
GMAN 去霧
摘要 - 霧霾和煙霧是影響影象質量的最常見環境因素,因此也影響影象分析。 本文提出了一種影象去霧的端到端生成方法。 它基於設計完全卷積神經網路,以識別輸入影象中的霧霾結構,並恢復清晰,無霧的影象。 所提出的方法不探索大氣散射模型,一定意義上是不可知的。 有些令人驚訝的是,相對於所有現有的最先進的影象去霧方法,即使在使用大氣散射模型合成的SOTS室外影象上,它也能實現卓越的效能。
1 introduction
許多現代應用程式依賴於分析視覺化資料來發現模式並做出決策。 在智慧監視,跟蹤和控制系統中可以找到一些例子,其中高質量的影象或幀對於準確的結果和可靠的效能是必不可少的。 然而,這種系統可能受到環境引起的扭曲的顯著影響,其中最常見的是霧霾和煙霧。 因此,計算機視覺領域的許多研究致力於解決從朦朧對應物中恢復高質量影象的問題,[1],[2],[3],[4]等等。 這個問題通常被稱為dehaze問題。
原始影象和模糊影象[5]之間的關係近似通過以下稱為大氣散射模型的公式:
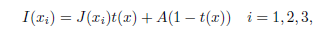
I(xi)是第i個通道的模糊畫素的強度,J(xi)是該畫素的實際強度,並且t(x)是取決於場景深度和大氣散射係數beta的介質傳輸函式。 等式(1)中的引數A是大氣光強度,其被假定為整個影象上的整體常數。 由於除了模糊畫素強度I(xi)之外,等式(1)中的所有變數都是未知的,因此除霧通常是未確定的問題。
去霧演算法大致分為基於傳統和機器學習(ML)的方法。
基於傳統的他們通過利用某種形式的先驗資訊來解決欠定問題。如1.3.6He_基於暗通道\顏色衰減先驗
另一方面,諸如[7],[2]dehazenet,[8]MSCNN和[9]AODNet之類的作品遵循基於學習的方法。 他們利用經典和深度學習技術的進步來解決dehaze問題。
無論這兩個類別看起來有多麼不同,
共性:
它們都旨在通過首先估計未知引數A和t(x)然後反轉等式(1)來確定J(xi)來恢復原始影象:
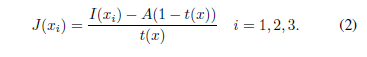
從估計理論的角度來看,兩類方法都屬於外掛原則1的範疇,它們都將被稱為外掛方法。

存在問題:
然而,對於dehaze問題,外掛原理的最優性並不完全合理。 實際上,至少當兩個問題受到相同的評估度量時,原始影象的有損重建問題不可能等效地轉換為引數A和t(x)(或它們的變體)的估計問題。(1.不可等效)
此外,原始影象和模糊影象之間的實際關係可能相當複雜,並且可能無法通過大氣散射模型完全捕獲。 (2是等效後難以完全表示)
由於這種潛在的不匹配,依賴於大氣散射模型(包括但不限於插入方法)的方法不能保證對自然影象的期望的推廣,即使它們可以在合成影象上實現良好效能。
提出:
基於前面提到的外掛方法(以及更一般地,依賴於模型的方法),本文從一個不同的,更不可知的角度來看待dehaze問題;它提供了一個dehaze神經網路,專注於生成輸入影象的無霧版本。它利用深度學習的最新進展來構建編碼器 - 解碼器網路架構,該架構經過訓練以直接恢復清晰影象,完全忽略引數估計問題。
所提出的方法具有識別訓練資料中存在的複雜霧結構的潛力,但不通過大氣散射模型捕獲。
據我們所知,這種除霧問題的觀點從未被探索過,除了最近的工作[10],其中引入了所謂的門控融合網路(GFN)用於影象去霧。可以看出,我們提出的網路比GFN有幾個優點,特別是在架構複雜性和輸入大小靈活性方面;此外,GFN的某些特徵是專門針對dehaze問題而定製的,而我們網路的架構更通用,因此更廣泛適用。
本文的其餘部分分為三個部分。
