
深度模型調參
注意
- 調參看驗證集。trainset loss通常能夠一直降低,但validation set loss在經過一段降低期後會開始逐漸上升,此時模型開始在訓練集上過擬合。
- 著重關注val loss變化,val acc可能會突變,但loss衡量的整體目標。
- 優先調參學習率。
- 通過對模型預測結果,可以判斷模型的學習程度,如果softmax輸出在0或1邊緣說明還不錯,如果在0.5邊緣說明模型有待提高。
- 調參只是為了尋找合適的引數。一般在小資料集上合適的引數,在大資料集上效果也不會太差。因此可以嘗試取樣部分資料集,以提高速度,在有限的時間內可以嘗試更多引數。
學習率(重要)
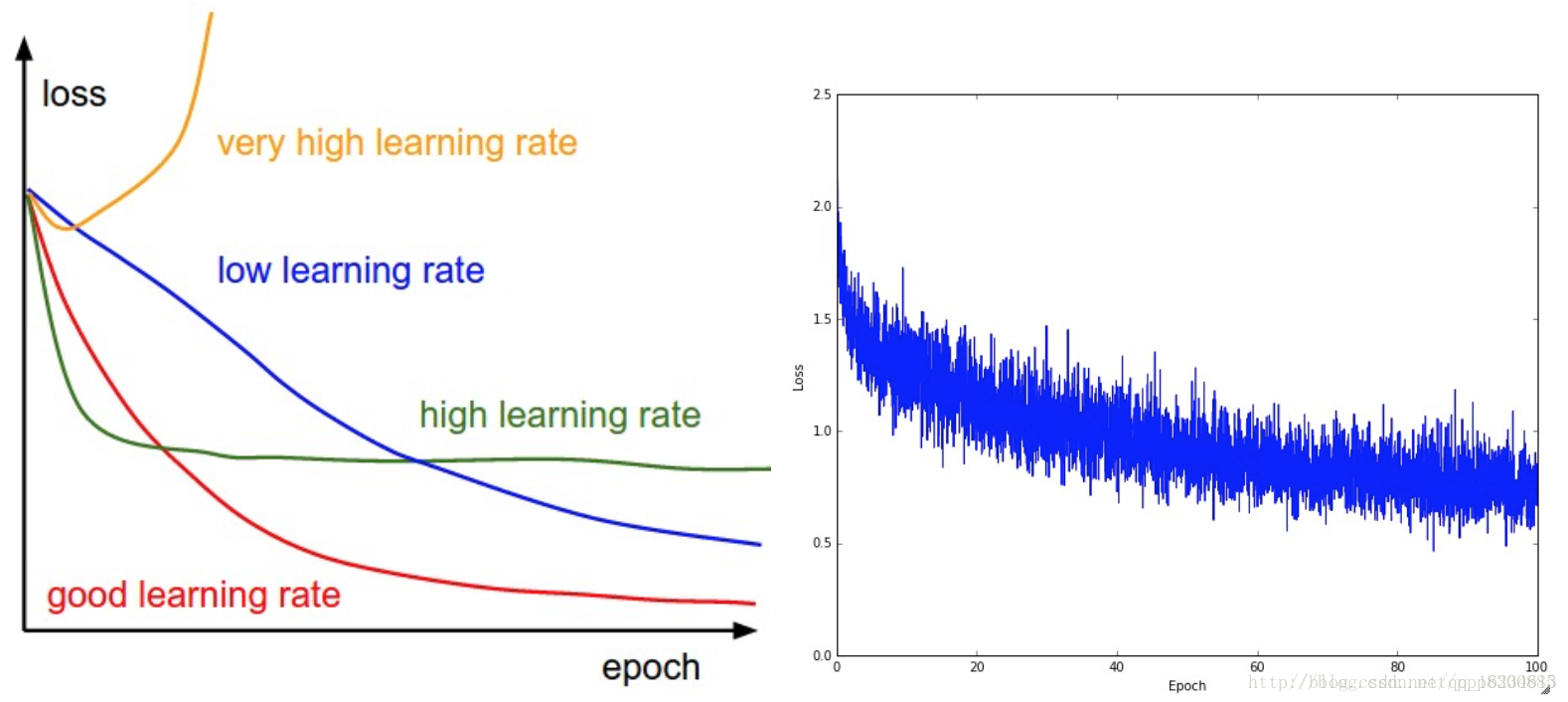
畫圖分析是種不錯調參學習率的方式:學習率過大,loss曲線可能會上升,或者不能一直下降,出現震盪情況,由於學習率較大,導致引數在最優點附近徘徊,loss大小一下大一下小,就是卻無法到達最優點,容易擬合在區域性最小值。學習率太小loss曲線可能下降速度過於緩慢。好的學習率loss呈平滑的下降曲線。
學習率代表了引數的更新步長,你走的距離越短當然不會錯過每個最低點,但是耗時間。而且步長越小,越容易得到區域性最優化(到了比較大的山谷,就出不去了),而太大了可能會直接越過全域性最優點。
- lr:學習率太大,容易梯度爆炸,loss變nan。取1 0.1 0.01 .0001 … 10e-6(取對數變化)。常取0.1。通過對驗證集的預測,可以選擇一個較好的lr。如果當前的學習率不能在驗證集上繼續提高,可以將學習率除以2或者5試試。
- decay:訓練集的損失下降到一定的程度後就不再下降了,而且train loss在某個範圍內來回震盪,不能進一步下降(也就是loss一下跳到最低點左側,一下跳到最低點右側,由於學習率過高就是不能繼續下降)。可採用衰減學習率,學習率隨著訓練的進行逐漸衰減。取0.5。比如當val loss滿足 no-improvement規則時,本來應該採取early stopping,但是可以不stop,而是讓learning rate減半繼續跑。如此反覆。衰減方法有:衰減到固定最低學習率的線性衰減,指數衰減,或每次val loss停滯時衰減2-10倍。
- fine-tuning的時候,可以把新加層的學習率調高,重用層的學習率可以設定的相對較低。
引數初始化
- 破壞不同單元間對稱性,如果兩個單元相同,接受相同的輸入,必須使其具有不同的初始化引數,否則模型將一直以相同方式更新這兩個單元。更大的初始化權重會更容易破壞對稱性,且避免在梯度前向和反向傳播過程中丟失訊號,但如果權重初始化太大,很容易產生爆炸值(梯度爆炸可以使用梯度截斷緩解);而在CNN中會導致模型對輸入高度敏感,導致確定性的前向傳播過程表現的隨機;而且容易導致啟用函式產生飽和的梯度,導致梯度丟失。
- 不可取:
初始化為0,模型無法更新,而且模型權重的相同,導致模型的高度對稱性。
初始化為 very small random numbers(接近0,但不是0),模型效果不好,會導致梯度資訊在傳播中消失。 - 推薦:
一般bias全初始化為0,但在RNN中有可能取1(LSTM)。
random_uniform
random_normal
glorot_normal
glorot_uniform(無腦xavier,為了使得網路中資訊更好的流動,每一層輸出的方差儘量相等。)

啟用函式
- ReLu:通用啟用函式,防止梯度彌散問題。最後一層慎用ReLu做啟用。
- Sigmoid的可微分的性質是傳統神經網路的最佳選擇,但在深層網路中會引入梯度消失和非零點中心問題。除了gate之類的地方,需要把輸出限制成0-1之外,儘量不要用sigmoid,。sigmoid函式在-4到4的區間裡,才有較大的梯度。之外的區間,梯度接近0,很容易造成梯度消失問題。輸入0均值,sigmoid函式的輸出不是0均值的。
- tanh範圍在-1到1之間,且zero-center,但比sigmoid要好,但仍有飽和時梯度消失問題。
- relu比sigmoid和tanh好,導數易計算收斂速度快,不會飽和。唯一問題就是x小於0時梯度為0,可能會導致許多神經元死亡。使用時尤其注意lr的設定
- Leaky_ReLu及ReLu變種,maxout可以試試。
- 通常使用ReLu,及其變種,PReLU and RReLU 效果挺好。tanh可以試試,但不要使用sigmoid。
模型
- 如果輸入向量固定大小,可考慮使用全連線前饋網路,如果輸入為影象等二維結構,可考慮卷積網路,如果輸入為序列,可考慮迴圈神經網路。
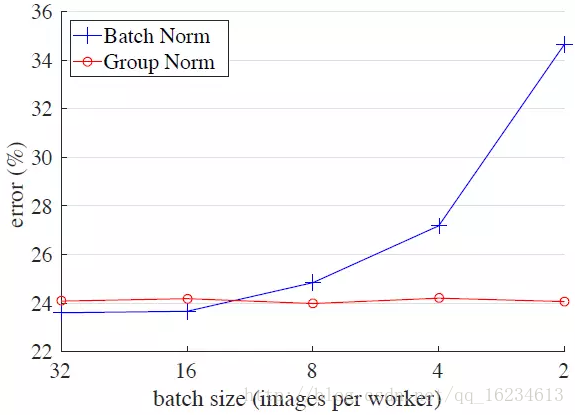
- BN:提高效能,加速訓練,有時可省去dropout。注意BN在batch size過小時效能不是很好。
- 儘量選擇更多的隱層單元,小filter,利用非線性,而過擬合通過正則化的方法避免。
- 一開始需要驗證模型是否有問題,可採取小量資料集、很深模型快速看模型是否能夠對訓練集很好的過擬合,而測試集準確率很低。
- batch_size:常取2的n次方。通常影響不大。 取 32 64 128。batch越大,一般模型加速效果明顯。不考慮時間成本的情況下,batch size=1可作為一個regularizer。
- 不同尺寸的feature maps的concat,利用不同尺度的資訊。
- resnet的shortcut有作用,shortcut的支路一定要是identity。
- 可以利用Inception方法來提取不同抽象程度的高階特徵。
- 梯度歸一化:計算出來梯度之後,除以Minibatch的數量。
- 利用pre-trained model和fine-tune可以實現很好的效能。
優化函式
- Adam:收斂速度快。可以無腦用。
- SGD+Momentum:效果比Adam可能好,但速度稍慢。m取值0.5 0.95 0.9 0.99
- 梯度截斷: 限制最大梯度 或者設定閥值,讓梯度強制等於5,10,20等。
卷積步幅,池化
- strides:取小值,常取1,2,
- filter數量翻倍(數量2^n,第一層不宜太少,n為層數)。反捲積相反。
- kernel size:流行使用小size(3*3),注意對於大目標,感受野太小可能影響效能。尤其對於FCN,FC全連線畢竟具有全域性視野。
- pooling:常取2*2
資料集、輸入預處理和輸出
如何判斷是否應該收集更多資料:
首先判斷當前模型是否在該訓練集上效能良好,如果在當前訓練集上效能就很差,此時應該注重提高模型,增加網路層或隱藏單元等。如果使用更大模型後還是效果不佳,此時應考慮是否是資料集質量不佳(包含太多噪聲等),或模型存在根本錯誤。
然後如果模型在訓練集上效能可以接受,但在測試集上很差,此時可以考慮收集更多資料。但此時需要考慮收集資料的可行性和代價。如果代價太高,一個可行辦法是降低模型大小,改進正則化,調參等。通常在對數尺度上收集資料。
1. 儘可能獲得更多的資料(百萬級以上),移除不良資料(噪音、假資料或空值等,資料中出現nan值時會導致模型loss變成nan)。
2. 資料不足時做好Data Augment。對於影象可以水平翻轉,隨機裁剪crop,旋轉,扭曲,縮放,拉伸,改變色調,飽和度(HSV)等,還可以同時隨機組合。需注意改變後的圖片(垂直翻轉)是否符合實際,是否丟失重要特徵等問題。AlexNet對256的圖片進行224的隨機crop取樣,對每一張圖片,產生2048種不同的樣本,使用映象後,資料集翻了2048*2=4096倍。雖然大量的重取樣會導致資料的相關性,但避免了過擬合。至少比多個epoch輸入相同影象要好。AlexNet中還有一種Fancy PCA取樣方法。
2. 輸入訓練集一定要shuffle。注意keras中自帶的shuflle針對的是batch內部的打亂。
3. 輸入特徵歸一化,zero-center和normalize。PCA whitening一般不需要。還有處理到-1~1之間或0~1之間。
