
臺大林軒田機器學習課程筆記2----機器學習的分類
阿新 • • 發佈:2018-12-31
1. 根據輸出集合
- 二分類
根據輸出空間,二分類的輸出結果只有兩種,即y={-1,1},具體的應用包括:
*信用卡申請問題:Client Data=>Accept or Deny
郵件分類問題:Email Text=>Rubbish or Not
病人生病問題:Patients Data=>Sick or Not*
還有一些其他的應用,例如廣告是否盈利、答題系統對錯等。 - 多元分類
多元分類的輸出結果包括多種,例如飲料售賣機識別硬幣問題,根據尺寸和重量可以將硬幣分為四類,即最終的輸出空間為y={1c,5c,10c,25c}(這裡是用美金來舉例,單位為美分)。二分類是特殊的多元分類問題,多元分類問題的輸出空間可以擴充套件到y={1,2,3,……..k}。
多元分類主要應用在識別問題上。例如數字識別問題,即可以根據輸入的數字1~9的特徵(對稱性、密度)可以將數字分為9類,最終的結果為y={1,2,….,9}。還有包括圖片區分、郵件多分類問題以及其它辨識(聲音、視覺)等應用。 - 迴歸
迴歸主要是用來解決預測問題。例如預測病人的病情多久可以恢復、預測股票的價格變動趨勢、預測天氣的變化等。其輸出空間為y=R or y={lower,upper}。 - 結構學習
結構學習其實可以看作一個大的多元分類問題,只不過由於最終的分類結果太多而無法窮舉。例如自然語言的識別問題,拿一句話作為示例,“I(P) love(V) ML(N)”,如果是逐詞輸入到分類器,自然可以根據一些特徵判斷出該詞的詞性。而如果是將整個句子扔到分類器,則最終輸出的結果空間可能為{PVN,PVP,NVN……}。結構學習是有趣而複雜的。
2.根據資料標記分類
- 監督學習(Supervised Learning)
監督學習就是將所有的資料進行標記,即對每個有效的輸入,都會有一個明確的輸出與之對應(x(i)->y(i))。例如上述提到的硬幣識別問題,監督學習類似於老師教學生根據這些硬幣的特徵去給出沒個硬幣是什麼,通過這些標記的資料給出目標函式g,並根據g去標記未標記的資料。監督學習是最常見的學習方式。 - 非監督學習(Unsupervised Learning)
與監督學習恰恰相反,非監督學習的所有輸入都沒有標記,都是依靠機器自己想辦法,又被稱為聚類問題。例如根據文章去劃分主題(articles=>topics)、根據客戶檔案劃分客戶群(consumer profiles=>consumer groups)等都是在未給出輸入標記的情況下進行類別劃分。
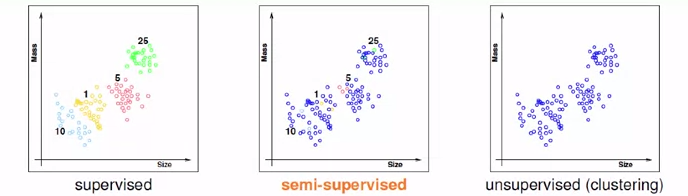
上圖描述的是硬幣分類問題,第一張圖表示的是已經分好類的硬幣,即屬於監督學習的範疇,第二張圖表示的是機器自動進行分類的結果,也就是利用的非監督學習演算法。我們可以看到,非監督式的分類明顯是有錯誤的,所以非監督學習目標分散、難以衡量。我們將非監督學習類問題定位為有挑戰但是非常有用的問題。
非監督學習主要應用在分群問題,密度估算,異常探測等問題上.
分群問題:clustering{x(n)} -> cluster(x)。例如輸入文章內容劃分文章主題。
密度估算:traffic recording{x(n)} -> density(x)。例如輸入交通肇事記錄,確定事故高發地。
異常探測:network log{x(n)} -> unusual(x)。例如輸入網路日誌,找到系統異常。 - 半監督式學習(Semi-supervised Learning)
如上圖,半監督式學習就是給出一部分資料進行標記,而另外的資料需要機器來完成分類。例如根據一些有標記的照片以及無標記的照片來進行面部識別,再比如根據一部分有標記的藥品資料來進行藥效測試。半監督式學習的特點就是由於找到標記很貴,所以採用大量的非標記的資料避免這些貴的標記。 - 增強式學習(Reinforcement Learning)
類似於(x,y’,goodness)的形式,對於輸入x,沒有明確的標記y與之對應,取而代之的是輔助式的y’,即根據x所做出的反應,如果反應正確,則會給出獎勵,反應錯誤則會給出懲罰。這就像是在訓練一隻狗,如果狗的動作達到主人的要求,則給予獎勵,如果未達到,則給予懲罰。再舉兩個例子:
(consumer,ad choice,ad click earning)=>ad system:在廣告系統中,根據客戶的資料和廣告選擇以及最終的點選率來進行學習。
(cards,strategy,winning amount)=>black jack agent:在21點遊戲中,根據紙牌點數和相關的策略以及贏得的獎勵來進行學習。


3根據學習演算法分類
- 批量學習(Batch Learning)
即對大量的有標記的資料進行分類的問題。 - 有序學習(Sequence Learning)
與批量學習不同,有序學習是將資料按順序逐一放入機器,例如垃圾郵件過濾器,首先需要觀察該郵件X(i),然後使用目標函式g來預測該郵件是否為垃圾郵件,最後受到使用者反饋,利用(X(i),Y(i))來更新g。 - 主動學習(Active Learning)
即通過有策略的提問進行學習以改善目標函式g,例如選擇一個X(i),然後提問監督者對應的Y(i)。
4根據輸入集合
- 具體的特徵(concrete feature)
例如輸入集合為銀行客戶的年齡、性別、年收入等可以具體識別的特徵。 - 原始特徵(raw feature)
即機器所能夠識別的最原始的特徵,例如輸入影象資料,機器只能識別影象每個畫素點的灰色值,這就是影象所包含的最原始的特徵。所以我們需要將這些原始特徵轉化為具有實際意義的特徵。 - 抽象特徵(abstract feature)
例如線上評論系統的學生ID,可以根據該ID搜尋到該學生的年齡、性別等其它大量的資訊,當然前提是有資料庫完備的資料可以支撐。
參考資料:
Coursera臺大機器學習基石