第2節,介紹了用於影象去霧的通用模型 - 不可知卷積神經網路(GMAN)以及網路體系結構及其構建塊的詳細說明。
第3節將介紹實驗結果,顯示GMAN的效能。 它還包括資料集和訓練過程的描述。
最後,第4節將結束本文的一些結論性意見。
2 方法
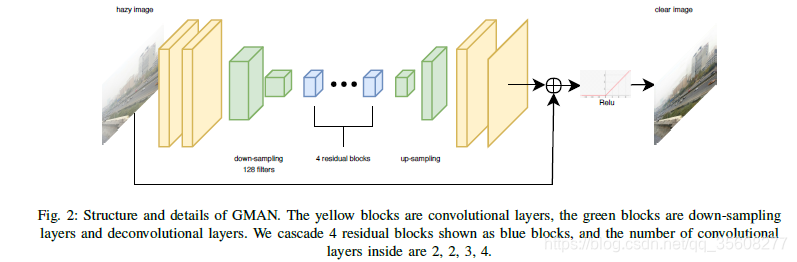
由於單個影象霧度去除是一個病態問題,因此設計並訓練基於卷積,殘差和去卷積塊的深度神經網路以呈現模糊影象並恢復其無霧度版本。 網路具有編碼器 - 解碼器結構,如圖2所示。在以下小節中,將更詳細地討論網路架構,其構建塊和訓練損失功能。
架構
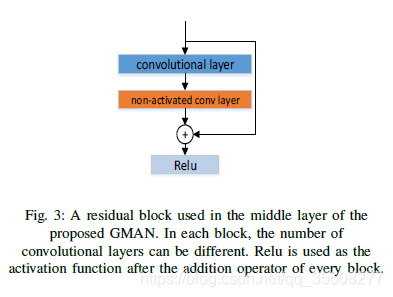
所提出的網路是完全卷積神經網路(CNN)。它用於從朦朧的輸入中恢復清晰的影象。從功能上講,它是一個端到端的生成網路,使用編碼器 - 解碼器結構,其下采樣因子為2,其前兩層由64通道卷積塊構成。接下來是兩步下采樣層,將輸入影象編碼為56 56 128卷。然後將編碼影象饋送到由4個殘差塊構建的殘差層,每個殘差塊包含快捷連線,參見圖3.
該層表示從編碼到解碼的轉換,因為它後面是反捲積層,其上取樣剩餘層輸出併為另一輪卷積重建新的224 224 64卷。最後兩層包括卷積塊。他們將上取樣特徵對映轉換為RGB影象,最終將其新增到輸入影象中並使用ReLU進行閾值處理以生成無霧模型。
殘差學習
該網路在本地和全域性兩個層面上使用剩餘學習。 在中間層並且恰好在下采樣之後,殘差塊用於構建區域性殘差層。 它利用了假設的和經驗證明的[11],[12],[13],[14]殘差塊的易於訓練的特性(見[15]),並學會識別霧霾結構。 殘差學習也出現在GMAN的整體架構中。 具體來說,輸入影象與最終卷積層的輸出一起饋送到求和運算子,建立一個全域性殘差塊,參見圖2.這個全域性殘差塊的主要優點是它有助於所提出的網路更好地捕獲 場景中具有不同深度的物件的邊界細節。
編解碼
所提出的GMAN的體系結構遵循在去噪問題中使用的流行的編碼器 - 解碼器體系結構。 它由三部分組成:編碼器,隱藏層和解碼器。 這種架構可以訓練深度網路並減少資料維度。 由於霧度可以被認為是一種噪聲形式,因此編碼器輸出被下采樣並饋送到殘餘層以提取重要特徵。 網路擠出原始影象的特徵並丟棄噪聲資訊。 期望解碼器部分學習並重新生成無霧影象的丟失資料,在解碼週期期間符合輸入資訊的統計分佈。
損失函式
為了訓練提出的GMAN,定義了雙損失函式。 第一個元件測量輸出和GT之間的相似性,第二個元件有助於產生視覺上有意義的影象。 以下三個小節提供了有關每個元件和總損失的更多資訊:
1)MSE損失:使用PSNR測量差異
在輸出影象和地面實況之間是顯示演算法有效性的最常用方法。 因此,選擇MSE作為損失函式的第一個分量,即LMSE。 通過最小化畫素級的MSE可以達到PSNR的最佳值,表示為:
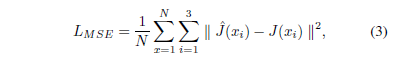
其中^ J(xi)是網路的輸出,J(xi)是gt,i是通道索引,N是畫素的總數。
2)感知損失:在許多經典影象恢復問題中,輸出影象的質量僅由MSE損失來測量。 然而,MSE損失不一定是視覺效果的良好指標。 正如Johnson等人。 在[16]中證明,從預訓練的神經網路的特定層中提取高階特徵可能對內容重建有益。 從高階特徵獲得的感知損失可以比畫素級損失更魯棒地描述兩個影象之間的差異。
