
HIT CSAPP 2018 計算機系統大作業
本文通過合理運用這個學期在計算機系統課程上學習的知識,分析研究hello程式在Linux下從程式碼到程式,從出生到終止的過程,通過熟練使用各種工具,學習Linux框架下整個程式的宣告週期,加深對課本知識的印象。
關鍵字:O2O,P2P,預處理,編譯,連結…
目 錄
第1章 概述......................................... - 4 -
1.1 Hello簡介.................................. - 4 -
1.2 環境與工具................................. - 4 -
1.3 中間結果..................................... - 4 -
1.4 本章小結..................................... - 4 -
第2章 預處理..................................... - 5 -
2.1 預處理的概念與作用................. - 5 -
2.3 Hello的預處理結果解析.......... - 5 -
2.4 本章小結..................................... - 5 -
第3章 編譯......................................... - 6 -
3.1 編譯的概念與作用..................... - 6 -
3.2 在Ubuntu下編譯的命令.......... - 6 -
3.3 Hello的編譯結果解析.............. - 6 -
3.4 本章小結..................................... - 6 -
第4章 彙編......................................... - 7 -
4.1 彙編的概念與作用..................... - 7 -
4.2 在Ubuntu下彙編的命令.......... - 7 -
4.3 可重定位目標elf格式.............. - 7 -
4.4 Hello.o的結果解析................... - 7 -
4.5 本章小結..................................... - 7 -
第5章 連結......................................... - 8 -
5.1 連結的概念與作用..................... - 8 -
5.2 在Ubuntu下連結的命令.......... - 8 -
5.4 hello的虛擬地址空間............... - 8 -
5.5 連結的重定位過程分析............. - 8 -
5.6 hello的執行流程....................... - 8 -
5.7 Hello的動態連結分析.............. - 8 -
5.8 本章小結..................................... - 9 -
第6章 hello程序管理................ - 10 -
6.1 程序的概念與作用................... - 10 -
6.2 簡述殼Shell-bash的作用與處理流程.................................................. - 10 -
6.4 Hello的execve過程.............. - 10 -
6.5 Hello的程序執行.................... - 10 -
6.6 hello的異常與訊號處理......... - 10 -
6.7本章小結.................................... - 10 -
第7章 hello的儲存管理............ - 11 -
7.1 hello的儲存器地址空間......... - 11 -
7.2 Intel邏輯地址到線性地址的變換-段式管理.......................................... - 11 -
7.3 Hello的線性地址到實體地址的變換-頁式管理.................................... - 11 -
7.4 TLB與四級頁表支援下的VA到PA的變換........................................ - 11 -
7.5 三級Cache支援下的實體記憶體訪問...................................................... - 11 -
7.6 hello程序fork時的記憶體對映. - 11 -
7.7 hello程序execve時的記憶體對映. - 11 -
7.9動態儲存分配管理.................... - 11 -
7.10本章小結.................................. - 12 -
第8章 hello的IO管理............. - 13 -
8.1 Linux的IO裝置管理方法....... - 13 -
8.2 簡述Unix IO介面及其函式.... - 13 -
8.3 printf的實現分析.................... - 13 -
8.4 getchar的實現分析................ - 13 -
8.5本章小結.................................... - 13 -
結論..................................................... - 14 -
附件..................................................... - 15 -
參考文獻............................................. - 16 -
第1章 概述
1.1 Hello簡介
P2P:
一、編輯hello.c文字
二、預處理:處理”#’,將#define定義的巨集作字元替換;處理條件編譯指令;處理#include,將#include指向的檔案插入;刪除註釋;新增行號和檔案標示;保留#program編譯器指令。
三、編譯:語法分析;語義分析;優化後生成相應的彙編程式碼;從高階語言到組合語言再到二進位制的機器語言。
四、連結:將翻譯生成的二進位制檔案繫結在一起。
五、在shell中啟動,fork產生子程序,成為process。
O2O:
- shell為其execve,對映虛擬記憶體。
- 載入實體記憶體。
- 進入 main函式執行目的碼。
- CPU分配時間片執行邏輯控制流。
- 程式執行結束後,shell父程序回收hello程序。
- 核心刪除相關資料結構,結束。
1.2 環境與工具
一、Windows10 家庭版 build1803
二、VMware14+Ubuntu18.04 64位
三、[email protected] 16GB ram ddr3
四、gcc code blocks
1.3 中間結果
Hello.i 預處理之後文字檔案
Hello.o 編譯之後的彙編檔案
Hello.s 彙編之後的可重定位目標執行
Hello.elf Hello ELF
Hello_ans Hello的反彙編程式碼
Helloa_ans Hello.o的反彙編程式碼
Helloa_elf Hello.o ELF
1.4 本章小結
本章主要簡單總結了hello這個程式的P2P,O2O過程,簡要分析了中間結果。
(第1章0.5分)
第2章 預處理
2.1 預處理的概念與作用
概念:一般指在程式原始碼被翻譯為目的碼的過程中,生成二進位制程式碼之前的過程。
作用:前處理器對程式原始碼文字進行處理,得到的結果再由編譯器進一步編譯。預處理不對原始碼進行解析,但他將會把原始碼分割或處理成特定的單位,並處理符號來支援語言的特性(如C語言的巨集)。
2.2在Ubuntu下預處理的命令
gcc hello.c -E -o hello.i

2.3 Hello的預處理結果解析

展開了stdio.h unistd.h stdlib.h等標頭檔案,將標頭檔案中的#ifdef #ifndef等條件判斷語句處理,只保留了需要的語句

hello.i已經由hello.c 的29行拓展到3000+行,原來的程式碼在文字的最底端。
2.4 本章小結
C程式需要大量的幫助才能從程式碼成為真正的程式,預處理則將找到了他需要的幫手們,並將他們和程式設計師寫下的程式碼安排在需要的地方。本章介紹了預處理的概念和作用,並結合hello.i 簡單分析了預處理的工作。
(第2章0.5分)
第3章 編譯
3.1 編譯的概念與作用
概念:將某一種程式設計語言寫的程式翻譯成等價的另一種語言的程式的程式。
包括:
- 詞法分析:對由字元組成的單詞進行處理,從左至右逐個字元地對源程式進行掃描,產生一個個的單詞符號,把作為字串的源程式改造成為單詞符號串的中間程式。
- 語法分析:以單詞符號作為輸入,分析單詞符號串是否形成符合語法規則的語法單位,如表示式、賦值、迴圈等,最後看是否構成一個符合要求的程式,按該語言使用的語法規則分析檢查每條語句是否有正確的邏輯結構,程式是最終的一個語法單位。
- 生成目的碼:目的碼生成器把語法分析後或優化後的中間程式碼變換成目的碼。
3.2 在Ubuntu下編譯的命令
gcc -S hello.i -o hello.s

3.3 Hello的編譯結果解析
一、指令:
.file 宣告原始檔
.text 程式碼段
.section .rodata rodata節,存放字串和const
.globl 宣告一個全域性變數
.type 用來指定是函式型別或是物件型別
.size 宣告大小
.long、.string 宣告一個long、string型別
.align 宣告對指令或者資料的存放地址進行對齊的方式
二、資料:
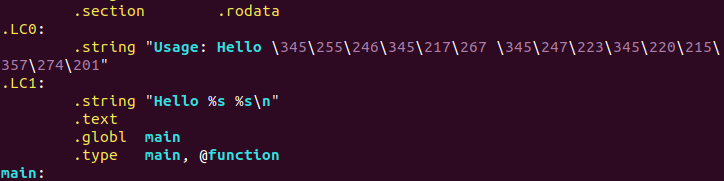
.rodata 存放字串和const,這裡放的是”usage: hello 學號 姓名”。和”hello %s %s\n” 第一個s是引數學號,第二個是姓名。
.text 宣告下面的main是程式碼 .globl 宣告main是全域性的 .type 和 @function宣告main的型別是函式
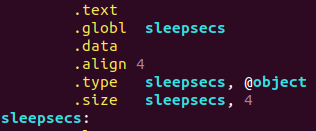
sleepsecs是全域性的object 大小為4bit .align 4說明應該是一個int型別的資料
.data主要存放初始值是0以外的全域性變數和初始值為0以外的靜態區域性變數
![]()
但在這裡sleepsecs的型別被宣告為long,值為2,C語言程式碼中賦值為2.5,依照了C語言向下取整的特性。
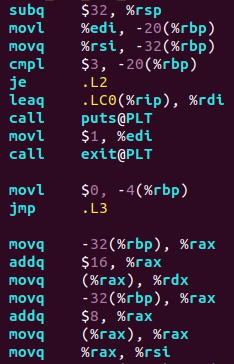
這裡開了長度為32的棧,用來存放傳入的學號和姓名,即char[]。
- 計算:

Leaq .LC0(%rip),%rdi 計算LC1的段地址並傳遞給%rdi
- 控制轉移
cmpl $3, -20(%rbp)
je .L2
-20(%rbp)與3比較,相等跳轉.L2 由C語言程式碼知-20(%rbp)即argv
cmpl $9, -4(%rbp)
jle .L4
即C語言中的for(i=0;i<10;i++)
- 函式:
main:
printf:
sleep:
getchar:
3.4 本章小結
解釋了編譯器是如何處理C語言的各個資料型別以及各類操作的,基本都是先給出原理然後結合hello.c C程式到hello.s彙編程式碼之間的對映關係作出合理解釋。
(第3章2分)
第4章 彙編
4.1 彙編的概念與作用
概念:把組合語言翻譯成機器語言的過程稱為彙編。
作用:彙編器將.s彙編程式翻譯成機器語言指令,把這些指令打包成可重定位目標程式的格式,並將結果儲存在.o目標檔案中,.o檔案是一個二進位制檔案,它包含程式的指令編碼。這個過程稱為彙編,亦即彙編的作用。
4.2 在Ubuntu下彙編的命令
as hello.s -o hello.o

4.3 可重定位目標elf格式

Magic描述了生成該檔案的系統的字的大小和位元組順序,ELF頭剩下的部分包含幫助連結器語法分析和解釋目標檔案的資訊,其中包括節頭大小、目標檔案的型別、系統及硬體型別、位元組頭部表(section header table)的檔案偏移,以及節頭部表中條目的大小和數量等資訊。

