
Spark程式設計指南之四:Spark分散式叢集模式的執行時系統架構
文章目錄
官方叢集模式介紹
Spark官方網站http://spark.apache.org的Deploying選單下給出了叢集模式
的簡單介紹(可檢視
由SparkContext對接多種Cluster Managers(Standalone,Mesoscale或者YARN),用來分配資源。
分配資源後在叢集內啟動executors,SparkContext再將程式jar包傳送到各個Executor上,最後將task傳送到Executor上執行。如下圖:
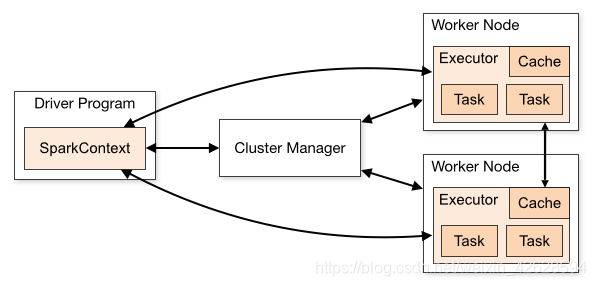
總體來說:Spark應用程式的執行架構由三部分組成:SparkContext、Cluster Manager、Executor。
1、SparkContext負責作業的全生命週期管理
2、Cluster Manager進行資源的分配和管理,不同模式下由不同的角色負責提供。在Local和Standalone模式下由Master提供;在YARN模式下由Resource Manager提供;在Mesos模式下由Mesos Manager提供。
3、Executor是每個應用程式的專屬程序,執行在自己的JVM中。
注:不同Spark程式資料不是共享的
Cluster Manager有哪些?
Standalone
– Spark自帶的簡單的叢集資源管理(a simple cluster manager included with Spark that makes it easy to set up a cluster.)
Apache Mesos
– 通用的可以跑MapReduce的叢集管理(a general cluster manager that can also run Hadoop MapReduce and service applications.)
Hadoop YARN
– Hadoop2的resource manager(the resource manager in Hadoop 2.)
Kubernetes
– 容器應用的開源管理器(an open-source system for automating deployment, scaling, and management of containerized applications.)
Standalone模式架構與作業執行流程
Standalone模式(獨立模式)是Spark自身實現的資源排程框架,由客戶端、Master節點和Worker節點組成。此模式下Master即為Cluster Manager。
SparkContext既可以執行在客戶端,也可以執行在Master。當使用Spark-Submit工具提交或在Eclipse、IDEA等開發平臺上執行作業時,SparkContext是執行在本地客戶端;當使用Spark-Shell互動式工具提交或使用run-example指令碼來執行時,SparkContext在Master節點執行。
排程過程可分為申請資源、分配資源、註冊、分配任務、執行任務幾個步驟。
申請資源
Spark應用程式從驅動程式Driver開始,Driver建立SparkContext來連線叢集並排程任務。
Driver會生成有向無環圖DAG,通過一定的優化,進行程式的規劃。
Driver向Master申請Executer資源
(其中的Driver程序,當用Client模式提交的時候,執行在Client的機器上。如果是叢集模式提交,執行在其中一臺Worker節點上。)
分配資源
Master向Driver返回資源
註冊
Executor向Driver進行註冊並申請Task
傳送任務
Driver的DAGScheduler解析作業並生成相應的Stage,每個Stage包含的Task通過TaskScheduler分配給Executor執行。
執行任務
Executor負責執行Task,並負責將資料存在記憶體或者磁碟上。
Executor會啟動執行緒池,啟動多個執行緒。
Executor在Worker節點上,獲取CPU和記憶體等計算資源,預設佔用所有CPU和記憶體。
參考連結
http://spark.apache.org/docs/latest/cluster-overview.html
http://spark.apache.org/docs/latest/submitting-applications.html
http://www.cnblogs.com/tgzhu/p/5818374.html