
python爬蟲——美團美食店鋪資訊
阿新 • • 發佈:2018-12-31
寫在前面
本篇文章主要介紹美團美食頁面爬取(web版)
整體思路
通過分析,我們發現美團美食的資料是通過ajax請求來的。
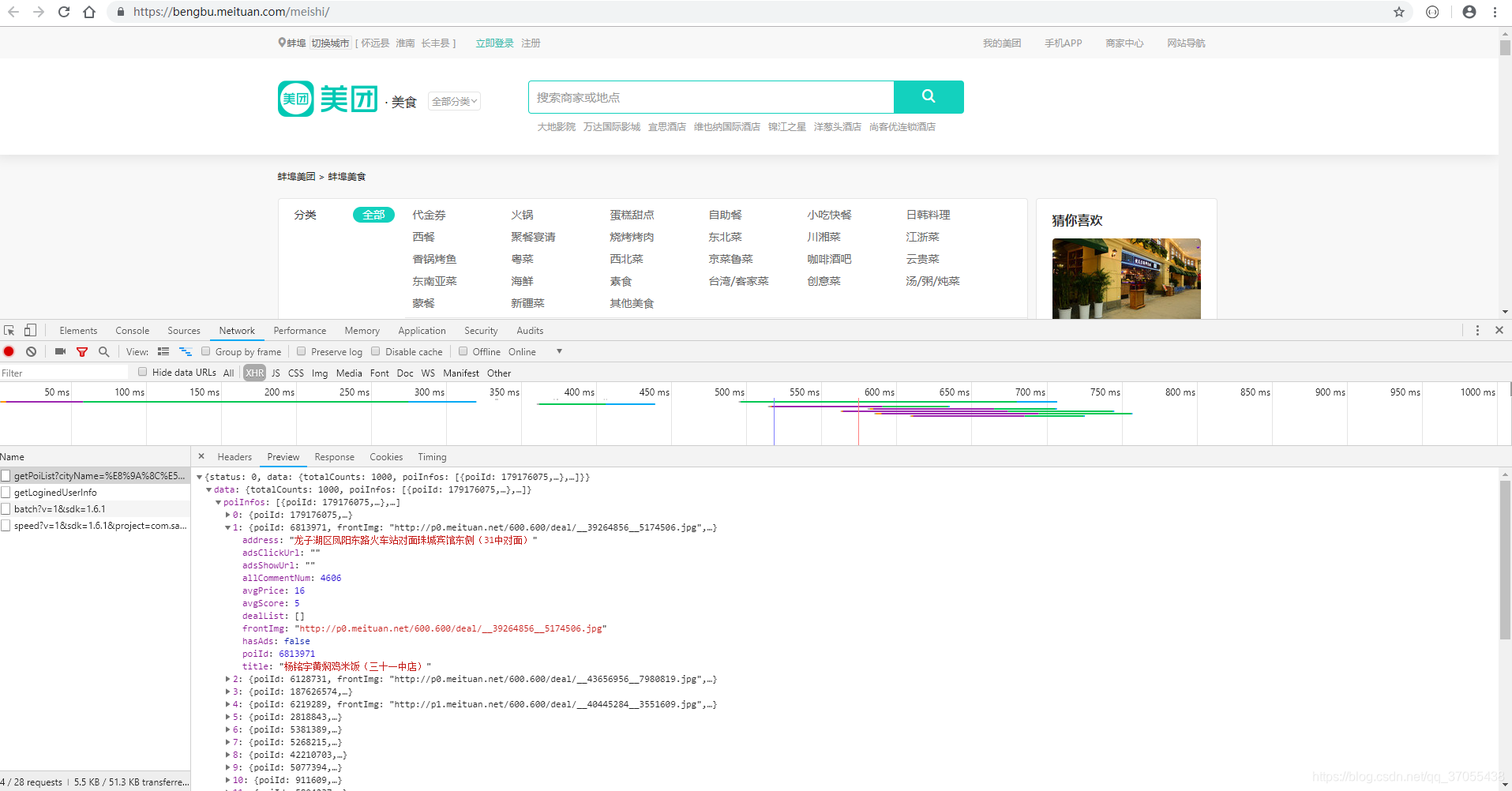
所以接下來,我們只需要請求這個介面就行了。分析下這個介面的request-header。發現有一點複雜欸(別慌,馬上告訴你答案)
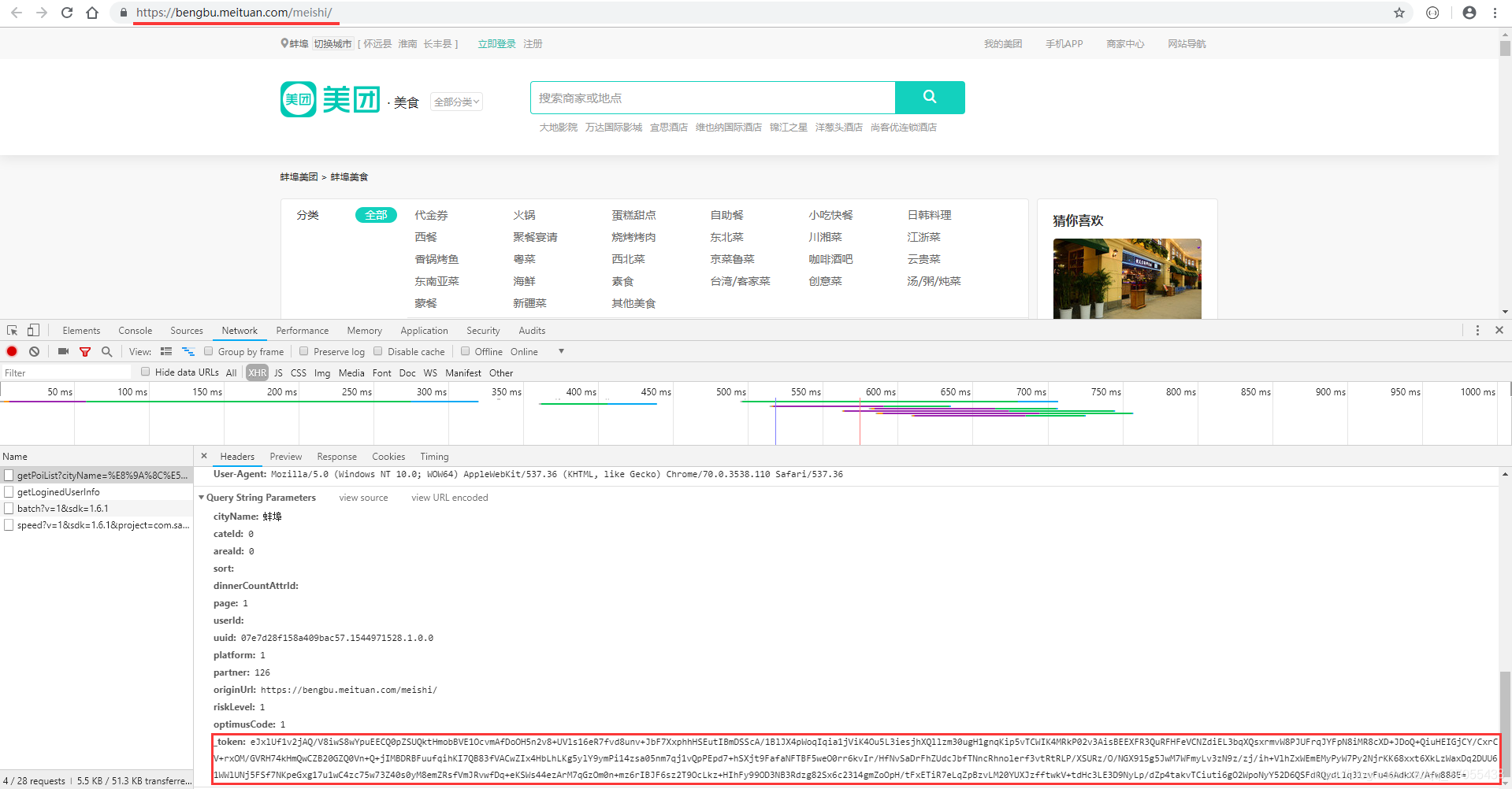
說一下圖片中我標記的地方
- url 欄裡面的地址可以在城市切換頁面爬取到(
這個很簡單) - 主要是token是加密的
- token是先用的
zlib加密,然後再base64加密(通過看加密字元型別和字元長度可以大概推斷是哪種加密),當然,解密也就是反著來啦。對了,token解密后里面還有個sign引數,也是用的同樣的加密方式。
- token是先用的
我把token拿出來大概做個示範,你一看就懂了

拿到解密後的token,整個ajax請求在你面前可以算是透明的了,接下來就是自己造token然後請求api拿到商家資訊了
程式碼參考
下面附上我寫的程式碼(防反爬還沒怎麼寫,但用上隨機ua頭和代理應該還行)
from requests import RequestException
from fake_useragent import UserAgent
from lxml.html import etree
import base64, zlib, json
import