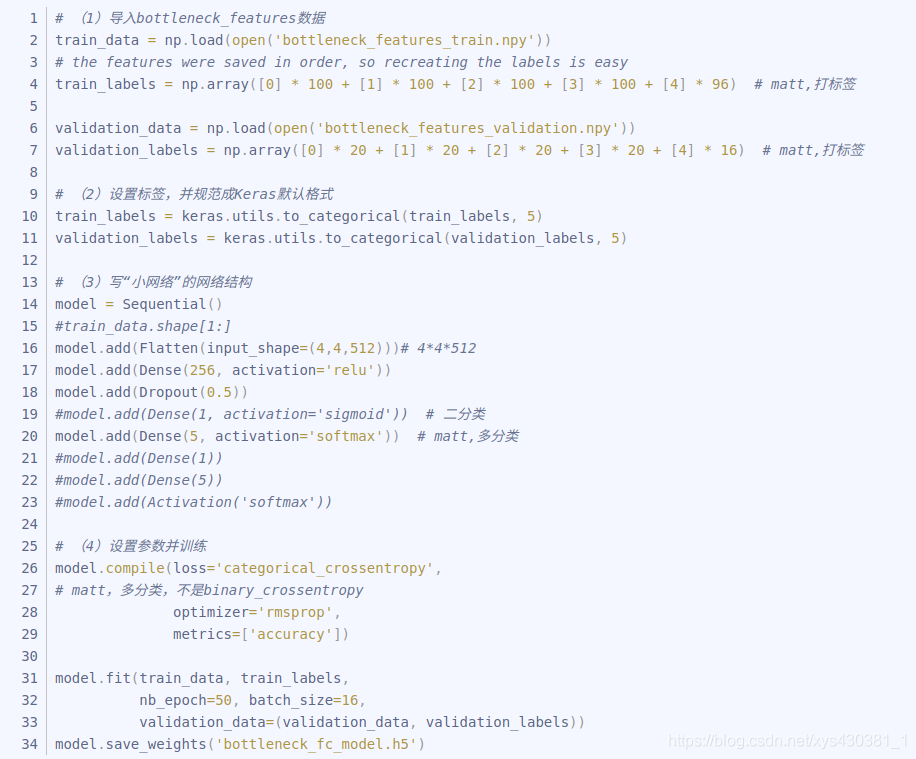
3、 fine-tuning - "小"網路
主要步驟:
(1)匯入bottleneck_features資料;
(2)設定標籤,並規範成Keras預設格式;
(3)寫“小網路”的網路結構
(4)設定引數並訓練
fine-tuning方式二:要調整權重
先來看看整個結構。
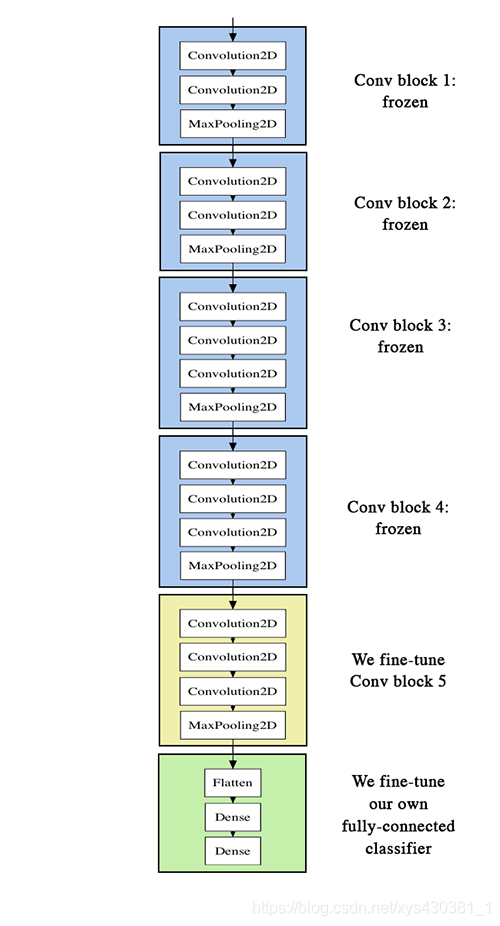
fine-tune分三個步驟:
- 搭建vgg-16並載入權重,將之前定義的全連線網路加在模型的頂部,並載入權重
- 凍結vgg16網路的一部分引數
- 模型訓練
注意:
1、fine-tune,所有的層都應該以訓練好的權重為初始值,例如,你不能將隨機初始的全連線放在預訓練的卷積層之上,這是因為由隨機權重產生的大梯度將會破壞卷積層預訓練的權重。
2、選擇只fine-tune最後的卷積塊,而不是整個網路,這是為了防止過擬合。整個網路具有巨大的熵容量,因此具有很高的過擬合傾向。由底層卷積模組學習到的特徵更加一般,更加不具有抽象性,因此我們要保持前兩個卷積塊(學習一般特徵)不動,只fine-tune後面的卷積塊(學習特別的特徵)
3、fine-tune應該在很低的學習率下進行,通常使用SGD優化而不是其他自適應學習率的優化演算法,如RMSProp。這是為了保證更新的幅度保持在較低的程度,以免毀壞預訓練的特徵。
1、步驟一:搭建vgg-16並載入權重

2、凍結vgg16網路的一部分引數
然後將最後一個卷積塊前的卷積層引數凍結:

3、模型訓練
然後以很低的學習率進行訓練:
