
Redis快取的使用和設計
1.快取的受益和成本
1.1 受益
1.可以加速讀寫:Redis是基於記憶體的資料來源,通過快取加速資料讀取速度
2.降低後端負載:後端伺服器通過前端快取降低負載,業務端使用Redis降低後端資料來源的負載等1.2 成本
1.資料不一致:後端資料來源中的資料快取到Redis,如果後端資料庫中的資料被更新時,根據更新策略不同,Redis快取層中的資料和資料來源的資料有時間視窗不一致
2.程式碼維護成本:多了一層快取邏輯,以前只需要讀取後端資料庫,現在還需要維護快取的讀寫以及Redis與資料庫的連線等
3.運維成本:例如Redis Cluster1.3 使用場景
1.降低後端負載:對高消耗的SQL,例如做排行榜的計算涉及到很多張資料表上資料的很複雜的實時計算,這種計算實際上沒有任何意義, 如果使用Redis快取,只需要第一次把計算結果寫入到Redis快取中,後續的計算直接在Redis中就可以了,join結果集/分組統計結果進行快取 2.加速請求響應:由於Redis中的資料是儲存在記憶體中的,利用Redis可以顯著的提高IO響應時間 3.大量寫請求合併為批量寫:如計數器先使用Redis進行累加,最後把結果批量寫入到後端資料庫中,而不用每次都更新到後端資料庫,有效降低後端資料庫的負載
2.快取的更新策略
快取中的資料有生命週期,需要定期更新和刪除,保證記憶體空間的合理使用以及快取資料的一致,快取資料需要根據合理的資料更新策略更新快取中的資料
- LRU/LFU/FIFO演算法剔除:Redis使用
maxmemory-policy,即Redis中的資料佔用的記憶體超過設定的最大記憶體時的操作策略 - 超時剔除:對快取的資料設定過期時間,超過過期時間自動刪除快取資料,然後再次進行快取,保證與資料庫中的資料一致
- 主動更新:開發者控制key的更新週期,當key在後端資料庫中發生更新時,向Redis主動傳送訊息,Redis接收到訊息對key進行更新或刪除
Redis的配置檔案中定義了下面的快取更新策略
volatile-lru -> remove the key with an expire set using an LRU algorithm # 根據LRU演算法刪除過期的key allkeys-lru -> remove any key according to the LRU algorithm # 根據LRU演算法刪除一些key volatile-random -> remove a random key with an expire set # 隨機刪除一些設定了過期時間的key allkeys-random -> remove a random key, any key # 從所有的key中隨機刪除一些key volatile-ttl -> remove the key with the nearest expire time (minor TTL) # 刪除一些快過期的key noeviction -> don't expire at all, just return an error on write operations # 不刪除任何key,在向Redis寫入key時返回一個錯誤,這將會佔用更多的記憶體