重定位節.rela.text ,一個.text節中位置的列表,包含.text節中需要進行重定位的資訊,當連結器把這個目標檔案和其他檔案組合時,需要修改這些位置。如圖4.4,圖中8條重定位資訊分別是對.L0(第一個printf中的字串)、puts函式、exit函式、.L1(第二個printf中的字串)、printf函式、sleepsecs、sleep函式、getchar函式進行重定位宣告。

4.4 Hello.o的結果解析


分支轉移:反彙編程式碼跳轉指令的運算元由段名稱變成了確定的地址。
運算元:由.s中的數變成了具體的準確數字,如call 0 變為準確地址。
函式呼叫:在.s檔案中,函式呼叫之後直接跟著函式名稱,而在反彙編程式中,call的目標地址是當前下一條指令。這是因為hello.c中呼叫的函式都是共享庫中的函式,最終需要通過動態連結器才能確定函式的執行時執行地址。
全域性變數:在.s檔案中,全域性變數使用段名稱+%rip,在反彙編程式碼中0+%rip,因為rodata中資料地址也是在執行時確定,故訪問也需要重定位。所以在彙編成為機器語言時,將運算元設定為全0並新增重定位條目。
4.5 本章小結
介紹了hello從hello.s到hello.o的彙編過程,比較了前後的的結果,瞭解了從組合語言對映到機器語言彙編器需要實現的轉換。
(第4章1分)
第5章 連結
5.1 連結的概念與作用
連結的過程就是指,經過編譯後將會生成一個目標檔案,這個目標檔案可能會呼叫printf等函式,對於printf函式,它的目的碼在系統的函式庫中,連結所要做的就是將這些函式庫中相應的程式碼組合到目標檔案中去。
5.2 在Ubuntu下連結的命令
ld -o hello -dynamic-linker /lib64/ld-linux-x86-64.so.2 /usr/lib/x86_64-linux-gnu/crt1.o /usr/lib/x86_64-linux-gnu/crti.o hello.o /usr/lib/x86_64-linux-gnu/libc.so /usr/lib/x86_64-linux-gnu/crtn.o

5.3 可執行目標檔案hello的格式
。


記錄了各節的大小,偏移量,地址(程式被載入到虛擬地址的起始地址)
5.4 hello的虛擬地址空間
使用edb開啟hello程式,通過edb的Data Dump視窗檢視載入到虛擬地址中的hello程式。
在0x400000~0x401000段中,程式被載入,自虛擬地址0x400000開始,自0x400fff結束,這之間每個節(開始 ~ .eh_frame節)的排列即開始結束同下圖中Address中宣告。

如上圖,檢視ELF格式檔案中的Program Headers,程式頭表在執行的時候被使用,它告訴連結器執行時載入的內容並提供動態連結的資訊。每一個表項提供了各段在虛擬地址空間和實體地址空間的大小、位置、標誌、訪問許可權和對齊方面的資訊。在下面可以看出,程式包含8個段:
PHDR儲存程式頭表。
INTERP指定在程式已經從可執行檔案對映到記憶體之後,必須呼叫的直譯器(如動態連結器)。
LOAD表示一個需要從二進位制檔案對映到虛擬地址空間的段。其中儲存了常量資料(如字串)、程式的目的碼等。
DYNAMIC儲存了由動態連結器使用的資訊。
NOTE儲存輔助資訊。
GNU_STACK:許可權標誌,標誌棧是否是可執行的。
GNU_RELRO:指定在重定位結束之後那些記憶體區域是需要設定只讀。
5.5 連結的重定位過程分析
.interp 儲存ld.so的路徑
.note.ABI-tag Linux下特有的section
.hash 符號的雜湊表
.gnu.hash GNU拓展的符號的雜湊表
.dynsym 執行時/動態符號表
.dynstr 存放.dynsym節中的符號名稱
.gnu.version 符號版本
.gnu.version_r 符號引用版本
.rela.dyn 執行時/動態重定位表
.rela.plt .plt節的重定位條目
.init 程式初始化需要執行的程式碼
.plt 動態連結-過程連結表
.fini 當程式正常終止時需要執行的程式碼
.eh_frame contains exception unwinding and source language information.
.dynamic 存放被ld.so使用的動態連結資訊
.got 動態連結-全域性偏移量表-存放變數
.got.plt 動態連結-全域性偏移量表-存放函式
.data 初始化了的資料
.comment 一串包含編譯器的NULL-terminated字串
5.6 hello的執行流程
通過比較hello.objdump和helloo.objdump瞭解連結器。
1)函式個數:在使用ld命令連結的時候,指定了動態連結器為64的/lib64/ld-linux-x86-64.so.2,crt1.o、crti.o、crtn.o中主要定義了程式入口_start、初始化函式_init,_start程式呼叫hello.c中的main函式,libc.so是動態連結共享庫,其中定義了hello.c中用到的printf、sleep、getchar、exit函式和_start中呼叫的__libc_csu_init,__libc_csu_fini,__libc_start_main。連結器將上述函式加入。
2)函式呼叫:連結器解析重定條目時發現對外部函式呼叫的型別為R_X86_64_PLT32的重定位,此時動態連結庫中的函式已經加入到了PLT中,.text與.plt節相對距離已經確定,連結器計算相對距離,將對動態連結庫中函式的呼叫值改為PLT中相應函式與下條指令的相對地址,指向對應函式。對於此類重定位連結器為其構造.plt與.got.plt。
3).rodata引用:連結器解析重定條目時發現兩個型別為R_X86_64_PC32的對.rodata的重定位(printf中的兩個字串),.rodata與.text節之間的相對距離確定,因此連結器直接修改call之後的值為目標地址與下一條指令的地址之差,指向相應的字串。這裡以計算第一條字串相對地址為例說明計算相對地址的演算法(演算法說明同4.3節):
refptr = s + r.offset = Pointer to 0x40054A
refaddr = ADDR(s) + r.offset= ADDR(main)+r.offset=0x400532+0x18=0x40054A
*refptr=(unsigned)(ADDR(r.symbol)+r.addend-refaddr)=ADDR(str1)+r.addend-refaddr=0x400644+(-0x4)-0x40054A=(unsigned) 0xF6,
觀察反彙編驗證計算:
![]()
5.7 Hello的動態連結分析
5.8 本章小結
介紹了連結的概念與作用、hello的ELF格式,分析了hello的虛擬地址空間、重定位過程、執行流程、動態連結過程。
(第5章1分)
第6章 hello程序管理
6.1 程序的概念與作用
概念:程序是一個執行中的程式的例項,每一個程序都有它自己的地址空間,一般情況下,包括文字區域、資料區域、和堆疊。文字區域儲存處理器執行的程式碼;資料區域儲存變數和程序執行期間使用的動態分配的記憶體;堆疊區域儲存區著活動過程呼叫的指令和本地變數。
作用:程序為使用者提供了以下假象:我們的程式好像是系統中當前執行的唯一程式一樣,我們的程式好像是獨佔的使用處理器和記憶體,處理器好像是無間斷的執行我們程式中的指令,我們程式中的程式碼和資料好像是系統記憶體中唯一的物件。
6.2 簡述殼Shell-bash的作用與處理流程
作用:shell 是一個互動型的應用級程式,它代表使用者執行其他程式。
處理流程:shell 執行一系列的讀/求值(read /evaluate ) 步驟,然後終止。讀步驟讀取來自使用者的一個命令列。求值步驟解析命令列,並代表使用者執行程式。
6.3 Hello的fork程序建立過程
一個程序被建立了,這個程序(hello)父程序一樣,擁有一套與父程序相同的變數,相同的一套程式碼,這裡可以粗淺的理解為子程序又複製了一份main函式。這裡返回一個子程序的程序號,大於0。
6.4 Hello的execve過程
1.使用execve就是一次系統呼叫,首先要做的將新的可執行檔案的絕對路徑從呼叫者(使用者空間)拷貝到系統空間中。
2.在得到可執行檔案路徑後,就找到可執行檔案開啟,由於作業系統已經為可執行檔案設定了一個數據結構,就初始化這個資料結構,儲存一個可執行檔案必要的資訊。
3.可執行檔案不是真正上能夠自己執行的,需要有代理人來代理。在系統核心中有一個formats佇列,迴圈遍歷這個佇列,看看現在被初始化的這個資料結構是哪個代理人可以代理的。如果沒有就繼續檢視資料結構中的資訊。按照系統配置了是否可以動態載入模組,載入一次模組,再迴圈遍歷看是否有代理人前來認領。
4.找到正確的代理人後,代理人首先要做的就是放棄以前從父程序繼承來的資源(雖然代理程式各不相同,但這是一個共性的操作)。主要是對訊號處理表,使用者空間和檔案3大資源的處理。
6.5 Hello的程序執行
Linux 系統中的每個程式都執行在一個程序上下文中,有自己的虛擬地址空間。當shell 執行一個程式時,父shell 程序生成一個子程序,它是父程序的一個複製。子程序通過execve 系統呼叫啟動載入器。載入器刪除子程序現有的虛擬記憶體段,並建立一組新的程式碼、資料、堆和棧段。新的棧和堆段被初始化為零。通過將虛擬地址空間中的頁對映到可執行檔案的頁大小的片(chunk), 新的程式碼和資料段袚初始化為可執行檔案的內容。最後,載入器跳轉到_start地址,它最終會呼叫應用程式的main 函式。
6.6 hello的異常與訊號處理

正常執行hello,執行完成之後,程序被回收。

當按下ctrl-z之後,shell父程序收到SIGSTP訊號,訊號處理函式的邏輯是列印螢幕回顯、將hello程序掛起,通過ps命令我們可以看出hello程序沒有被回收,此時他的後臺job號是1,呼叫fg 1將其調到前臺,此時shell程式首先列印hello的命令列命令,hello繼續執行列印剩下的10條info,之後按下回車,程式結束,同時程序被回收。

當按下ctrl-c之後,shell父程序收到SIGINT訊號,訊號處理函式的邏輯是結束hello,並回收hello程序。

程式執行中途亂按,只是將螢幕的輸入快取到stdin,當getchar的時候讀出一個’\n’結尾的字串(作為一次輸入),其他字串會當做shell命令列輸入。
6.7本章小結
給出了程序的定義與作用,介紹了Shell的一般處理流程,呼叫fork建立新程序,呼叫execve執行hello,hello的程序執行,hello的異常與訊號處理。
(第6章1分)
第7章 hello的儲存管理
7.1 hello的儲存器地址空間
實體地址(physical address)
用於記憶體晶片級的單元定址,與處理器和CPU連線的地址匯流排相對應。
——這個概念應該是這幾個概念中最好理解的一個,但是值得一提的是,雖然可以直接把實體地址理解成插在機器上那根記憶體本身,把記憶體看成一個從0位元組一直到最大空量逐位元組的編號的大陣列,然後把這個陣列叫做實體地址,但是事實上,這只是一個硬體提供給軟體的抽像,記憶體的定址方式並不是這樣。所以,說它是“與地址匯流排相對應”,是更貼切一些,不過拋開對實體記憶體定址方式的考慮,直接把實體地址與物理的記憶體一一對應,也是可以接受的。也許錯誤的理解更利於形而上的抽像。
虛擬記憶體(virtual memory)
這是對整個記憶體(不要與機器上插那條對上號)的抽像描述。它是相對於實體記憶體來講的,可以直接理解成“不直實的”,“假的”記憶體,例如,一個0x08000000記憶體地址,它並不對就實體地址上那個大陣列中0x08000000 - 1那個地址元素;
之所以是這樣,是因為現代作業系統都提供了一種記憶體管理的抽像,即虛擬記憶體(virtual memory)。程序使用虛擬記憶體中的地址,由作業系統協助相關硬體,把它“轉換”成真正的實體地址。這個“轉換”,是所有問題討論的關鍵。
有了這樣的抽像,一個程式,就可以使用比真實實體地址大得多的地址空間。(拆東牆,補西牆,銀行也是這樣子做的),甚至多個程序可以使用相同的地址。不奇怪,因為轉換後的實體地址並非相同的。
——可以把連線後的程式反編譯看一下,發現聯結器已經為程式分配了一個地址,例如,要呼叫某個函式A,程式碼不是call A,而是call 0x0811111111 ,也就是說,函式A的地址已經被定下來了。沒有這樣的“轉換”,沒有虛擬地址的概念,這樣做是根本行不通的。
打住了,這個問題再說下去,就收不住了。
邏輯地址(logical address)
Intel為了相容,將遠古時代的段式記憶體管理方式保留了下來。邏輯地址指的是機器語言指令中,用來指定一個運算元或者是一條指令的地址。以上例,我們說的聯結器為A分配的0x08111111這個地址就是邏輯地址。
——不過不好意思,這樣說,好像又違背了Intel中段式管理中,對邏輯地址要求,“一個邏輯地址,是由一個段識別符號加上一個指定段內相對地址的偏移量,表示為 [段識別符號:段內偏移量],也就是說,上例中那個0x08111111,應該表示為[A的程式碼段識別符號: 0x08111111],這樣,才完整一些”
線性地址(linear address)或也叫虛擬地址(virtual address)
跟邏輯地址類似,它也是一個不真實的地址,如果邏輯地址是對應的硬體平臺段式管理轉換前地址的話,那麼線性地址則對應了硬體頁式記憶體的轉換前地址。
7.2 Intel邏輯地址到線性地址的變換-段式管理
段式記憶體管理方式就是直接將邏輯地址轉換成實體地址,也就是CPU不支援分頁機制。其地址的基本組成方式是段號+段內偏移地址。 在介紹段式記憶體管理方式之前首先介紹邏輯空間。邏輯空間分為若干個段,其中每一個段都定義了一組具有完整意義的資訊,邏輯地址對應於邏輯空間,如(主程式的main())函式,如下圖所示。
段是對程式邏輯意義上的一種劃分,一組完整邏輯意義的程式被劃分成一段,所以段的長度是不確定的。

如上圖所示,段式記憶體管理方式經過段表對映到記憶體空間。先說明一下段表的概念,可以將段表抽象成一個大的陣列集合,陣列中的元素是什麼呢?就是“段描述符”----用於描述一個段的詳細資訊的結構。段描述符一般是由8個位元組組成,也就是64位。作業系統使用的不同的段描述符如下圖所示。

將邏輯地址轉換成下一個環節的地址(實體地址,不適用分頁或者使用分頁的線性地址)需要使用段表,而獲得段表中一個特定的段描述符需要使用段選擇符,這裡需要區分的概念就是“段選擇符"和“段描述符"。段描述符描述了一個段的詳細資訊,例如,起始地址(BASE的32位,長度20位),適用於轉換下一個環節的地址所需要的詳細資訊;而段選擇符是用於找到對應的段描述符的。
下面說一下段選擇符。段選擇符是一個由16位長的欄位組成的,其中前13位是一個索引號,後面三位包含一些硬體細節,如下圖所示。

根據段選擇符可以獲取段描述符,雖然段描述符比較複雜,但是對於定址而言,我們只關注Base的32位,它 描述了一個段的開始位置的線性地址。Intel設計的本意是,一些全域性的段描述符,就放在"全域性段描述符(GDT)"中,一些區域性的,例如每個程序自己的,就放在所謂的"區域性段描述符表(LDT)中"。那麼,究竟什麼時候該用GDT,什麼時候該用LDT呢?這是由段選擇描述符中的T1欄位表示的,=0標識使用GDT,=1表示使用LDT。GDT在記憶體中的大小和地址存放在CPU的gdtr暫存器中,而LDT則在ldtr暫存器中。如下圖所示。

首先給定一個完整的邏輯地址[段選擇符:段內偏移地址], 1.看段選擇描述符中的T1欄位是0還是1,可以知道當前要轉換的是GDT中的段,還是LDT中的段,再根據指定的相應的暫存器,得到其地址和大小,我們就有了一個數組了。 2.拿出段選擇符中的前13位,可以在這個陣列中查詢到對應的段描述符,這樣就有了Base,即基地址就知道了。 3.把基地址Base+Offset,就是要轉換的下一個階段的實體地址。
7.3 Hello的線性地址到實體地址的變換-頁式管理
CPU的頁式記憶體管理單元負責把一個線性地址轉換為實體地址。從管理和效率的角度出發,線性地址被劃分成固定長度單位的陣列,稱為頁(page)。例如,一個32位的機器,線性地址可以達到4G,用4KB為一個頁來劃分,這樣,整個線性地址就被劃分為一個2^20次方的的大陣列,共有2的20次方個頁,也就是1M個頁,我們稱之為頁表,改頁表中每一項儲存的都是物理頁的基地址。 這裡不得不說的是另一個“頁”,我們稱之為物理頁,或者頁框、頁楨。是分頁單元將所有的實體記憶體都劃分成了固定大小的單元為管理單位,其大小一般與記憶體頁大小一致。 如果記憶體頁按照這種方式進行管理,管理記憶體頁需要2^20次方的陣列,其中每個陣列都是32bit,也就是4B(其中前20位儲存實體記憶體頁的基地址,後面的12位留空,用於與給定的線性地址的後12位拼接起來一起組成一個真實的實體地址,尋找資料的所在。這樣就需要為每個程序維護4B*2^20=4MB的記憶體空間,極大地消耗了記憶體。為了能夠儘可能的節約記憶體,CPU在頁式記憶體管理方式中引入了兩級的頁表結構,如下圖所示。

如上圖所示,這種頁式管理方式中,第一級的頁表稱之為“頁目錄”,用於存放頁表的基地址;第二級才是真正的“頁表”用於存放實體記憶體中頁框的基地址。 1、二級頁目錄的頁式記憶體管理方式中,第一級的頁目錄的基址存放在CPU暫存器CR3中,這也是轉換的開始點; 2、每一個活動的程序,都有其對應的獨立虛擬記憶體(頁目錄也是唯一的),那麼它對應一個獨立的頁目錄地址。--執行一個程序,需要將它的頁目錄地址放到CR3暫存器中,將別的頁目錄的基址暫時換到記憶體中; 3、每個32位的線性地址被劃分成三部分,頁目錄索引(10位),頁表索引(10位),偏移量(12位)。線性地址轉換成實體地址的過程如下: 1、從CR3中取出程序的頁目錄的地址(作業系統在負責程序的排程的時候,將這個地址裝入對應的CR3地址暫存器),取出其前20位,這是頁目錄的基地址; 2、根據取出來的頁目錄的基地址以及線性地址的前十位,進行組合得到線性地址的前十位的索引對應的項在頁目錄中地址,根據該地址可以取到該地址上的值,該值就是二級頁表項的基址;當然你說地址是32位,這裡只有30位,其實當取出線性地址的前十位之後還會該該前十位左移2位,也就是乘以4,一共32位;之所以這麼做是因為每個地址都是4B的大小,因此其地址肯定是4位元組對齊的,因此左移兩位之後的32位的值恰好就是該前十位的索引項的所對應值的起始地址,只要從該地址開始向後讀四個位元組就得到了該十位數字對應的頁目錄中的項的地址,取該地址的值就是對應的頁表項的基址; 3、根據第二步取到的頁表項的基址,取其前20位,將線性地址的10-19位左移2位(原因和第2步相同),按照和第2步相同的方式進行組合就可以得到線性地址對應的物理頁框在記憶體中的地址在二級頁表中的地址的起始地址,根據該地址向後讀四個位元組就得到了線性地址對應的物理頁框在記憶體中的地址在二級頁表中的地址,然後取該地址上的值就得到線性地址對應的物理頁框在記憶體中的基地址;(這一步的地址比較繞,還請仔細琢磨,反覆推敲) 4、根據第3步取到的基地址,取其前20位得到物理頁框在記憶體中的基址,再根據線性地址最後的12位的偏移量得到具體的實體地址,取該地址上的值就是最後要得到值; 其實,對比一級頁表機制和二級頁表機制可以發現,二級頁表機制中同樣需要1024個二級頁表,每個頁表都有1024項,每項的大小都是4B,因此一個二級頁表需要4KB,1024個二級頁表需要4MB的空間,再加上頁目錄,好像比只有一級頁表機制佔用了更多的記憶體,而且定址方式變得更復雜了,似乎是在自己給自己找麻煩。從CPU的開銷中可以看到,如果是一級頁表機制,那麼CPU取到一個數需要訪問記憶體兩次,而使用二級頁表機制之後,CPU想要取得一個運算元,需要訪問記憶體三次。其實,使用二級頁表機制還是有很多優點的,如下: 1、二級表結構也許頁表分散在記憶體的各個頁面中,而不需要儲存在連續的4M的記憶體塊中; 2、不需要位不存在的線性地址空間分配二級頁表,雖然目錄表頁面總是必須存在於實體記憶體中,但是二級頁表可以在需要的時候再分配,這使得頁表結構的大小對應於實際使用的線性地址空間的大小; 3、頁目錄和頁表中的每個表項都有一個存在屬性,頁目錄中的存在屬性指明對應的頁表結構是否存在。如果頁目錄指明對應的二級頁表存在,那麼通過訪問二級表,表查詢過程就像上面的查詢過程一樣進行下去;如果存在標誌表明對應的二級表項不存在,那麼處理器就會產生一個缺頁異常來通知作業系統。頁目錄表項的存在屬性使得作業系統可以根據實際使用的線性地址範圍來分配二級頁表頁面;當然,頁目錄表項中的存在位還可以在虛擬記憶體中存放二級頁表,這意味著在任何的時候只有部分二級頁表需要存放在實體記憶體中,其餘部分可以儲存在磁碟中。處於實體記憶體中的頁表對應的頁目錄項可以被標註為存在,以表明可用它們進行分頁轉換。處於磁碟上的頁表對應的頁目錄項被標註為不存在。由於二級頁表不存在而引發的異常會通知作業系統將缺少的頁表從磁碟上載入進實體記憶體。將頁表儲存在虛擬記憶體中減少了儲存頁表所需要的實體記憶體;
7.4 TLB與四級頁表支援下的VA到PA的變換
VA到PA的對映過程
相關推薦
HIT CSAPP 2018 計算機系統大作業
摘 要 本文通過合理運用這個學期在計算機系統課程上學習的知識,分析研究hello程式在Linux下從程式碼到程式,從出生到終止的過程,通過熟練使用各種工具,學習Linux框架下整個程式的宣告週期,加深對課本知識的印象。 關鍵字
HIT CSAPP 計算機系統大作業 《程式人生 - Hello’s P2P》
HIT CSAPP 計算機系統大作業 《程式人生 - Hello’s P2P》 計算機系統 大作業 題 目 程式人生-Hello’s P2P 專 業 軟體工程 學 號 1173710104 班 級 1737101 學 生 滕濤 指 導 教 師
計算機系統大作業
程式人生-Hello’s P2P ** 摘要 ** 本文遍歷了hello.c在Linux下生命週期,藉助Linux下系列開發工具,通過對其預處理、編譯、彙編等過程的分步解讀及對比來學習各個過程在Linux下實現機制及原因。同時通過對hello在Shell中的動態連結、程序執行
深入理解計算機系統大作業
摘要 本論文從一個程式檔案hello.c出發,通過講述該檔案實現P2P,O2O的過程,簡單地展現了計算機系統的工作原理,並且回顧了許多實用的工具。 關鍵詞:P2P,O2O,計算機系統,程式; 第1章 概述 1.1 Hello簡介 P2P 1.編譯過程 2. 建立並執行程
深入理解計算機系統家庭作業第六章
/* ***6.23 */ 等價於求xr(1 - x)的最大值,由代數知識得x=0.5的時候取得最大。 /* ***6.24 */ 0.5 * 60 / 12000 * 1000 + 60 / 12000 * 1000 /500 + 3 = 5.51ms /* ***6
