
Benchmarking Single Image Dehazing and Beyond
摘要
我們對現有的單影象去霧演算法進行了全面的研究和評估,使用了一個新的大尺度基準,包括合成和真實世界的模糊影象,稱為REalistic Single Image Dehazing(RESIDE)。
RESIDE突出顯示了各種資料來源和影象內容,並分為五個子集,每個子集用於不同的訓練或評估目的。 我們進一步提供了各種各樣的去霧演算法評估標準,從完整參考度量,無參考度量,到主觀評估和新穎的任務驅動評估。 在RESIDE上的實驗揭示了最先進的除霧演算法的比較和侷限性,並提出了有希望的未來方向。
索引術語 - 去霧,檢測,資料集,評估
1 介紹
單圖去霧
由於存在霧霾,在室外場景中捕獲的影象經常遭受差的可見性,對比度降低,表面暈染和顏色偏移。由灰塵,霧氣和煙霧等氣溶膠引起的霧霾的存在給影象增加了複雜的,非線性的和資料相關的噪聲,使得霧霾去除(例如去霧)成為極具挑戰性的影象恢復和增強問題。此外,許多計算機視覺演算法只能很好地適應無霧的場景輻射。然而,可靠的視覺系統必須考慮來自無約束環境的整個降級範圍。以自動駕駛為例,朦朧有霧的天氣會掩蓋車載攝像頭的視野,造成令人困惑的反射和眩光,使最先進的自動駕駛汽車陷入困境[1]。因此,Dehazing成為計算攝影和計算機視覺任務中越來越受歡迎的技術,其進步將立即使許多盛行的應用領域受益,例如視訊監控和自動/輔助駕駛.
雖然一些早期的作品考慮來自同一場景的多個影象可用於除霧[3],[4],[5],[6],但單個影象除霧在實踐中被證明是更現實的設定,因此獲得了 占主導地位。 大氣散射模型一直是模糊影象生成的經典描述[7],[8],[9]:
I (x) = J (x) t (x) + A(1 - t (x)) ;
傳輸矩陣定義為:
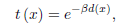
其中是beta大氣的散射係數,d(x)是物體和相機之間的距離。
為了求原圖:
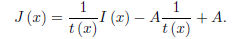
大多數最先進的單影象去霧方法利用物理模型(1),並以物理接地或資料驅動的方式估計關鍵引數A和t(x)。方法表現不斷提高 [10],[11],[12],[13],[14],[15],[16],[17],特別是在最新模型深入學習之後[18]],[19],[20]。
現有方法:概述
給定大氣散射模型,大多數去霧方法遵循類似的三步方法:
(1)從模糊影象I(x)估計傳輸矩陣t(x);
(2)使用其他一些(通常是經驗的)方法估計A;
(3)通過計算(3)估計原影象J(x)。
通常,大部分注意力都集中在第一步,它可以依賴於物理真值的先驗或完全資料驅動的方法。
一個值得注意的去霧方法利用了自然影象先驗和深度統計。 [21]強加了反照率值的區域性恆定約束以及區域性區域中傳輸的去相關,然後使用反照率估計和原始影象估計深度值。它沒有約束場景深度結構,因此經常導致顏色或深度的不準確估計。 [22],[23]發現暗通道先驗(DCP)更可靠地計算傳輸矩陣,其次是許多後繼者。然而,當場景物體與大氣光相似時,發現先驗不可靠[19]。 [12]強制執行邊界約束和上下文正則化以實現更清晰的修復。 [14]先前開發了顏色衰減,併為模糊影象建立了場景深度的線性模型,然後以監督的方式學習了模型引數。 [24]聯合估計場景深度並從模糊的視訊序列中恢復清晰的潛像。 [15]基於假設清晰影象中的每個顏色簇成為RGB空間中的霧度線,提出了非區域性先驗。