需要注意的是:with any of the above policies, Redis will return an error on write operations, when there are no suitable keys for eviction。即在上面的六種策略中,如果沒有key可以被刪除時,向Redis中寫入資料會返回一個error異常
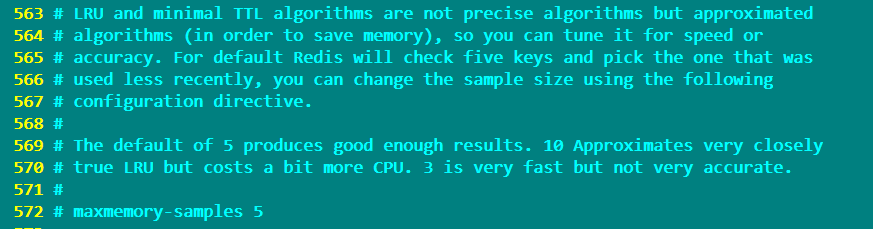
LRU和最小TTL演算法並不是精確的演算法,而是近似的演算法(為了節省記憶體)。因此可以根據速度或準確性對其進行優化設定,使用maxmemory-samples選項來設定這個值
預設情況下,maxmemory-samples的值設定為5,即Redis將檢查5個鍵並選擇使用最少的一個key,如果設定為10,非常接近真實的LRU演算法,但是另外消耗一些的CPU。如果設定為3則會加快Redis,但執行結果不夠準確。
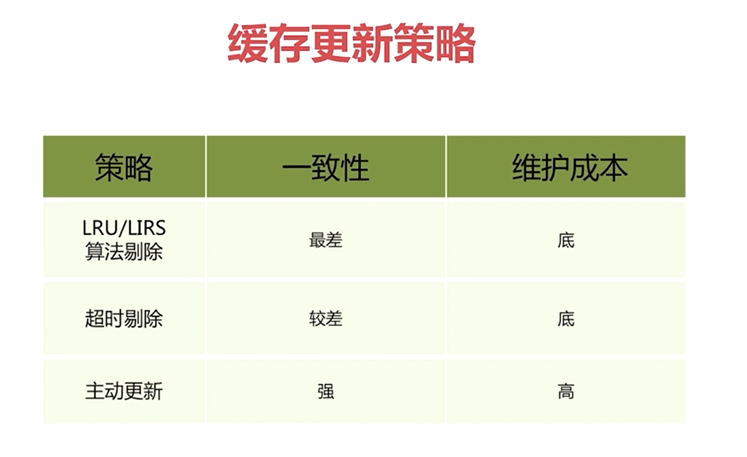
快取更新策略對比
2.1 對於快取的建議
- 對資料一致性要求不高,即真實資料和快取資料差別較大對業務影響不大情況下,可以採用最大記憶體和淘汰策略,記憶體使用量超過
maxmemory-policy時,自動刪除資料,而不會影響業務 - 對資料一致性要求較高,即真實資料和快取資料差別較大會影響業務情況下,可以採用超時剔除和主動更新結合策略,由最大記憶體和淘汰策略兜底。如果主動更新的功能出現問題失效,沒有把一些不必要的資料刪除時,Redis佔用的記憶體會越來越多,此時可以給一些有生命週期的key設定比較長的過期時間,然後設定
maxmemory和maxmemory-policy,來保證Redis佔用的記憶體超過設定的最大記憶體時刪除一些過期的key,來保證Redis的高可用 3.快取粒度控制

上圖中,使用Redis來做快取,底層使用MySQL來做資料儲存源,這種架構下大部分請求由Redis處理,少部分請求到達MySQL。
從MySQL中獲取一個使用者的所有資訊,然後快取到Redis的資料結構中。
此時需要面對一個問題:快取這個使用者的所有資料資訊,還是快取使用者需要的使用者資訊欄位。
可以從三個角度來考慮:
3.1 通用性
從通用性角度考慮,快取全量屬性更好。
當用戶資料表字段發生改變時,不需要修改程式就可以直接同步修改之後的使用者資訊到Redis快取中供使用者使用,但是用佔用更多的記憶體空間
3.2 佔用空間
從佔用空間的角度考慮,快取部分屬性更好.
