
《機器學習(周志華)》——第6章 支援向量機
1、間隔與支援向量
(1)分類學習的最基本思想就是:基於訓練集D在樣本空間中找到一個劃分超平面,將不同類別的樣本分開。
(2)在樣本空間中,用線性方程來表示劃分超平面:ωTx + b = 0 ;其中ω = (ω1;ω2; … ; ωd)為法向量,決定超平面內的方向;b為位移項,決定超平面與原點之間的距離。
則樣本空間中任意點x到超平面的距離為:
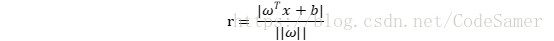
假設超平面(ω, b)能夠正確分類樣本,即對(xi , yi) ∈D,若yi = +1,有ωTxi + b >0 ;若 yi = -1,有ωTxi+ b < 0. 令:
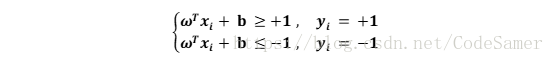
距離超平面最近的幾個訓練樣本點使上式成立,它們被稱為支援向量(support vector),兩個異類支援向量到超平面的距離之和
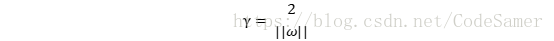
想要找到最大間隔(maximum margin)的劃分超平面,也就是找使γ最大時滿足的約束引數ω和b;也就是要最大化 ‖ω‖-1,等價於最小化‖ω‖2 。
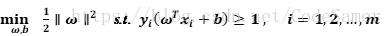
這就是支援向量機(Support VectorMachine,簡稱SVM)的基本型。
【注:這裡是因為yi和 (ωTxi + b) 始終是同號的,且|ωTxi+ b|≥1】
2、對偶問題(dual problem)
(1)使用拉格朗日乘子法得到SVM的對偶問題,對式中每條約束新增拉格朗日乘子αi ≥0,則拉格朗日函式為:
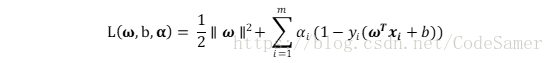
對變數ω和b求偏導得:

代入L(ω, b, α
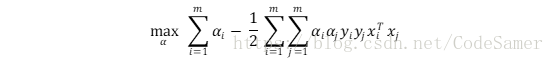

解出α後代入求出ω, b得:
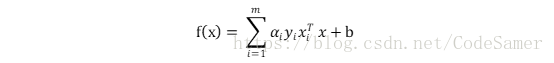
上式需滿足KKT條件,即:

若αi = 0,則樣本不會對f(x)產生影響;若αi>0,則必有yif(xi) = 1,對應的樣本點位於最大間隔邊界,是一個支援向量;這表明SVM的一個重要性質:訓練完成後,大部分訓練樣本不需要保留,最終模型僅與支援向量有關。
(2)SMO演算法:先固定αi之外的所有引數,然後求αi上的極值。SMO每次選取兩個變數αi和αj ,不斷執行如下兩個步驟直至收斂:
① 選取一對需更新的變數αi和αj ;
② 固定αi和αj以外的引數,求解化簡式獲得更新後的αi和αj。
SMO先選取違背KKT條件程度最大的變數,在選取第二個變數時,使選取的兩變數所對應樣本之間的間隔最大。
3、核函式
(1)如果不存在可以正確劃分兩類樣本的超平面,我們可將樣本從原始空間對映到一個更高維的特徵空間,使得樣本在這個特徵空間內線性可分。
【注:如果原始空間是有限維,即屬性數有限,那麼一定存在一個高位特徵空間使樣本可分。】
(2)令φ(x)表示將x對映後的特徵向量,則之前的式子可等價為:
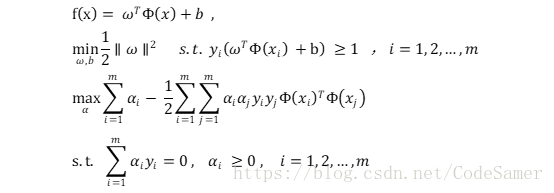
此時涉及到計算φ(xi)Tφ(xj) 較為複雜,需要用到核函式(kernelfunction) —k( , ):
k(xi, xj) = <φ(xi), φ(xj)> = φ(xi)Tφ(xj)
(3)只要一個對稱函式所對應的核矩陣是半正定的,它就能作為核函式使用;常用的核函式有:

(4)正則化可理解為一種“罰函式法”,即對不希望得到的結果施以懲罰,從而使得優化過程趨向於希望的目標。
4、軟間隔與正則化
(1)現實中由於大多數樣本不是線性可分的,所以引入軟間隔(softmargin),也就是允許支援向量機在一些樣本上出錯。
(2)此時優化目標可寫為:
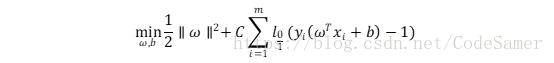
l0/1表示“0/1損失函式”:
由於l0/1的數學特性不太好,常用一些函式替代l0/1,稱為替代函式;通常是凸函式且是l0/1的上屆,常見的有hinge損失、指數損失、對率損失。
(3)支援向量機和對率迴歸的優化目標接近:
①對率迴歸的優勢在於其輸出具有自然的概率意義,即在給出預測標記的同時也給出了概率;而支援向量機的輸出不具有概率意義。
② 對率迴歸能直接用於多分類任務,支援向量機需要推廣。
5、支援向量迴歸(Support Vector Regression)
(1)SVR假設我們能容忍f(x)與y之間最多有ε的偏差,即晉檔f(x)與y之間的差別絕對值大於ε時才計算損失;相當於以f(x)為中心構建一個寬度為2ε的間隔帶。
(2)SVR問題形式化為:
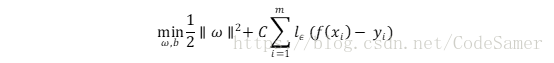
其中C為正則化常數,lε是ε-不敏感損失函式:
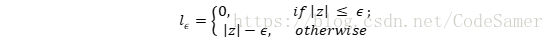
最終SVR的解為:
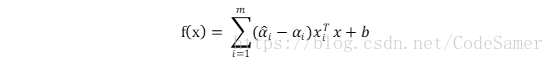
能使上式中(αi’- αi)≠0的樣本記為SVR的支援向量。
6、核方法(kernel method)
(1)表示定理(representer theorem)
(2)現實中,常通過“核化”(即引入核函式)來將線性學習器拓展為非線性學習器。
(3)支援向量機是針對二分類任務設計的,其求解通常是藉助於凸優化技術,核函式直接決定了支援向量機與核方法的最終效能,替代損失函式在機器學習中被廣泛應用。