鑑於==卷積神經網路(CNN)==在計算機視覺任務中的普遍成功,幾種去霧演算法依靠各種CNN直接從資料中學習t(x),以避免通常不準確估計物理引數。 單個影象。 DehazeNet [18]提出了一種可訓練的模型,用於從模糊影象中估計傳輸矩陣。 [19]提出了一個多尺度CNN(MSCNN),它首先產生了一個粗尺度的傳輸矩陣並逐漸完善它。 儘管取得了令人鼓舞的結果,但訓練資料的固有侷限性正成為這一蓬勃發展趨勢的一個越來越嚴重的障礙:更多討論見第II-1節。
此外,除了單獨估計引數的次優程式之外,已做出一些努力,當將它們組合在一起以計算(3)時,這將導致累積或甚至放大的誤差。 相反,他們提倡同步和統一的引數估計。 早期的作品[25],[26]用一個階乘馬爾可夫隨機場模擬了模糊影象,其中t(x)和A是兩個統計獨立的潛在層。 此外,一些研究人員還研究了更具挑戰性的夜間除霧問題[27],[28],這超出了本文的重點。
另一系列研究[29],[30]試圖利用Retinex理論通過反射光的比率來近似物體表面的光譜特性。 最近,[20]提出了重新制定(2)以將t(x)和A整合為一個新變數。 因此他們的CNN除霧模型是完全端到端的:J(x)直接從I(x)生成,沒有任何中間引數估計步驟。 這個想法後來被擴充套件到[31]中的視訊去霧。
儘管單影象去霧演算法繁榮,但該領域的進一步發展仍存在一些障礙。 在大規模公共資料集上缺乏對最先進演算法的基準測試工作。 此外,用於評估和比較影象去霧演算法的當前度量標準大多隻是PSNR和SSIM,其結果不足以表徵人類感知質量或機器視覺效果。
提出三項貢獻:
- 我們引入了一種新的單影象去霧基準,稱為真實單影象去霧(RESIDE)資料集。 它具有大規模的綜合訓練集,以及分別為客觀和主觀質量評估設計的兩套不同的資料集。 我們進一步介紹RESIDE-beta集,這是RESIDE基準測試的一個探索和補充部分,包括關於當前訓練資料內容(室內和室外影象)和評估標準(從人類視覺或機器視覺角度)的障礙的兩個創新討論。 特別是在後一部分,我們使用物件邊界框來註釋一個由任務驅動的4,322個真實世界模糊影象的評估集,這是它的第一個貢獻。
- 我們根據新的RESIDE和RESIDE-beta資料集引入一套創新的評估策略。 在RESIDE中,除了廣泛採用的PSNR和SSIM之外,我們進一步採用無參考度量和人類主觀評分來評估去霧效果,特別是對於沒有清晰GT的真實世界模糊影象。 在RESIDE-中,我們認識到實際中的影象去霧通常用作中級和高階視覺任務的預處理步驟。 因此,我們建議利用感知損失[32]作為“全參考”任務驅動的度量,捕獲更高級別的語義,並將去噪影象上的物件檢測效能作為“無參考”任務特定的評估標準,用於去霧現實影象[20]。
- 我們進行了廣泛而系統的實驗,以定量比較九種最先進的單一影象去霧演算法,使用新的RESIDE和RESIDE-beta資料集以及建議的各種評估標準。 我們的評估和分析展示了最先進演算法的效能和侷限性,並帶來了豐富的見解。 這些實驗的結果不僅證實了人們普遍認為的,而且還提出了單一影象去霧的新研究方向。
RESIDE的概述可以在表I中找到。

我們注意到本文中使用的一些策略已經在文獻中被更多或更小程度地使用,例如去霧中的無參考指標[33],主觀評價 [34],並將去霧與高階任務聯絡起來[20] (AODNET)。 然而,RESIDE是迄今為止第一個也是唯一一個系統評估,其中包括許多去霧演算法,這些演算法在一個共同的大規模基準測試中具有多個標準,這在文獻中很早就缺失了。
2 資料集和評估:現狀