同樣當用戶資料表字段發生改變時而使用者需要這個欄位資訊時,就需要修改程式原始碼來把修改之後的使用者資訊同步快取到Redis中,這種情況下佔用的記憶體空間比全量屬性佔用的記憶體空間要少
3.3 程式碼維護
從程式碼維護角度考慮,表面上全量屬性更好。
不管資料來源中的資料表結構如何改變,都會把所有的資料同步到Redis快取中,而不需要修改程式原始碼,但是在大多數情況下,不會使用到全量資料,只需要快取需要的資料就可以了,從記憶體空間消耗及效能方面考慮,使用部分屬性更好
3.4 總結
選擇快取屬性時,需要綜合考慮快取全量屬性還是部分屬性4.快取穿透優化
4.1 什麼叫快取穿透
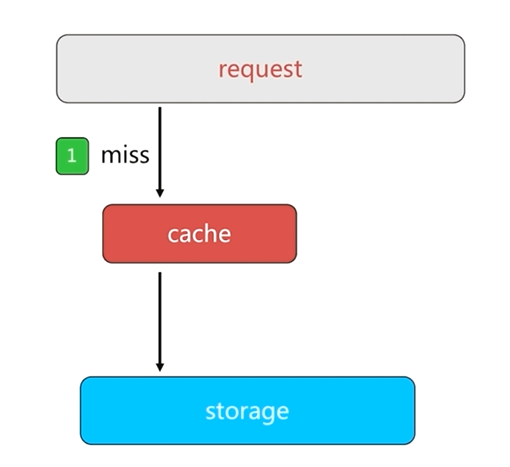
正常情況下,客戶端從快取中獲取資料,如果快取中沒有使用者請求需要的資料,就會讀取資料來源中的資料返回給客戶端,同時把資料回寫到快取中。這樣當下次客戶端再請求這個資料時,就可以直接從快取中獲取資料而不需要經過資料庫了。
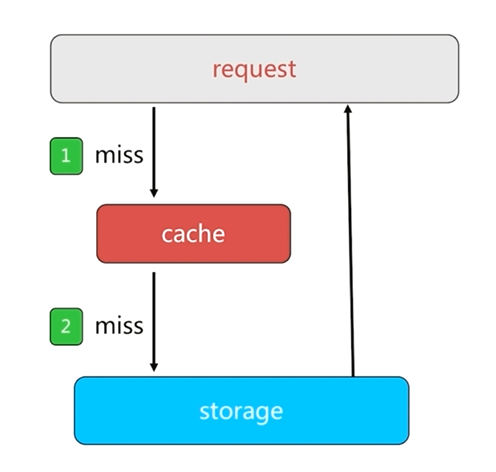
如果客戶端獲取一個數據源中沒有的key時,先從快取中獲取,獲取結果為null,然後到資料來源中獲取,同樣獲取結果為null,這樣所有的請求都會到達資料來源,這就是快取穿透的基本過程
快取的存在就是為了保護資料來源,快取穿透之後會對資料來源造成巨大的負載和壓力,這就失去了快取的意義。
4.2 快取穿透的原因
業務程式自身的問題:如無法對快取進行回寫等邏輯bug
惡意攻擊,爬蟲等4.3 快取穿透的發現
根據業務的響應時間來進行判斷,當業務的響應時間遠遠過正常情況下的響應時間時,很有可能就是快取穿透造成的
可以通過監控一些指標:總呼叫數,快取層命中數,儲存層命中數等發現快取穿透
4.4 快取穿透解決辦法
4.4.1 快取空物件
快取空物件是一種簡單粗暴的解決方法
當資料來源中沒有使用者請求需要的資料時,會請求資料來源,之前的做法是資料來源返回一個null,而快取中並不做回寫,快取空物件的做法就是把null回寫到快取中,暫時解決快取穿透帶來的壓力
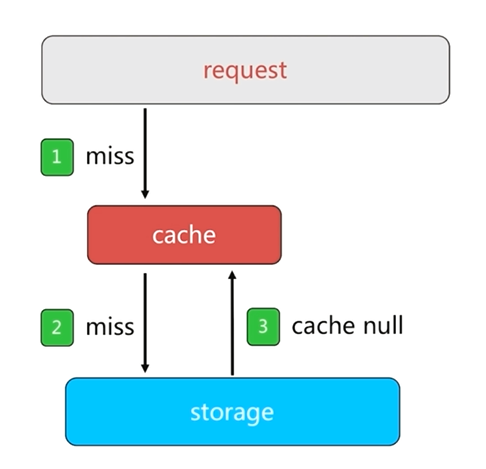
快取空物件會造成兩個問題
1.如果是惡意攻擊和爬蟲等,如果每次請求的資料都不一致,快取空物件時會在快取中設定很多的key,即使這些key的值都為空值,也會佔用很多的記憶體空間,此時可以為這個key設定過期時間來降低這樣的風險
2.快取空物件並設定過期時間,在這個時間內即使資料來源恢復正常,請求得到的結果仍然是null,造成快取層和儲存層資料短期不一致。這種情況下,可以通過訂閱釋出訊息來解決,當資料來源恢復正常時,會發布訊息,然後把正常資料快取到Redis中
4.4.2 布隆過濾器攔截
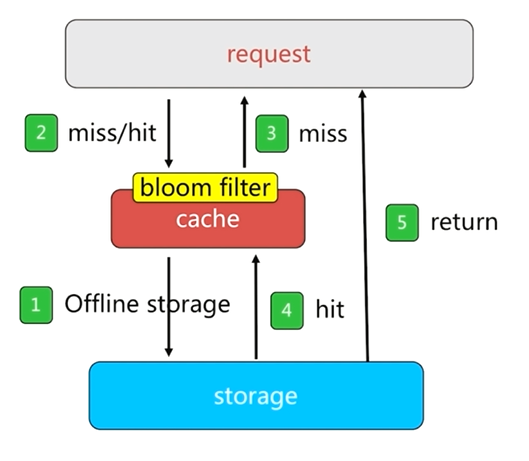
使用布隆過濾器可以通過佔用很小的記憶體來對資料進行過濾
布隆過濾器攔截是把所有的key或者離散資料儲存到布隆過濾器中,然後使用布隆過濾器在快取層之前再做一層攔截。
如果請求沒有被布隆過濾器攔截,則會到達快取層獲取需要的資料並返回,以達到實際效果
布隆過濾器對於固定的資料可以起到很好的效果,但是對於頻繁更新的資料,布隆過濾器的構建會面臨很多問題
4.4.3 快取穿透解決辦法對比
1.快取空物件程式碼層面比較簡單,但是需要一些額外的記憶體空間來儲存空物件,而且會有短時間內的資料不一致性
2.布隆過濾器需要特殊的使用場景,布隆過濾器需要維護一些單獨的程式碼,而且布隆過濾器也會佔用額外的很少的記憶體空間來實現資料的過濾5.無底洞問題優化
5.1 無底洞問題描述
2010年,Facebook已經有了3000個Memcache節點,Facebook發現問題:"加"Memcache節點,客戶端批量操作的效率不僅沒有提升,反而下降,這就是一個無底洞問題5.2 無底洞問題關鍵點
當只有一個節點時,執行一次mget只產生一次網路IO;而當節點增加到3個時,使用順序IO方式執行一次mget就會產生三次網路IO
同理,當節點越來越多,執行一次mget所需要的網路時間也越來越多,會對客戶端的執行效率帶來很大的下降
實際上網路IO由於擴容已經由原來的O(1)變成O(node)了,節點越多,並行執行一次mget命令所需要的時間就越長,如果序列執行mget命令所需要的時間就更多了。
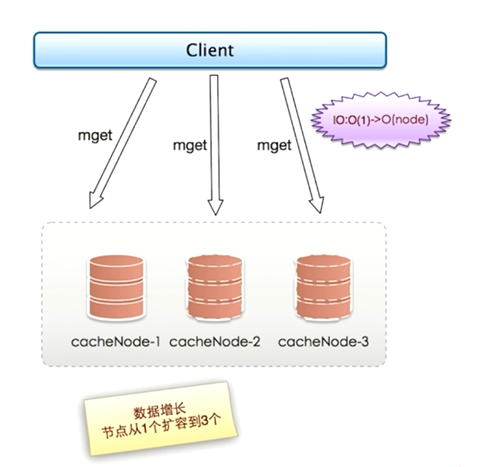
無底洞問題關鍵點即:
- 更多的機器 != 更多的效能
- 批量介面需求(mget和mset等):在執行mget和mset等命令時會面對的問題
資料增長與水平擴充套件需求等:隨著業務量越來越大,對於快取和資料來源儲存的需求也是越來越大,就需要對快取和資料來源進行擴容,即增加快取節點和資料來源節點,但是節點數量增多並不能帶來效能的提升,這是一個矛盾的問題
5.3 優化IO的方法
- 優化命令本身:例如執行慢查詢keys,hgetall bigkey等命令時,儘量選擇在快取節點壓力不大時執行
- 減少網路通訊次數,例如執行mget命令由原來的O(n)次網路時間縮減為O(node)次網路時間,
降低接入成本:例如客戶端長連線/連線池,NIO等
5.4 四種批量優化方法:
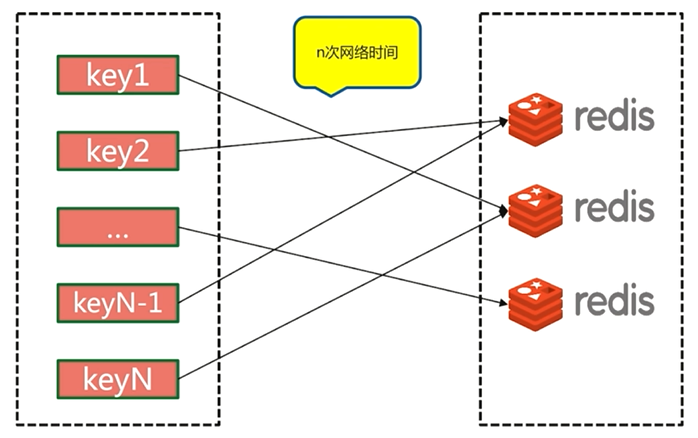
5.4.1 序列mget
序列mget需要n次網路時間
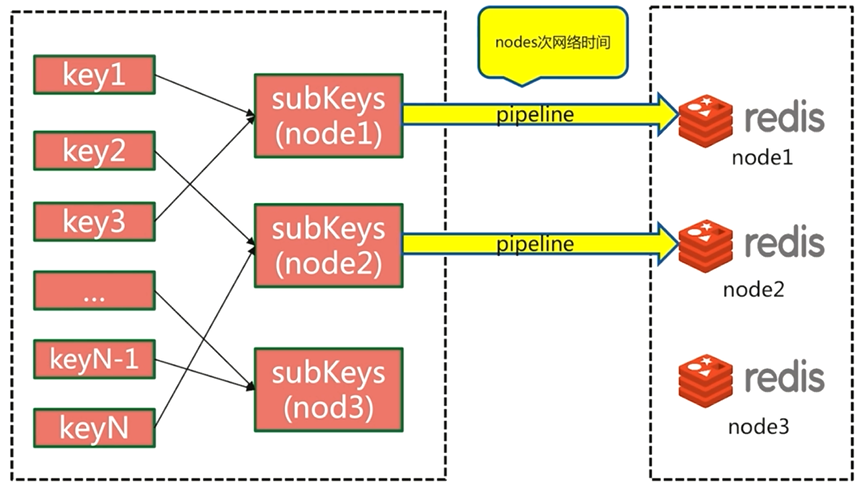
5.4.2 序列IO
由於客戶端對key進行重新組裝,所以把網路通訊時間降低到節點次O(node)
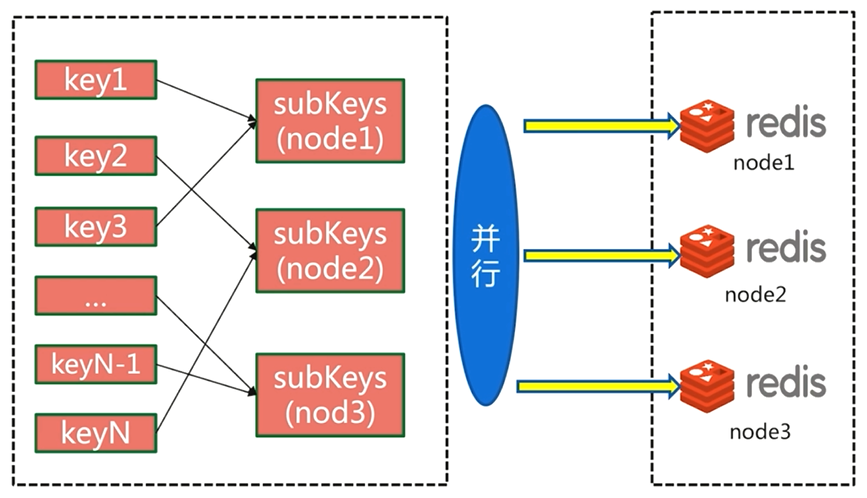
5.4.3 並行IO
並行IO也會在客戶端對key進行重新組裝,然後執行並行操作,所需要的網路時間為O(1)
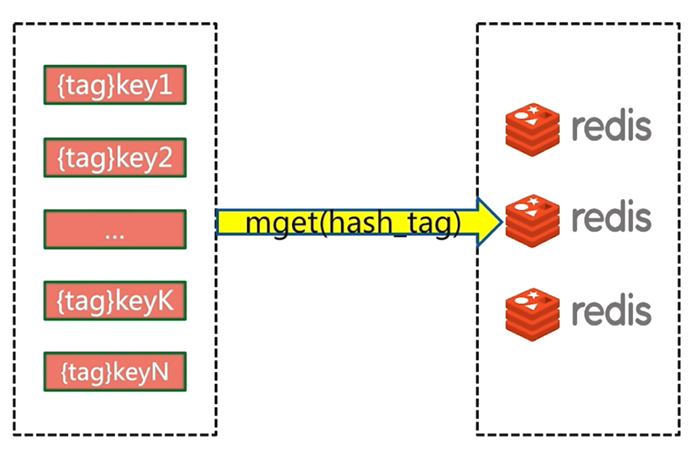
5.4.4 hash_tag
hash_tag會把所有的key都分配到一個節點,但是使用這種方法會遇到各種問題
5.5 四種優化方案的優缺點分析

6.執行key重建優化
6.1 快取重建過程描述
在正常情況下,客戶端傳送請求,會先到快取,從快取中獲取需要的資料,如果快取中並沒有需要資料,才會繼續向資料來源請求,從資料來源中獲取資料返回給客戶端並回寫到快取中,這就是快取的重建過程
6.2 快取重建問題描述
如果重建的是一個熱點key,使用者訪問量非常大。很多使用者傳送請求獲取資料,執行執行緒從快取中獲取資料,但是此時快取中並有這些資料,就會從資料來源中獲取資料,然後重建快取。
當快取重建完成,後續的訪問才會直接讀取快取數制並返回
在這個過程中,會有很多執行緒同時查詢並重建快取key,一方面會對資料來源造成很大壓力,另一方面也會加大響應的時間
6.3 解決快取重建的目標
減少快取重建次數:不要多次重建快取
資料儘可能一致:快取中的資料要儘可能與資料來源中的資料保持一致
