
圖片情感分析(2):影象情感分析模型
影象情感分析模型是基於卷積神經網路建立的,卷積神經網路的構建用了keras庫,具體程式碼實現以及程式碼執行在下一篇貼出。
模型包括3個卷積層、2個池化層、4個啟用函式層、2個Dropout層、2個全連線層、1個Flatten層和最終分類層。
圖片初始化是100*100大小,卷積層卷積核的個數都是32個,大小是13*13,經過三層卷積和兩層池化,每張圖片處理為4*4大小,經Flatten層壓扁成一維進入全連線層,第一個全連線層指定了128個神經元,進入Dropout層,目的是為了防止過擬合,當然在Flatten層之前還有一個Dropout層,最後是一個全連線層和一個分類層,啟用函式層伴隨著每一個卷積層之後和第一個全連線層之後。模型訓練迭代次數選擇13次。
具體實現過程如圖1所示:
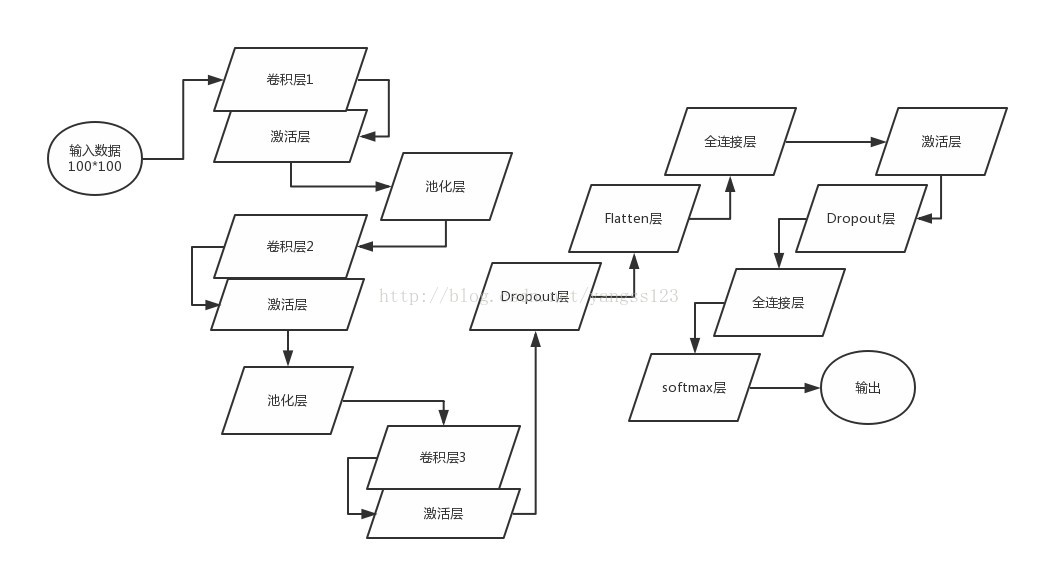
圖1 影象情感分析模型
建立模型
卷積層:主要是Convolution2D()函式。2D代表這是一個2維卷積,其功能為對2維輸入進行卷積計算。我們的影象資料尺寸為100 * 100,所以在這裡需要使用2維卷積函式計算卷積。所謂的卷積計算,其實就是利用卷積核逐個畫素、順序進行計算,簡化過程如圖2:

圖2 卷積計算
上圖中事例是保留邊界畫素演算法,也就是卷積過後和原影象大小一致,處理邊界值過程中,如果部分割槽域越界,就可以用0進行填充。計算過程中,將卷積核中心對準影象第一個畫素,在這裡就是畫素值為237的那個畫素。卷積核覆蓋的區域,其下所有畫素取均值然後相加:
C(1)= 0 * 0.5 + 0 * 0.5 + 0 * 0.5 + 0 *0.5 + 237 * 0.5 + 203 * 0.5 + 0 * 0.5 + 123 * 0.5 + 112 * 0.5
通過類似的計算,將計算結果作為原來畫素點處的特徵學習值,接著學習下一個卷積核中心覆蓋的畫素點,直到所有畫素點都被學習完。在這個過程中,卷積核依次覆蓋所有畫素點,最終結果還是得到一個二維矩陣,是學習過的影象。二維矩陣可以和原矩陣大小相同,也可以不相同,這取決於是否保留邊界,保留邊界的話會得到一個大小相同的矩陣影象,若丟掉邊界畫素,那麼在卷積過程中就會以卷積核覆蓋區域不越界的畫素開始計算。如圖3.8所示,如果選擇丟掉影象邊界特徵,卷積核就會從(2,2)畫素點開始卷積計算,到(3,3)畫素點結束計算,這樣得到的是一個2 * 2的矩陣表示的影象。在本次畢設的模型中,卷積層採用丟掉邊界特徵的方式來處理影象邊界:

第一個卷積層包含32個卷積核,每個卷積核大小為13 * 13, 值為“same”意味著我們採用保留邊界特徵的方式進行卷積計算,而值“valid”則代表丟掉邊界畫素。影象經過第一層卷積層,大小變為32* 88 * 88大小。
啟用函式層:以relu(Rectified Linear Units,修正線性單元)函式為例,它的數學形式如下:
f(x)=max(0,x)
這個函式非常簡單,小於0的輸入,輸出全部為0,大於0的則輸出與輸入相等。該函式的優點是收斂速度快,對於不同的需求,我們可以選擇不同的啟用函式,一般的啟用函式包括:softplus、softsign、tanh、sigmoid、hard_sigmoid、linear,啟用函式層屬於人工神經元的一部分,所以我們可以在構造層物件時通過傳遞activation引數設定。
池化層:可以縮小輸入的特徵圖,簡化網路計算複雜度,而且能夠進行特徵壓縮,突出主要特徵。我們通過呼叫MaxPooling2D()函式建立池化層,這個函式採用最大值池化法,這個方法選取覆蓋區域的最大值作為區域主要特徵組成新的縮小後的特徵圖,具體過程簡化後如圖3所示:

圖3 池化過程
池化層最重要的地方是可以降低維度,因為它是將最大值作為此學習範圍的輸出,所以能夠保留住此範圍裡的顯著特徵,雖然只能知道顯著特徵是什麼,卻得不到顯著特徵的發生位置,但很多問題不需要我們得到具體位置,只需要知道這一區域學習的最大特徵。由此池化層能夠為影象識別提供平移和旋轉不變性。即使影象平移或旋轉幾個畫素,得到的輸出值也基本一樣,因為每次最大值運算得到的結果總是一樣的。經過第一層池化層,圖片資料變為32* 44 * 44。採用maxpooling,poolsize為(2,2)。程式碼如下:
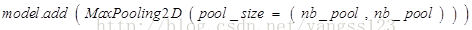
Dropout 層:隨機斷開一定百分比的輸入神經元連線,以防止過擬合。過擬合意思是訓練資料預測準確率很高,測試資料預測準確率很低,用圖形表示就是擬合曲線較尖,不平滑。導致這種現象的原因是模型的引數很多,但訓練樣本太少,導致模型擬合過度。為了解決這個問題,Dropout 層將隨機減少模型引數,讓模型變得簡單,而越簡單的模型越不容易產生過擬合。程式碼中Dropout ()函式只有一個輸入引數,即指定拋棄比率,範圍為0~1之間的浮點數,其實就是百分比。這個引數亦是一個可調引數,我們可以根據訓練結果調整它以達到更好的模型成熟度。本次模型中,比率選擇是0.5。
Flatten層:截止到Flatten層之前,在網路中流動的資料還是多維的(對於我們的程式就是2維的),經過多次的卷積、池化、 之後,到了這裡就可以進入全連線層做最後的處理了。全連線層要求輸入的資料必須是一維的,因此,我們必須把輸入資料“壓扁”成一維後才能進入全連線層,Flatten層的作用即在於此。
全連線層 :全連線層的作用就是用於分類或迴歸,對於我們來說就是分類。keras將全連線層定義為Dense層,其含義就是這裡的神經元連線非常“稠密”。我們通過Dense()函式來定義全連線層。這個函式的一個必填引數就是神經元個數,其實就是指定該層有多少個輸出。在我們的程式碼中,第一個全連線層指定了512個神經元,也就是保留了512個特徵輸出到下一層。新增512節點的全連線並且進行啟用,啟用函式用relu。再經過一層Dropout層,防止過擬合。新增輸出2個節點,經過softmax層,進行輸出。