
頻繁模式挖掘 Apriori 演算法簡介
本文主要介紹頻繁模式挖掘演算法,以及其典型的應用和Apriori演算法。
頻繁模式挖掘,相關性挖掘,關聯規則學習,Apriori演算法等等,這些看似不同但本質上一樣的概念一直以來被用於描述資料探勘的相關內容。所謂的資料探勘是指利用統計的方法從某個資料集中發現有價值的、未被人所知的規律。我們用分類或者聚類的方法,只是想挖掘資料集內各個子集的相互關係,尋找哪些事物經常同時出現,哪些事物相互依附,以及哪些事物存在聯絡。
因此,我們這個視角來理解資料探勘這個概念。在後文中,我將用頻繁模式挖掘來指代資料探勘這一概念,也有人喜歡稱為關聯挖掘。
購物籃分析
頻繁模式指的是在資料集中頻繁出現的一類模式。頻繁項集指的是由包含某一類頻繁模式的元素組成的集合。因此,頻繁模式挖掘也常被叫做頻繁項集挖掘。
購物籃分析(或是親密性分析)是介紹頻繁模式挖掘的最佳案例,它是眾所周知的頻繁模式挖掘應用之一。購物籃分析試圖從消費者加入購物籃的商品中挖掘出某種模式或者關聯,可以是真實的購物籃,也可以是虛擬的,並且給出支援度或是置信度。這一方法在使用者行為分析中存在巨大的價值。
將購物籃分析推而廣之就成了頻繁模式挖掘,實際上它與分類非常類似,只是通過相互的關聯來預測屬性或是屬性的組合(不僅僅是預測類別)。因為關聯不需要預標記類別標籤,所以它屬於非監督式學習。
置信度、支援度和關聯規則
如果我們把所有的物品都看作是我們集合中的一個元素(或是商店售賣的所有商品,或是用於欺詐檢測分析的所有交易記錄),那麼每個元素可以用一個布林值表示,表示該元素是否出現在某個特定的“籃子”裡。每個籃子就是一個布林值的向量,而向量的長度由集合的大小決定。所有可能的向量組成的矩陣就是一個數據集。
我們接下來就用這個布林向量集合來分析元素之間的關聯關係、相關關係和挖掘模式。表示這些模式的最常用的方法之一是通過關聯規則,其中的一個例子如下:
milk => bread [support = 25%, confidence = 60%]
我們怎麼知道一條規則的價值究竟有多少呢?這時候就需要用到支援度和置信度這兩個指標了。
支援度是度量模式或者物品成對出現的絕對次數。在上面的例子裡,25%的支援度表示牛奶和麵包被共同購買的次數佔到所有交易次數的25%。
置信度是度量模式或者物品成對出現的相對次數。在上面的例子裡,60%的置信度表示購買牛奶的客戶中,有60%的客戶同時也購買了麵包。
在一個給定的場景中,通常需要置信度和支援度都大於設定的閾值,這條關聯規則才能成立,這條規則才有利用價值。
Apriori
Apriori是最廣為人知的頻繁模式挖掘演算法。還是以購物籃分析為例,Apriori的資料集是一個巨大的稀疏矩陣,每一行是一單交易,每一列表示這單交易成交的若干個商品。
假設總共有n個商品,Apriori演算法首先生成一個候選商品列表長度是2~n-1。用組合的方式可以計算出所有可能的組合情況的個數:
C(n,n-(n+2)) + C(n,n-(n+3)) + … + C(n,n-1)
如果資料集非常龐大,那這個計算過程會很耗時。

演算法需要輸入最小支援度的閾值。首先,這個演算法生成一個候選集合的列表,包括了了資料集中可能出現的所有組合。候選集合生成後,如果其在交易記錄中出現的頻率大於閾值,則認為它是一個頻繁項集。

遍歷頻繁項集的集合可以很容易得到關聯規則及其置信度。置信度的計算公式如下:
Confidence(A=>B) = Support(AUB) / Support(A)
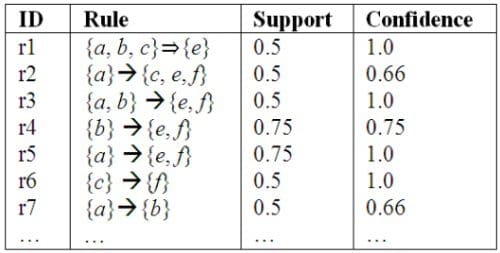
Apriori的演算法其實很簡單,就是找出所有滿足支援度和置信度最小閾值的規則。但是候選的集合會隨著商品數量的增加而呈指數式增長。
想了解人工智慧背後的那些人、技術和故事,歡迎關注人工智慧頭條:
