
《機器學習(周志華)》習題10.1 答案
阿新 • • 發佈:2019-01-10
程式設計實現K鄰近分類器,在西瓜資料集[email protected](屬性只有密度與含糖率)上,比較其分類邊界與決策樹分類邊界之異同。
KNN用歐式距離計算,投票時根據距離加權,在訓練集上最小化錯誤率,選擇k=1時最優。
KNN決策面圖如下:
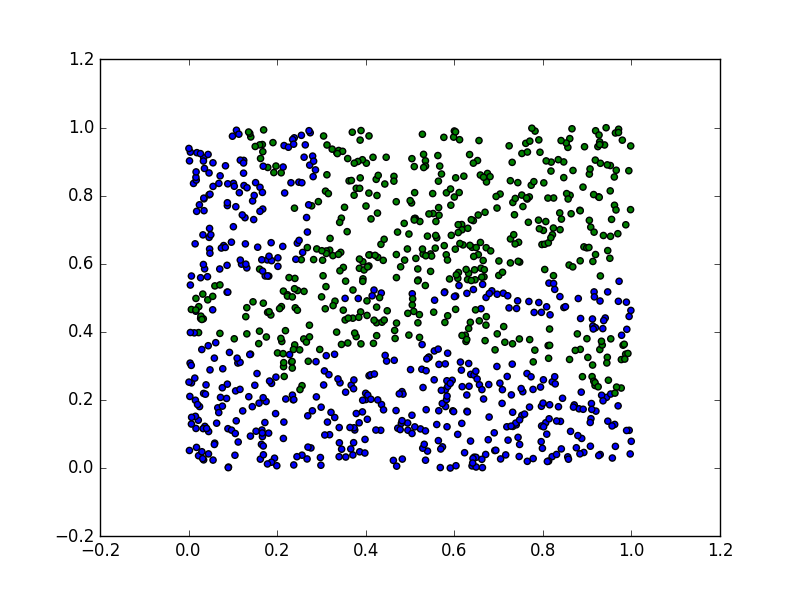
決策樹分類面如下(手繪)

將兩幅圖對比,可以看出分類邊界基本一致,但決策樹更絕對,不像knn部分不同類別的點還混在一起。
KNN和繪製決策面程式碼如下:
#coding: utf-8 import numpy as np from numpy import linalg as LA from numpy import random import matplotlib.pyplot as plt file = open('西瓜資料集3.csv'.decode('utf-8')) data = [raw.strip('\n').split(',')[-3:] for raw in file][1:] for i in range(len(data)): for j in [0, 1]: data[i][j] = float(data[i][j]) def predict(test, train, k): dist = map(lambda x: LA.norm(x), [np.array(raw[:-1])-np.array(test) for raw in train]) dist = [(dist[i], i) for i in range(len(dist))] dist = sorted(dist, key=lambda x: x[0])[1:] count = {} for i in range(min(k, len(dist))): idx = dist[i][1] label = train[idx][-1] count[label] = count.get(label, 0) + dist[i][0] return max(count, key=lambda x: count[x]) correct = 0 k = 1 for i in range(len(data)): res = predict(data[i][:-1], data, k) correct += 1 if res==data[i][-1] else 0 accuracy = float(correct) / len(data) print accuracy def plot_decision_boundary(train_data, k): test_data = random.rand(1000, 2) x = [i[0] for i in test_data] y = [i[1] for i in test_data] color = ['g' if predict(test, train_data, k)=='是' else 'b' for test in test_data] plt.scatter(y, x, c=color) plt.show() plot_decision_boundary(data, 1)