新增感知損失元件使得GMAN的解碼器部分能夠獲得使用已經提取的特徵來生成目標影象的精細細節的改進能力。 在目前的工作中,網路輸出和基礎事實都被送到VGG16 [17]; 在[16]之後,我們使用從圖層conv11中提取的特徵圖;conv22; 將VGG16的conv33(將簡稱為第1,2,3層)定義感知損失Lp如下:
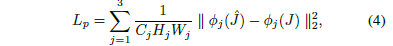
其中fai j(^ J)和fai j(J)分別是由網路輸出和GT引起的VGG16層j的特徵圖,Cj,Hj和Wj是VGG16層j的特徵體積的維數。
3)總損失:結合MSE和感知損失成分導致GMAN的總損失。 為了在兩個組成部分之間提供某種平衡,感知損失預先乘以LUMDA,產生以下表達式:
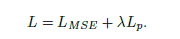
3 實驗
資料集
根據大氣散射模型,透射圖t(x)和大氣光強度A控制影象的霧度水平。因此,正確設定這兩個因素對於構建霧天影象的資料集非常重要。我們使用來自RESIDE [18]的OTS資料集,它是使用收集的真實世界室外場景構建的。整個資料集包含313,950個合成模糊影象,通過改變A的值和(使用[19]估計深度資訊)從8970個地面實況影象生成。因此,對於每個地面實況影象,存在35個對應的模糊影象。
我們注意到RESIDE的測試集SOTS有1000個地面實況影象,每個影象都有35個合成模糊對應物,它們都包含在訓練資料中。這肯定會導致測試結果出現一些不準確之處。因此,測試影象全部從訓練資料(包括他們的模糊對應物)中移除,導致尺寸減小的訓練資料集278,950個模糊影象(從7970地面真實影象生成)。
訓練
通過最小化等式(5)給出的損失L,對所提出的GMAN進行端對端訓練。 GMAN中的所有層都有64個濾波器(核心),除了具有128個濾波器的下采樣,大小為3*3.網路需要大小為224 224的輸入,因此訓練資料集中的每個影象都是隨機裁剪的 為了適應輸入大小3。 批量大小設定為35以平衡GPU上的訓練速度和記憶體消耗。 對於加速訓練,Adam optimizer [20]使用以下設定:
初始學習率為0.001,beta1 = 0.9,beta2 = 0.999。 該網路及其訓練流程已使用TensorFlow軟體框架實施,並在NVIDIA Titan Xp GPU上實施。 經過20個epoch後,損失函式下降到0.0004的值,這被認為是一個很好的停止點。
評估
與許多最先進的方法相比,GMAN實現了卓越的效能。 根據下面的表I 4,它明顯優於SOTS室外資料集[3],[2],[8],[9]所考慮的所有其他競爭方法。 而且,如圖4所示,GMAN避免使影象顏色變暗以及物體邊緣的過度銳化。 相反,從圖4可以看出,DCP方法[3]使去霧影象的光強度變暗,並且在高深度值區域(例如,天空)中引起顏色失真;
在這裡插入圖片描述
雖然MSCNN [8]在這些高深度值區域表現良好,但其效能在目標影象的中深度區域會降低。 因此,提出的GMAN可以克服許多這些問題併產生更好的無霧影象。
我們還在SOTS室內資料集上測試了我們的網路(見表II)。 在這種情況下,效能並不那麼令人印象深刻,並且在DehazeNet,GFN和AOD-Net之後排名第四。 儘管如此,即使在室內資料集上,人們仍然可以看到模型無關的dehaze方法的巨大希望。 事實上,同樣作為模式診斷網路家族的一員,GFN在PSNR方面排名第二,在SSIM方面排名第一(幾乎與排名靠前的DehazeNet並列)。 我們的初步結果表明,通過整合和概括GMAN、GFN的基礎和概念,可以設計一個更強大的模型無關網路,在SOTS室外和室內資料集上支配所有現有的網路(特別是那些基於外掛原理的網路)。 這一系列研究將在後續工作中報告。