哈工大計算機系統課後作業第七章7.13A的解釋
關於libm.a的問題,現解釋如下: 1. 正常情況下是如此結果: $ ar -t /usr/lib/x86_64-linux-gnu/libm.a ar: /usr/lib/x86_64-linux-gnu/libm.a: File format not recognized
opencv2實現多張圖片路線路牌檢測_計算機視覺大作業2
linefinder.h同上一篇博文 main.cpp /*------------------------------------------------------------------------------------------*\ This file con
深入理解計算機系統家庭作業第三章
/* ***3.54 ***寫出decode2的原型*/ int decode2(int x ,int y, int z) { int a = z - y; int b = (a << 15) >> 15; return (x ^ a) *
CSAPP-C1-計算機系統漫遊
概念 clas 獲得 連接 打包成 進行 硬件 實現 重要 第1章-計算機系統漫遊 程序被其他程序翻譯成不同的格式 GCC編譯器驅動程序讀取源程序文件,並把它翻譯成一個可執行目標文件。這個翻譯過程可分為4個階段(預處理階段,編譯階段,匯編階段,鏈接階段)完成,這4個階段的
深入理解計算機系統家庭作業第五章
/* ***5.15 */ A. 畫圖略 B. 3 C. 1 D. 乘法不在關鍵路徑上,故乘法可以按流水線執行 /* ***5.16 */ A. 每次要載入兩個資料,故至少需要兩個週期 B. 迴圈展開並沒有改變關鍵路徑長 /* ***5.1
深入理解計算機系統家庭作業第四章(4.43-4.54)
/* *****4.43 */ A. 根據4.6可知,push %esp 是將%esp的舊值壓入棧中;而這段程式碼壓入的新值,兩者不一致。 B. 將%esp的舊值先放入另一個暫存器中再進行操作 movl REG %eax sub
CSAPP =1= 計算機系統漫遊
# 思維導圖 預計閱讀時間:15min 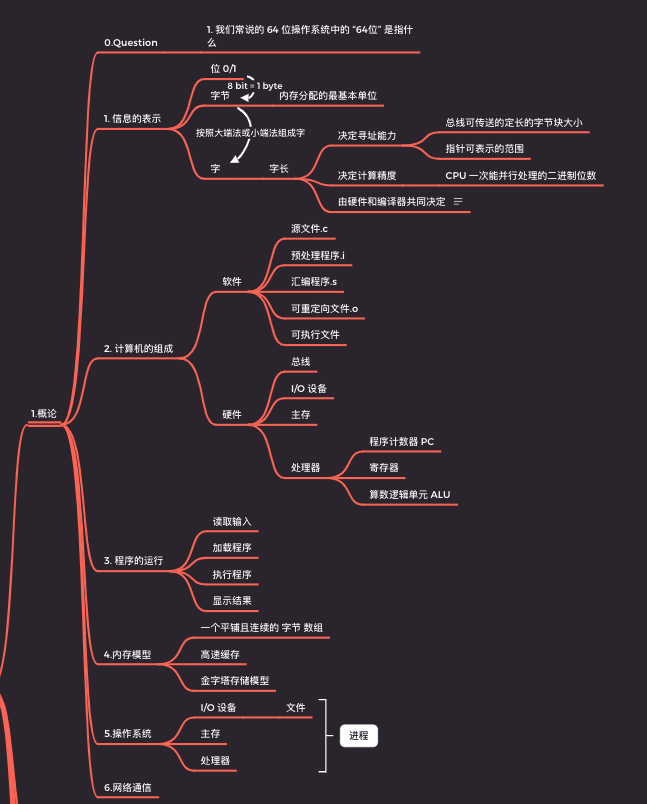 閱讀書籍 《深入理解計算機系統》 參考視訊 [【精校中英字幕】201
2018 HIT CSAPP 大作業:Hello的一生
目 錄 第1章 概述 - 4 - 1.1 Hello簡介 - 4 - 1.2 環境與工具 - 4 - 1.3 中間結果 - 4 - 1.4 本章小結 - 5 - 第2章 預處理 - 6 - 2.1 預處理的概念與作用 - 6 - 2.2在Ubuntu下預處理的命令 - 6 - 2.3 H
CSAPP深入理解計算機系統(第二版)第三章家庭作業答案
《深入理解計算機系統(第二版)》CSAPP 第三章 家庭作業 這一章介紹了AT&T的彙編指令 比較重要 本人完成了《深入理解計算機系統(第二版)》(以下簡稱CSAPP)第三章的家庭作業,並與網上的一些答案進行了對比修正。 感謝博主summerhust的整理,以下貼出AT&T常用匯編指令
CSAPP大作業 2018 Hello's P2P
電腦科學與技術學院 2018年12月 摘 要 在電腦科學的發展中,大部分程式猿都是通過hello.c這一簡單的程式來接觸程式設計。然而正是因為hello的單純與淺顯沒有讓程式猿感到“至少40%”的神祕,它便遭遇冷落甚至無視。難道它真的如同它的表象,簡單得不像是實力派嗎?還真不是:僅僅這樣一個
深入理解計算機系統-作業2.10
oid 位置 pla borde 作業2 nbsp body 開始 width 1 void inplace_swap(int *x, int *y){ 2 *y = *x ^ *y;/*step1*/ 3 *x = *x ^ *y;/*step2*/ 4
《深入理解計算機系統》關於csapp.h和csapp.c的編譯問題(轉)
系統 文件中 class net 工作 inux 而且 pan div 編譯步驟如下: 1.我的當前工作目錄為/home/sxh2/clinux,目錄下有3個文件inet_aton.c csapp.h csapp.c。 2.編譯csapp.c文件,命令為gcc -c csa
深入理解計算機系統_3e 第四章家庭作業(部分) CS:APP3e chapter 4 homework
ray design sed copy default ror this 處理 implement 4.52以後的題目中的代碼大多是書上的,如需使用請聯系 [email protected] 流水線部分只寫了偶數題號的,這幾天太浮躁,落下了好多課。。。 4.
深入理解計算機系統_3e 第八章家庭作業 CS:APP3e chapter 8 homework
fig lar man message -- ali rail raise mat 8.9 關於並行的定義我之前寫過一篇文章,參考: 並發與並行的區別 The differences between Concurrency and Parallel +----------
深入理解計算機系統_3e 第十一章家庭作業 CS:APP3e chapter 11 homework
cep serve 技術分享 apn only class control 相同 法則 註:tiny.c csapp.c csapp.h等示例代碼均可在Code Examples獲取 11.6 A. 書上寫的示例代碼已經完成了大部分工作:doit函數中的printf("%