1)訓練資料:許多影象恢復和增強任務受益於持續努力的標準化基準,以便在相同條件下比較不同的提議方法,如[35],[36]。 相比之下,由於收集或建立具有乾淨的地面實況參考的真實模糊影象的重大挑戰,一直存在一個常見的大規模基準測試用於去霧。 通常不可能在有霧和沒有霧的情況下捕獲相同的視覺場景,而所有其他環境條件保持相同。 因此,最近的去霧模型[37],[34]通常通過從乾淨的影象建立合成的模糊影象來生成他們的訓練集:他們首先通過利用深度影象資料集的可用深度圖或者估計乾淨影象來獲得乾淨影象的深度圖或者評估深度[38]; 然後通過計算(1)生成模糊影象。 然後可以訓練資料驅動的去霧模型以從朦朧的影象中迴歸乾淨的影象。
Fattal的資料集[37]提供了12個合成影象。 FRIDA [39]製作了420套合成影象,用於評估各種朦朧環境中自動駕駛系統的效能。 它們都太小而無法訓練有效的去霧模型。 為了形成大規模的訓練集,[19],[20]使用來自室內NYU2深度資料庫[40]和米德爾伯裡立體資料庫[41]的深度元資料的地面真實影象。 最近,[34]使用不完整的深度資訊,使用來自Cityscapes資料集的25,000張影象,使用不完整的深度資訊.Dataset [42]生成了來自Cityscapes資料集的25,000張影象的Foggy Cityscapes資料集[42]。
2)測試資料和評估標準:使用的測試集主要是具有已知基本事實的合成模糊影象,儘管一些演算法也在真實模糊影象上進行了視覺評估[19],[18],[20]。
有了多種去霧演算法,找到適當的評估標準來比較它們的去霧效果變得至關重要。大多數去霧演算法假設合成測試集也具有已知的清潔GT,依賴於完全參考PSNR和SSIM度量。如上所述,由於合成和真實模糊影象之間的大量內容差異,即使實現了有希望的測試效能,它們的實際適用性也可能處於危險之中。為了在沒有參考的情況下客觀地評估真實模糊影象上的去霧演算法,無參考影象質量評估(IQA)模型[43],[44],[45]是可能的候選者。 [33]在一組自我收集的25個模糊影象(沒有清晰的基礎事實)的幾個去霧方法中測試了一些無參考目標IQA模型,但沒有比較任何最新的基於CNN的去霧模型。最近的一項工作[46]收集了14個真實室外場景和相應深度圖的無霧影象,提供了一個小的真實測試集。
PSNR / SSIM以及其他客觀指標通常與人類感知的視覺質量很差[33]。 許多論文在視覺上顯示了除霧結果,但最先進的除霧演算法之間的結果差異往往太微妙,人們無法可靠地判斷。 這表明進行主觀研究的必要性,到目前為止尚未做出太多努力[47],[33]。
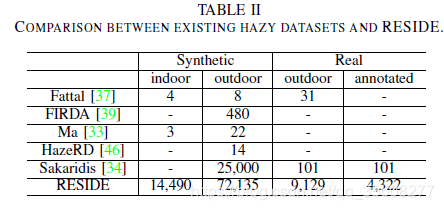
在表II中比較了所有上述模糊影象資料集以及RESIDE。 如圖所示,大多數現有資料集規模太小,或缺乏足夠的真實世界影象(或註釋)用於不同的評估。
RESIDE
我們提出了REalistic單影象去霧(RESIDE)資料集,這是一個新的大規模資料集,用於公平地評估和比較單影象去霧演算法。 RESIDE的一個顯著特徵在於其評估標準的多樣性,從傳統的完整參考指標到更實用的無參考指標,以及所需的人類主觀評級。 一組新的任務驅動的評估選項將在本文後面討論。
總覽
REISDE訓練集包含13,990個合成模糊影象,使用來自現有室內深度資料集NYU2 [40]和Middlebury立體聲[41]的1,399個清晰影象生成。 我們為每個清晰影象合成10個模糊影象。 提供了13,000個用於訓練和990個用於驗證。 我們設定每個通道大氣光A在[0.7,1.0]之間,均勻地隨機選擇beta在[0.6,1.8]。 因此,它包含成對的乾淨和模糊的影象,其中乾淨的地面實況影象可以導致多個對,其朦朧影象是在不同的引數A和beta下生成的。
