
CS231n課程筆記2:線性分類上
內容列表:
- 線性分類器簡介
- 線性評分函式
- 闡明線性分類器
線性分類
上一篇筆記介紹了影象分類問題。影象分類的任務,就是從已有的固定分類標籤集合中選擇一個並分配給一張影象。我們還介紹了k-Nearest Neighbor (k-NN)分類器,該分類器的基本思想是通過將測試影象與訓練集帶標籤的影象進行比較,來給測試影象打上分類標籤。k-Nearest Neighbor分類器存在以下不足:
- 分類器必須記住所有訓練資料並將其儲存起來,以便於未來測試資料用於比較。這在儲存空間上是低效的,資料集的大小很容易就以GB計。
- 對一個測試影象進行分類需要和所有訓練影象作比較,演算法計算資源耗費高。
概述:我們將要實現一種更強大的方法來解決影象分類問題,該方法可以自然地延伸到神經網路和卷積神經網路上。這種方法主要有兩部分組成:一個是評分函式(score function),它是原始影象資料到類別分值的對映。另一個是損失函式(loss function),它是用來量化預測分類標籤的得分與真實標籤之間一致性的。該方法可轉化為一個最優化問題,在最優化過程中,將通過更新評分函式的引數來最小化損失函式值。
從影象到標籤分值的引數化對映
該方法的第一部分就是定義一個評分函式,這個函式將影象的畫素值對映為各個分類類別的得分,得分高低代表影象屬於該類別的可能性高低。下面會利用一個具體例子來展示該方法。現在假設有一個包含很多影象的訓練集
舉例來說,在CIFAR-10中,我們有一個N=50000的訓練集,每個影象有D=32x32x3=3072個畫素,而K=10,這是因為圖片被分為10個不同的類別(狗,貓,汽車等)。我們現在定義評分函式為:,該函式是原始影象畫素到分類分值的對映。
線性分類器:在本模型中,我們從最簡單的概率函式開始,一個線性對映:
在上面的公式中,假設每個影象資料都被拉長為一個長度為D的列向量,大小為[D x 1]。其中大小為[K x D]的矩陣W和大小為[K x 1]列向量b為該函式的引數(parameters
需要注意的幾點:
- 首先,一個單獨的矩陣乘法
就高效地並行評估10個不同的分類器(每個分類器針對一個分類),其中每個類的分類器就是W的一個行向量。
- 注意我們認為輸入資料
是給定且不可改變的,但引數W和b是可控制改變的。我們的目標就是通過設定這些引數,使得計算出來的分類分值情況和訓練集中影象資料的真實類別標籤相符。在接下來的課程中,我們將詳細介紹如何做到這一點,但是目前只需要直觀地讓正確分類的分值比錯誤分類的分值高即可。
- 該方法的一個優勢是訓練資料是用來學習到引數W和b的,一旦訓練完成,訓練資料就可以丟棄,留下學習到的引數即可。這是因為一個測試影象可以簡單地輸入函式,並基於計算出的分類分值來進行分類。
- 最後,注意只需要做一個矩陣乘法和一個矩陣加法就能對一個測試資料分類,這比k-NN中將測試影象和所有訓練資料做比較的方法快多了。
預告:卷積神經網路對映影象畫素值到分類分值的方法和上面一樣,但是對映(f)就要複雜多了,其包含的引數也更多。
理解線性分類器
線性分類器計算影象中3個顏色通道中所有畫素的值與權重的矩陣乘,從而得到分類分值。根據我們對權重設定的值,對於影象中的某些位置的某些顏色,函式表現出喜好或者厭惡(根據每個權重的符號而定)。舉個例子,可以想象“船”分類就是被大量的藍色所包圍(對應的就是水)。那麼“船”分類器在藍色通道上的權重就有很多的正權重(它們的出現提高了“船”分類的分值),而在綠色和紅色通道上的權重為負的就比較多(它們的出現降低了“船”分類的分值)。————————————————————————————————————————

一個將影象對映到分類分值的例子。為了便於視覺化,假設影象只有4個畫素(都是黑白畫素,這裡不考慮RGB通道),有3個分類(紅色代表貓,綠色代表狗,藍色代表船,注意,這裡的紅、綠和藍3種顏色僅代表分類,和RGB通道沒有關係)。首先將影象畫素拉伸為一個列向量,與W進行矩陣乘,然後得到各個分類的分值。需要注意的是,這個W一點也不好:貓分類的分值非常低。從上圖來看,演算法倒是覺得這個影象是一隻狗。————————————————————————————————————————
將影象看做高維度的點:既然影象被伸展成為了一個高維度的列向量,那麼我們可以把影象看做這個高維度空間中的一個點(即每張影象是3072維空間中的一個點)。整個資料集就是一個點的集合,每個點都帶有1個分類標籤。
既然定義每個分類類別的分值是權重和影象的矩陣乘,那麼每個分類類別的分數就是這個空間中的一個線性函式的函式值。我們沒辦法視覺化3072維空間中的線性函式,但假設把這些維度擠壓到二維,那麼就可以看看這些分類器在做什麼了:
——————————————————————————————————————————

