
tensorflow之卷積池化和全連線
卷積:
當從一個大尺寸影象中隨機選取一小塊,比如說 8x8 作為樣本,並且從這個小塊樣本中學習到了一些特徵,這時我們可以把從這個 8x8 樣本中學習到的特徵作為探測器,應用到這個影象的任意地方中去。特別是,我們可以用從 8x8 樣本中所學習到的特徵跟原本的大尺寸影象作卷積,從而對這個大尺寸影象上的任一位置獲得一個不同特徵的啟用值。
下面給出一個具體的例子:假設你已經從一個 96x96 的影象中學習到了它的一個 8x8 的樣本所具有的特徵,假設這是由有 100 個隱含單元的自編碼完成的。為了得到卷積特徵,需要對 96x96 的影象的每個 8x8 的小塊影象區域都進行卷積運算。也就是說,抽取 8x8 的小塊區域,並且從起始座標開始依次標記為(1,1),(1,2),...,一直到(89,89),然後對抽取的區域逐個執行訓練過的稀疏自編碼來得到特徵的啟用值。在這個例子裡,顯然可以得到 100 個集合,每個集合含有 89x89 個卷積特徵。
如下圖所示,展示了一個3×3的卷積核在5×5的影象上做卷積的過程。每個卷積都是一種特徵提取方式,就像一個篩子,將影象中符合條件(啟用值越大越符合條件)的部分篩選出來。