4. 預測目標(label)都做好歸一化。比如迴歸問題中,label相差過大(0.1和1000),做好normalization能統一量綱
5. 資料集類別不平衡問題:上取樣、下采樣。或者使用data augment方式對較少類別資料進行取樣。對類別不平衡進行loss,權重調整。或者將資料集按類別拆分,優先訓練數量多的類別資料,再訓練數量少的類別資料。
6. 不僅訓練集做好增強,測試集也最好做增強。保持二者分佈的一致性。
# zero-center normalize
X -= np.mean(X, axis = 0)
X /= np.std(X, axis = 0)- 1
- 2
- 3
目標函式
- 多工情況下, 各loss儘量限制在一個量級上, 初期可以著重一個任務的loss。
- focal loss可能有點作用
正則化
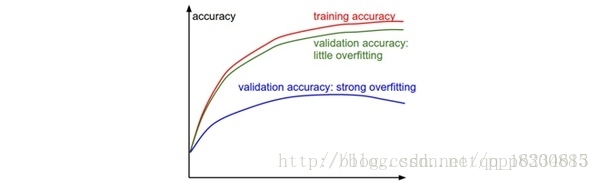
如何判斷是否過擬合或者欠擬合:若訓練集準確率一直大幅度高於驗證集,說明模型過擬合,可以增大正則化強度,如增大L2正則懲罰,增加dropout的隨機失活率等。如果訓練集一直小幅度低於驗證集,說明稍微過擬合,而如果訓練集和驗證集的準確率不相上下,說明此時模型有點欠擬合,沒有很好地學習到特徵,可以調整模型寬度、深度等。
在訓練過程中L2範數使得權重分量儘可能均衡,即非0分量個數儘量稠密,而L1範數和L0範數儘可能使權重分量稀疏,即非0分量個數儘量少。
稀疏效能實現特徵的自動選擇。在我們事先假定的特徵中,有很多特徵對輸出的影響較小,可以看作是不重要的特徵。而正則化項會自動對特徵的係數引數進行懲罰,令某些特徵的權重係數為0或接近於0,自動選擇主要自變數或特徵。
如果當神經元的輸出接近於1的時候我們認為它被啟用,而輸出接近於0的時候認為它被抑制,那麼使得神經元大部分的時間都是被抑制的限制則被稱作稀疏性限制。
建議開始將正則項懲罰係數λ設定為0,待確定比較好的learning rate後,固定該learning rate。給λ一個值(比如1.0),然後根據validation accuracy,將λ增大或者減小10倍進行粗調,然後進行細調。
1. 注意除非資料集比較多(千萬級),否則一開始最好採用溫和一點的正則化。
2. Dropout:相當簡單有效的一種方式,防止過擬合,取0.3 0.5(推薦,0.5時生成的組合網路最多) 0.7
2. L2正則:較為常用的正則方式。在目標函式中新增關於權重的部分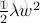
3. L1正則:較為常用的正則方式。在目標函式中新增關於權重的部分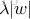
