
Python爬蟲之實習僧招聘資訊及資料分析
真皮沙發這次又來了!在上次的兩個爬蟲中,筆者探討了python爬蟲的入門以及re模組的運用。而上兩次的爬取內容都是筆者閒的蛋疼入門爬蟲所選擇的連個爬取頁面。
今天筆者要來搞事了,這次是搞正事。是的,搞正事。相信很多的同學都有在各大招聘網站上瀏覽過,各種層出不起的資訊,著實讓人厭煩。很多人也在著急尋找實習單位為以後找工作打好基礎,筆者本著服務於人的態度爬取了一個實習生招聘網站-實習僧,因為筆者在武漢就讀,就爬取了100頁武漢本地的實習單位資訊。通過所得到的資料分析了一下實習生的工資待遇,就筆者目前所得到的結果來看,整體就一個慘字啊!
哇,一個偌大的武漢對待實習生也太差了吧,真的是讓人心寒。這裡筆者先買個關子,等會和大家一起看分析結果。那麼現在我們進入正題,首先我們要將資訊爬取下來,這需要一個爬蟲框架,這裡便不多累述,前兩篇都有。而後我們將爬取得到的資料存入資料庫,這裡用到的是MongoDB,不得不說這個C++開發的資料庫效率還是很高的,資料的儲存方式與知名的關係資料庫大相徑庭,但卻顯得十分有個性。接下來我們便要用到讚譽極高的jupyter notebook來進行資料分許了,對於資料的視覺化筆者用的是charts這個第三方庫,當然你也可以用matplotlib這個神奇的庫。
我們先來看一看本次爬取的頁面:
說個實話筆者覺得這個實習僧網面簡直不要太友好,類容簡介又好看,爬蟲又好爬,著實讓筆者偷了很多懶。關於爬蟲這一塊,感興趣的可以看一下筆者前兩遍文章或者去查詢一下資料。這裡我先上我的程式碼:
import requests from bs4 import BeautifulSoup import re import pymongo def get_one_page(url): wb_data = requests.get(url) if wb_data.status_code == 200: return wb_data.text else: return None def parse_one_page(response): soup = BeautifulSoup(response, 'lxml') datas = soup.select('div#load_box div.jib_inf div.job_inf_inf') pattern = re.compile( r'<div.*?<h3>(.*?)</h3>.*?<a class="company_name".*?title="(.*?)">.*?<i class="money"></i>(.*?)</span>.*?<i class="days"></i>(.*?)</span>.*?</div>', re.S) wants = [] for item in datas: final = re.findall(pattern, str(item)) # print(final[0]) wants.append(final[0]) return wants def get_all_page(): client=pymongo.MongoClient('localhost',27017) db=client['shixi'] item=db['db'] for i in range(1, 101): url = 'http://www.shixiseng.com/interns?k=&c=%E6%AD%A6%E6%B1%89&s=0,0&d=&m=&x=&t=zh&ch=&p=' + str( i) response = get_one_page(url) wants = parse_one_page(response) for want in wants: data = { '職位': want[0], '公司': want[1], '薪資': want[2], '要求': want[3] } print(data) item.insert_one(data) if __name__ == '__main__': get_all_page()
整篇程式碼的思想便是先得到每一頁網頁的資料,然後從中抓取資料資訊,然後跳轉頁面直至得到100頁的全部資料,將其寫入mongdb資料庫中。
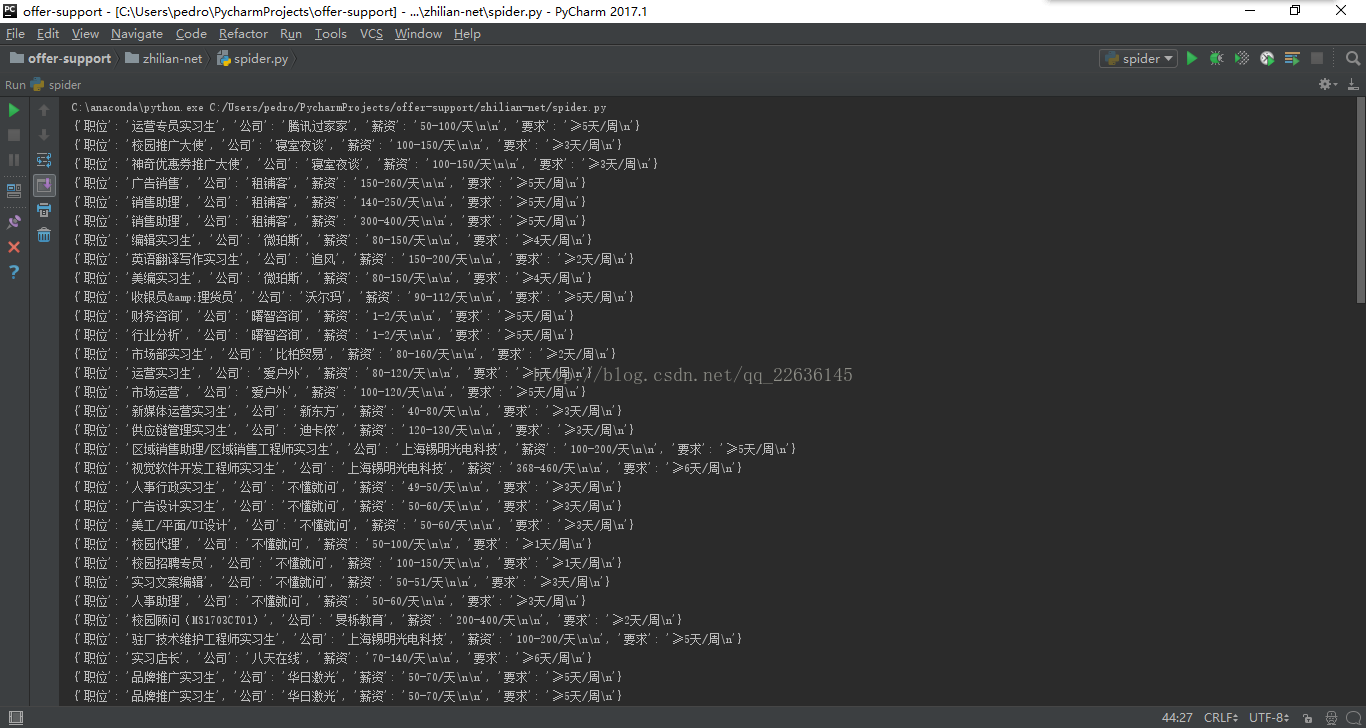
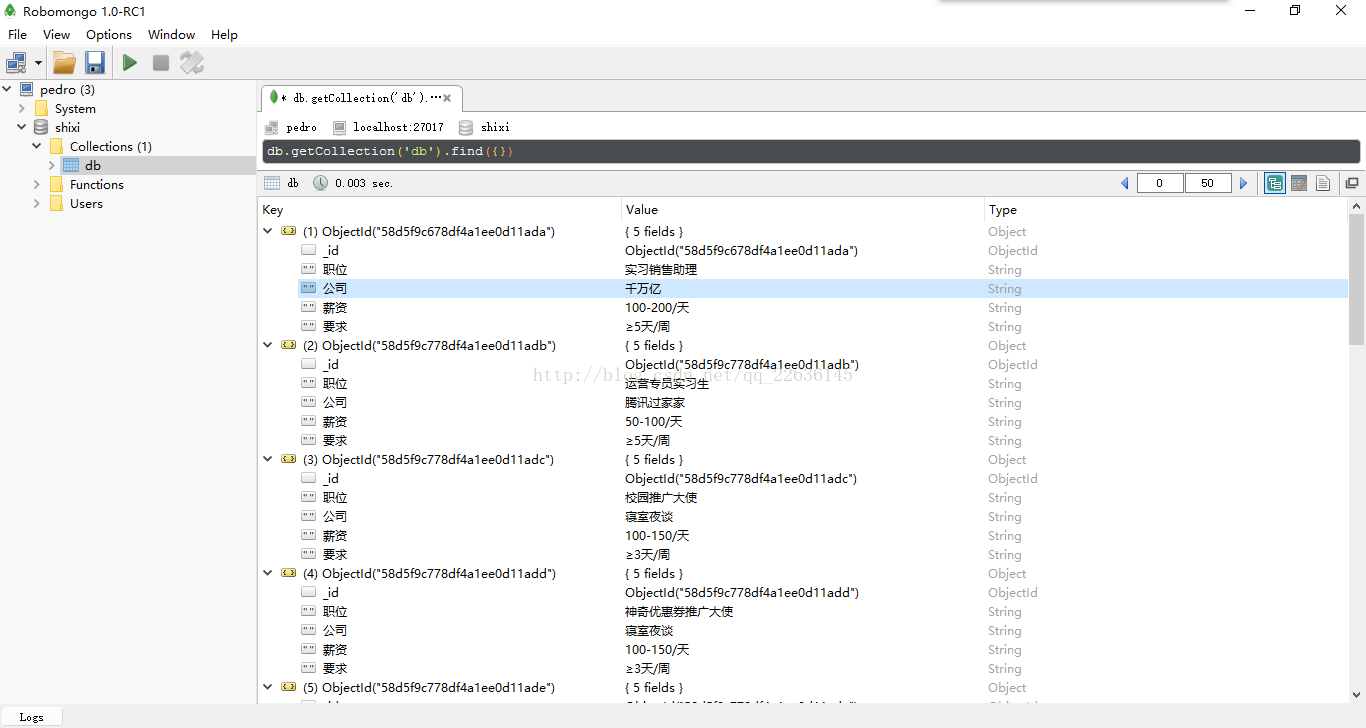
上圖顯示的便是爬下來的資料和存在資料庫中的資訊,資訊共有1000條,總體能反映出武漢實習生的基本待遇情況。接下來我們便要進行資料分析了:
client=pymongo.MongoClient('localhost',27017) db=client['shixi'] item=db['db'] low=0 medium=0 high=0 shigh=0 noknow=0 for i in item.find(): score=i['薪資'].strip().split('-')[0] if score=='面議': noknow=noknow+1 else: grade=int(score) if grade<=50: low=low+1 elif grade>50&grade<=100: medium=medium+1 elif grade>100&grade<=200: high=high+1 elif grade>200: shigh=shigh+1 print(low,medium,high,shigh,noknow)
我們從每條資料中得到‘薪資’這一項的類容並對它進行處理得到具體的薪資數值,其中主要運用到了python中string模組的strip()和split()方法。不知道的同學們可以去網上查閱一下相關資料。總之python很方便,方便到不行。

上面圖片的底部便是這次統計所得到的統計結果,可以看到實習生的待遇是多麼多麼多麼的差強人意。得到這些資料之後便要讓它視覺化。
series = [
{
'name': '極低薪資',
'data': [low],
'type': 'column'
}, {
'name': '低薪資',
'data': [medium],
'type': 'column',
'color':'#ff0066'
}, {
'name': '中等薪資',
'data': [high],
'type': 'column'
}, {
'name': '高薪資',
'data': [shigh],
'type': 'column'
},{
'name': '面議',
'data': [noknow],
'type': 'column'
}
]
charts.plot(series, show='inline',options=dict(title=dict(text='實習薪資分佈圖')))上面的程式碼便是其所用的python程式碼,一般這樣的東西都很死,這個時候必須得用API。感興趣的可以去查閱相關的API,一般都是英文的,就很氣。泱泱華夏,巍巍中華什麼就沒有一個像樣的第三方庫。哎!
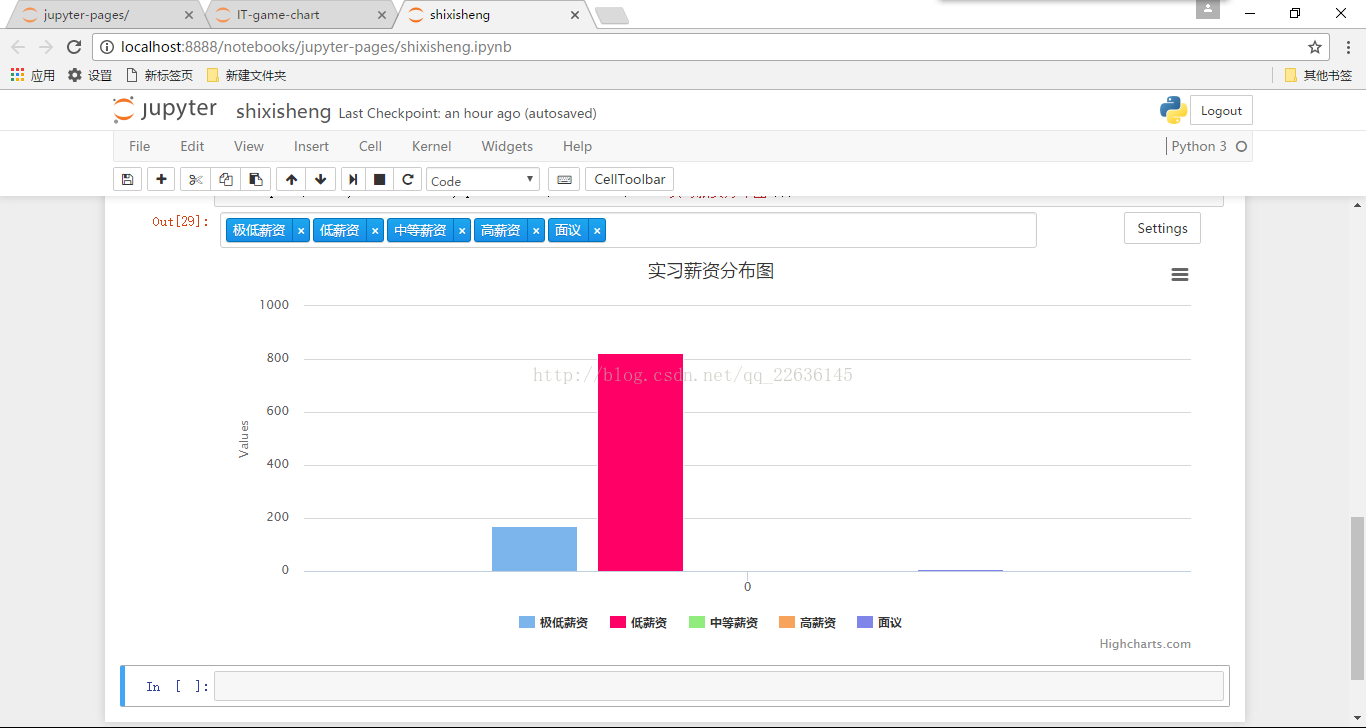
現在資料結果可以說是一目瞭然。寫到這裡本次的爬蟲和簡單的資料分析及視覺化便要走入尾聲了,希望這篇文章能給想學習python的同學們一點指導,如果你是高手希望你不吝賜教。