2:說下池化,其實池化很容易理解,先看圖:
轉自: http://blog.csdn.net/silence1214/article/details/11809947
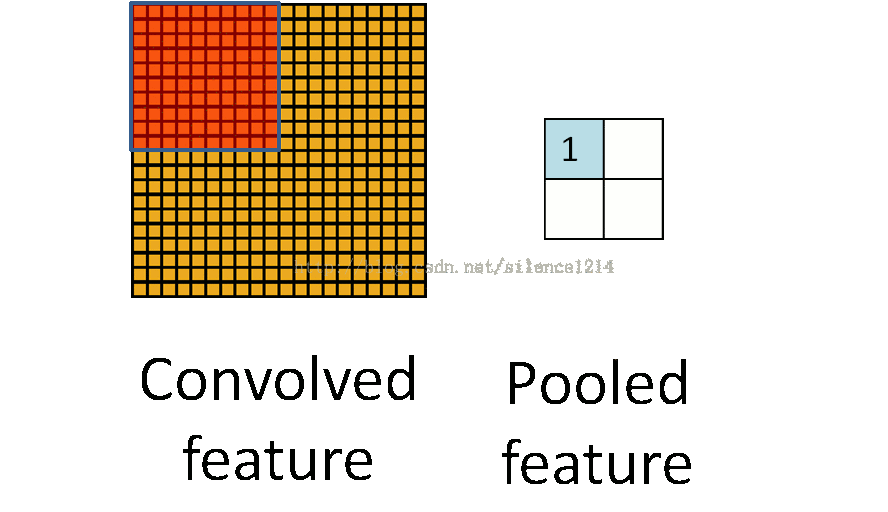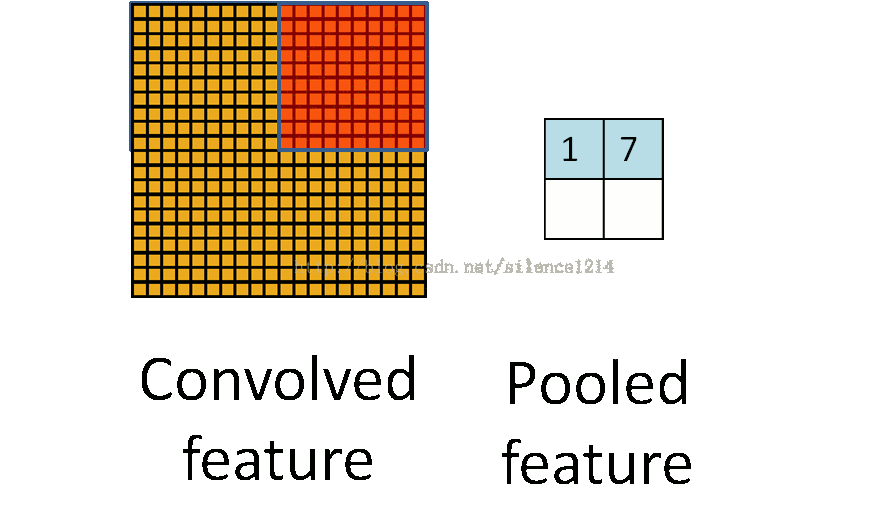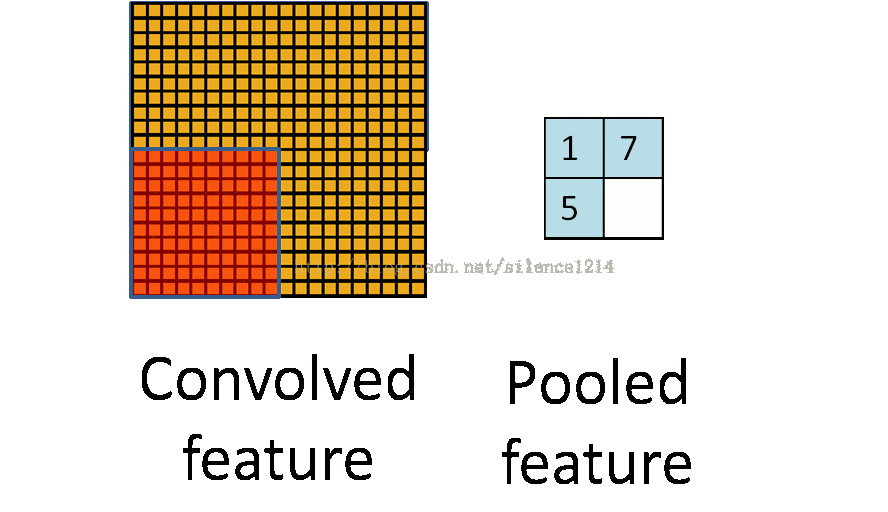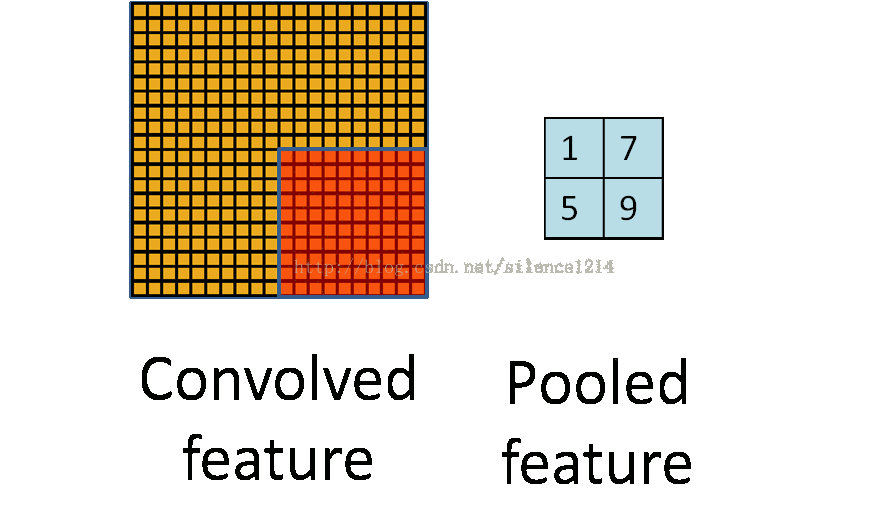
比如上方左側矩陣A是20*20的矩陣要進行大小為10*10的池化,那麼左側圖中的紅色就是10*10的大小,對應到右側的矩陣,右側每個元素的值,是左側紅色矩陣每個元素的值得和再處於紅色矩陣的元素個數,也就是平均值形式的池化。
3:上面說了下卷積和池化,再說下計算中需要注意到的。在程式碼中使用的是彩色圖,彩色圖有3個通道,那麼對於每一個通道來說要單獨進行卷積和池化,有一個地方尤其是進行卷積的時候要注意到,隱藏層的每一個值是對應到一幅圖的3個通道穿起來的,所以分3個通道進行卷積之後要加起來,正好才能對應到一個隱藏層的神經元上,也就是一個feature上去。