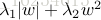
4. Max norm Constraints:由於它限制了權重大小,使用這個約束後,網路一般不會出現“爆炸”問題。
Esemble
- 同樣的引數,不同的初始化方式。使用cross-validation找出最佳超參,然後使用不同引數初始化方式訓練多個模型。
- 不同的引數,通過cross-validation,選取最好的幾組或效能較好的top-K組。
- 同樣的引數,模型訓練的不同階段,即不同迭代次數的模型。
- 不同的模型,進行線性融合. 例如RNN和傳統模型。
- 不同訓練集訓練的模型提取不同特徵進行融合。
簡單點:投票法、平均法、加權平均法
stacking法:
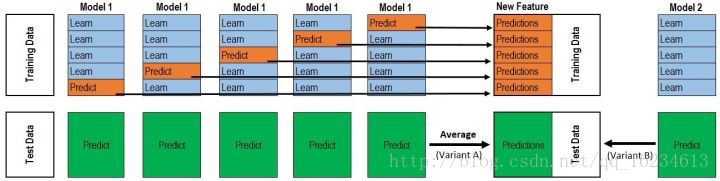
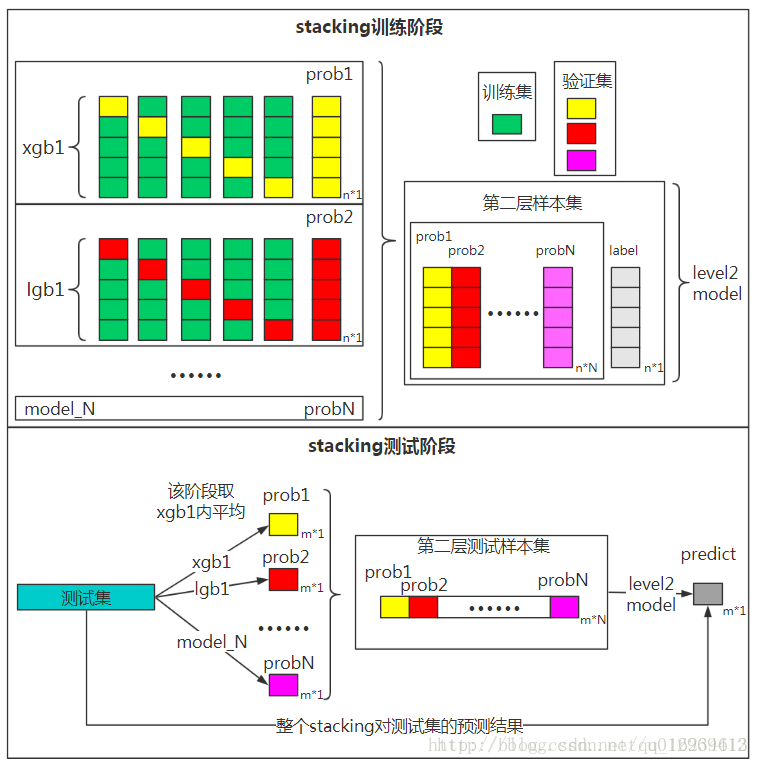
第一層你有模型M1和M3,首先對M1使用5-fold訓練,得到5個模型,然後分別預測訓練集(5折中某1折)合併後生成第二層的訓練集F1,然後使用M1的5個子模型對測試集預測取均值T1,得到第二層的測試集。第一層模型M3同樣採用此方法生成F3和T3。這樣你的第二層模型M2就有訓練集(F1,F2),測試集(T1,T2),使用第二層模型進行訓練預測。
Blending法:
將資料劃分成train,test,然後將train劃分成不相交的兩部分train_1,train_2。
使用不同的模型對train_1訓練,對train_2和test預測,生成兩個1維向量,有多少模型就生成多少維向量。
第二層使用前面模型對train_2生成的向量和label作為新的訓練集,使用LR或者其他模型訓練一個新的模型來預測test生成的向量。
影象視覺化調參
- 視覺化輸出錯誤:通過判斷模型輸出錯誤的樣本,分析原因。
- 視覺化啟用函式值和梯度的直方圖:隱藏單元的啟用值可以告訴我們單元飽和程度;梯度的快速增長和消失不利於模型優化;在一次小批量引數更新過程中梯度引數的更新最好在原引數的1%左右,而不是50%或0.001%。注意如果資料是稀疏的(如自然語言),那麼有些引數可能很少更新。
- tensorboard
其他
- 早停
自動調參
- Random Search
- Gird Search
- Bayesian Optimization
減小記憶體
- 使用更大步態
- 使用1*1線性卷積核降維
- 使用池化降維
- 減小mini-batch大小
- 將資料型別由32為改成為16位
- 使用小的卷積核