影象空間的示意圖。其中每個影象是一個點,有3個分類器。以紅色的汽車分類器為例,紅線表示空間中汽車分類分數為0的點的集合,紅色的箭頭表示分值上升的方向。所有紅線右邊的點的分數值均為正,且線性升高。紅線左邊的點分值為負,且線性降低。
從上面可以看到,W的每一行都是一個分類類別的分類器。對於這些數字的幾何解釋是:如果改變其中一行的數字,會看見分類器在空間中對應的直線開始向著不同方向旋轉。而偏差b,則允許分類器對應的直線平移。需要注意的是,如果沒有偏差,無論權重如何,在時分類分值始終為0。這樣所有分類器的線都不得不穿過原點。
將線性分類器看做模板匹配:關於權重W的另一個解釋是它的每一行對應著一個分類的模板(有時候也叫作原型)。一張影象對應不同分類的得分,是通過使用內積(也叫點積)來比較影象和模板,然後找到和哪個模板最相似。從這個角度來看,線性分類器就是在利用學習到的模板,針對影象做模板匹配。從另一個角度來看,可以認為還是在高效地使用k-NN,不同的是我們沒有使用所有的訓練集的影象來比較,而是每個類別只用了一張圖片(這張圖片是我們學習到的,而不是訓練集中的某一張),而且我們會使用(負)內積來計算向量間的距離,而不是使用L1或者L2距離。
將課程進度快進一點。這裡展示的是以CIFAR-10為訓練集,學習結束後的權重的例子。注意,船的模板如期望的那樣有很多藍色畫素。如果影象是一艘船行駛在大海上,那麼這個模板利用內積計算影象將給出很高的分數。
可以看到馬的模板看起來似乎是兩個頭的馬,這是因為訓練集中的馬的影象中馬頭朝向各有左右造成的。線性分類器將這兩種情況融合到一起了。類似的,汽車的模板看起來也是將幾個不同的模型融合到了一個模板中,並以此來分辨不同方向不同顏色的汽車。這個模板上的車是紅色的,這是因為CIFAR-10中訓練集的車大多是紅色的。線性分類器對於不同顏色的車的分類能力是很弱的,但是後面可以看到神經網路是可以完成這一任務的。神經網路可以在它的隱藏層中實現中間神經元來探測不同種類的車(比如綠色車頭向左,藍色車頭向前等)。而下一層的神經元通過計算不同的汽車探測器的權重和,將這些合併為一個更精確的汽車分類分值。
偏差和權重的合併技巧:在進一步學習前,要提一下這個經常使用的技巧。它能夠將我們常用的引數和
合二為一。回憶一下,分類評分函式定義為:
分開處理這兩個引數(權重引數和偏差引數
)有點笨拙,一般常用的方法是把兩個引數放到同一個矩陣中,同時
向量就要增加一個維度,這個維度的數值是常量1,這就是預設的偏差維度。這樣新的公式就簡化成下面這樣:
還是以CIFAR-10為例,那麼
的大小就變成[3073x1],而不是[3072x1]了,多出了包含常量1的1個維度)。W大小就是[10x3073]了。
中多出來的這一列對應的就是偏差值
,具體見下圖:
————————————————————————————————————————
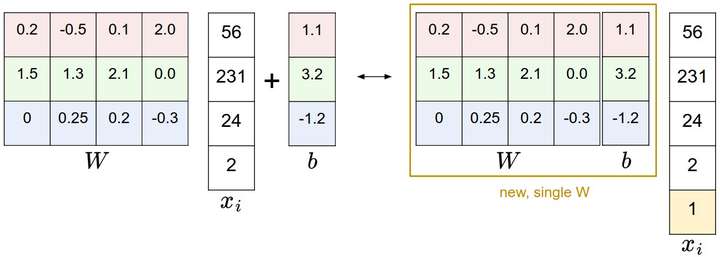

偏差技巧的示意圖。左邊是先做矩陣乘法然後做加法,右邊是將所有輸入向量的維度增加1個含常量1的維度,並且在權重矩陣中增加一個偏差列,最後做一個矩陣乘法即可。左右是等價的。通過右邊這樣做,我們就只需要學習一個權重矩陣,而不用去學習兩個分別裝著權重和偏差的矩陣了。
影象資料預處理:在上面的例子中,所有影象都是使用的原始畫素值(從0到255)。在機器學習中,對於輸入的特徵做歸一化(normalization)處理是常見的套路。而在影象分類的例子中,影象上的每個畫素可以看做一個特徵。在實踐中,對每個特徵減去平均值來中心化資料是非常重要的。在這些圖片的例子中,該步驟意味著根據訓練集中所有的影象計算出一個平均影象值,然後每個影象都減去這個平均值,這樣影象的畫素值就大約分佈在[-127, 127]之間了。下一個常見步驟是,讓所有數值分佈的區間變為[-1, 1]。零均值的中心化是很重要的,等我們理解了梯度下降後再來詳細解釋。
問題:
1.引數如何確定?
2.圖片的畫素資料如何預處理?