REISDE測試集由綜合目標測試集(SOTS)和混合主觀測試集(HSTS)組成,旨在表現出多種評估觀點。 SOTS從NYU2 [40]中選擇500個室內影象(與訓練影象不重疊),並按照與訓練資料相同的過程來合成模糊影象。 我們專門為測試建立具有挑戰性的去霧情況,例如,添加了濃霧的白色場景。 HSTS採用與SOTS相同的方式生成10個合成的戶外朦朧影象,以及10個真實世界的朦朧影象,收集現實世界的室外場景[48] ,結合進行人體主觀評審。
評估策略
1)從完全參考到無參考:
儘管用於評估去霧演算法的全參考PSNR / SSIM指標的普及,但由於在實踐中不能獲得乾淨的地面實況影象以它們本身就受到限制與人類感知質量難以保持一致[33]。 因此,我們參考兩個無參考IQA模型:基於空間譜熵的質量(SSEQ)[45],以及使用DCT統計的盲影象完整性標記(BLIINDS-II)[44],以補充PSNR / SSIM的短缺。 請注意,[45]和[44]中使用的SSEQ和BLIINDS2的分數範圍從0(最佳)到100(最差),我們反轉分數以使相關性與完整參考度量一致。
我們將PSNR,SSIM,SSEQ和BLIINDS-II應用於SOTS的去噪結果,並檢查它們產生的除霧演算法排名的一致性。 我們還將在HSTS上應用四個指標(僅在10個合成影象上計算PSNR和SSIM),並進一步將這些客觀測量與主觀評級進行比較。
2)從客觀到主觀:[33]研究了全參考和無參考IQA模型的各種選擇,並發現它們在預測去噪影象的質量方面受到限制。 然後,我們對不同演算法產生的去霧結果的質量進行主觀的使用者研究,從中我們獲得了更多有用的觀察結果。 當真實影象可用作參考時,它們也包括在內。
在之前的[33],[49]中,參與者使用1到10的整數對每個除霧結果影象進行評分,以最好地反映其感知質量。 我們採用不同的方法:(1)要求參與者進行成對比較而不是個人評級,前者通常被認為在主觀調查中更加穩健和一致,[50],[34]也採用了這種方式。 (2)將感知質量分解為兩個維度:去霧清晰度和真實性,前者定義為霧度被徹底消除的程度,後者定義為去霧影象的真實程度。 根據我們的最佳知識,在類似的文獻中尚未探索過這樣兩個解開的維度。 他們的動機是我們的觀察結果,一些演算法會產生看起來很自然的結果,但卻無法完全消除霧霾,而另一些演算法卻以不切實際的視覺偽像的代價消除了霧霾。
在研究期間,每個參與者被顯示出對於相同的模糊影象使用兩種不同演算法獲得的一組去霧結果對。 對於每一對,參與者需要在清晰度方面獨立決定哪一個比另一對更好,然後哪一個更適合真實性。 影象對是從所有競爭方法中隨機抽取的,贏得成對比較的影象將在下一輪[51]中再次進行比較,直到選出最佳的影象。 我們擬合Bradley-Terry [52]模型來估計每個去霧演算法的主觀得分,以便對它們進行排序。
對於同行基準[53],[54]而言,主觀調查並非“自動”擴充套件到新結果。 然而,研究人類感知與客觀指標之間的相關性非常重要,這有助於分析後者的有效性。 我們正準備推出一個排行榜,我們將接受選擇性結果提交,並定期進行新的主觀評審。
4 演算法基準
基於RESIDE提供的豐富資源,我們評估了9種具有代表性的最先進演算法:暗通道先驗(DCP)[10],快速可見性恢復(FVR)[11],邊界約束上下文正則化(BCCR) [12],通過梯度殘差最小化(GRM)[13],色彩衰減先驗(CAP)[14],非區域性影象去霧(NLD)[15],DehazeNet [18],多尺度CNN(MSCNN )[19]和All-in-One Dehazing Network(AOD-Net)[20]。 最後三個屬於最新的基於CNN的去霧演算法。 對於所有資料驅動演算法,它們都在相同的RESIDE訓練集上進行訓練。
SOTS主觀比較
我們首先使用兩個完整參考(PSNR,SSIM)和兩個無參考度量(SSEQ,BLIINDS-II)比較SOTS上的去噪結果。 表III顯示了每個度量的每個演算法的詳細分數。
一般而言,因為基於學習的方法[18],[14],[19],[20]通過直接最小化輸出和GT之間的均方誤差(MSE)損失或最大化大規模資料的概率。 就PSNR和SSIM而言,在大多數情況下,它們明顯優於基於自然或統計先驗的早期演算法[10],[12],[11],[13],[15]。 特別是,DehazeNet [18]獲得了最高的PSNR值,AOD-Net [20]和CAP [14]獲得了次優和第三次PSNR評分。 儘管GRM [13]獲得了最高的SSIM分數,但AOD-Net [20]和DehazeNet [18]仍然獲得了類似的SSIM值。
但是,當涉及無參考指標時,結果變得不那麼一致。 由於端到端畫素校正,AOD-Net [20]仍然通過獲得室內影象的最佳BLIINDS-II結果來保持競爭效能。 另一方面,一些先前的方法,如FVR [11]和NLD [15]也顯示出競爭力:FVR [11]在SSEQ方面排名第一,NLD [15]達到次優的SSEQ和BLIINDS-II。 我們目測觀察結果,發現DCP [10],BCCR [12]和NLD [15]傾向於產生鋒利的邊緣和高度對比的顏色,這解釋了為什麼BLIINDS-II和SSEQ首選它們。 全參考和非參考評估之間的這種不一致以及在現有的客觀IQA模型中的論證[33],表明了對去霧影象的有效預測方面能力很差。
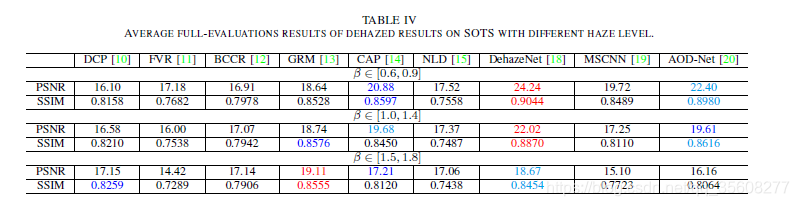
我們進一步使用具有不同霧度濃度水平(即值)的標準評估度量進行實驗,以詳細說明每種方法對於每種不同霧度密度的適合性。 如表IV所示,我們根據範圍將SOTS資料集分成三組。 它清楚地表明,DehazeNet始終是輕度和中度霧度的最佳選擇,而GRM實現了最高的PSNR和SSIM,適用於濃霧。
HSTS的主觀比較
我們使用HSTS招募100名來自不同教育背景的參與者,其中包含10個合成戶外和10個真實世界的模糊影象(共20個)。 我們擬合Bradley-Terry [52]模型來估計每種方法的主觀評分,以便對它們進行排名。 在Bradley-Terry模型中,假設物體X優於Y的概率是:
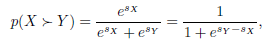
其中sX和sY是X和Y的主觀分數。所有物件的得分s 可以通過最大化對數似然來聯合估計.
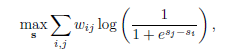
其中wij是獲勝矩陣W中的第(i; j)個元素,表示方法i優於方法j的次數。 我們使用Newton-Raphson方法來求解方程。(5)。 請注意,對於合成影象,我們有10x10個獲勝矩陣W,包括基礎事實和9個去霧方法結果。 對於真實世界的影象,由於缺乏基本事實,其獲勝矩陣W為9 9。 對於合成影象,我們將地面實況方法的得分設定為歸一化分數1。
圖3和4分別顯示了合成影象和真實世界影象上的去霧結果的定性示例。


定量結果可以在表V中找到,
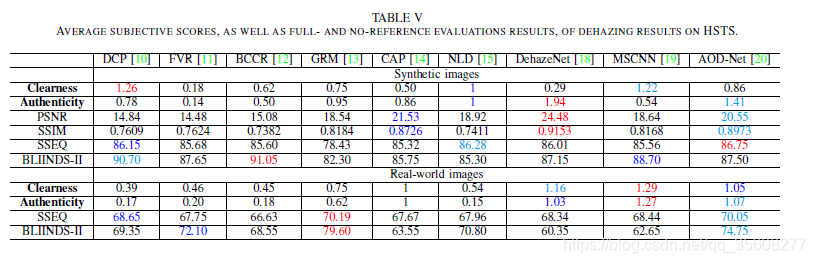
趨勢在圖2中視覺化。
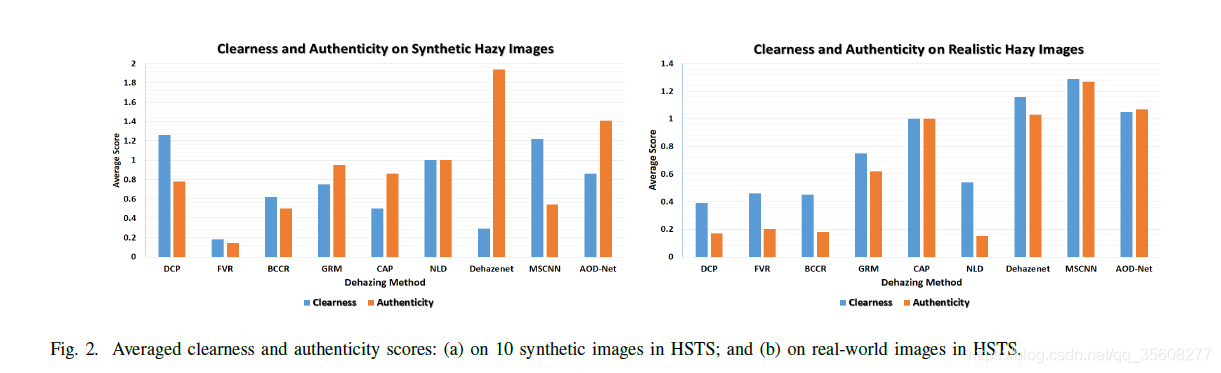
我們還計算合成影象的全參考和無參考指標,以檢查它們與主觀評分的一致性。