減少潛在風險:可能造成死鎖或者執行緒池大量被夯住等情況6.4 快取重建解決方法
6.4.1 互斥鎖(mutex key)
互斥鎖是一種比較直觀和簡單的解決思路
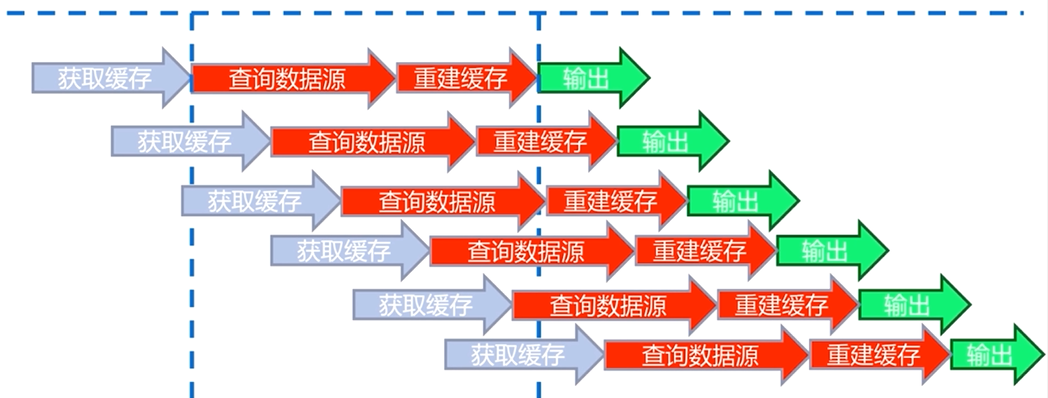
第一個使用者從快取中獲取資料,此時快取中並沒有使用者需要的資料,會從資料來源中重建快取,
使用者在從資料來源查詢獲取資料和重建快取的過程中加上一把鎖,當重建快取完成以後再把鎖解開,並返回
當第二個使用者也想從快取中獲取資料時,如果第一個使用者重建快取的過程還沒有結束,即鎖還沒有被解開時,就會等待,同樣後續訪問的使用者也經過這樣一個過程
當快取重建完成,鎖被解開,所有的使用者請求都從快取中獲取資料並輸出
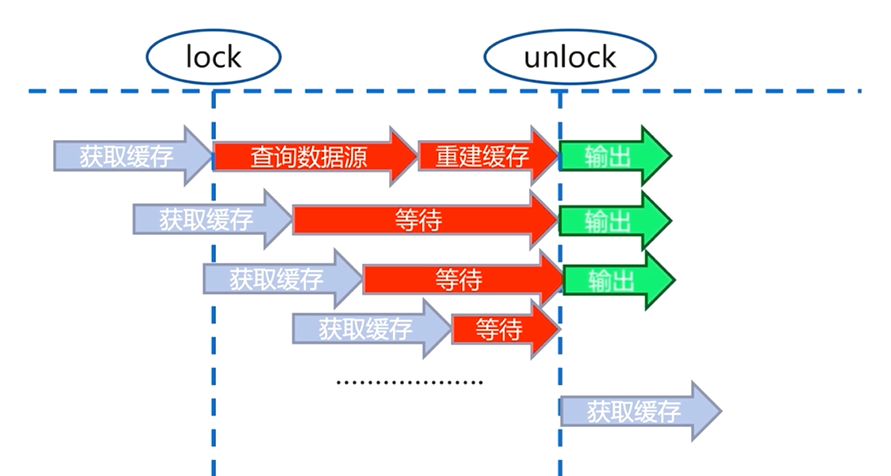
互斥鎖解決了快取大量重建的過程,但是在快取重建的過程中會有一個等待時間,大量執行緒被夯住,有可能造成死鎖的情況
6.4.2 資料永不過期
在快取層面,每一個key都不設定過期時間(沒有設定expire)
在功能層面中,為每個value新增邏輯過期時間,一旦發現超過邏輯過期時間後,會使用單獨的執行緒去構建快取需要注意的是
資料永不過期是一個非同步的過程,即使快取重建失敗,也不會造成執行緒夯住的問題
資料永不過期基本杜絕了熱點key的重建問題。
資料永不過期好處是:相比於使用互斥鎖的方案,不會使使用者產生一個等待的時間,而且可以保證只有一個執行緒來完成資料來源的查詢和快取的重建
資料永不過期的缺點:在快取重建完成之前,使用者從快取中得到的原來的資料有可能與從資料來源中的新資料不一致的情況
資料永不過期中設定邏輯過期時間,會為每一個key設定過期時間,會增加維護成本,佔用更多的記憶體空間。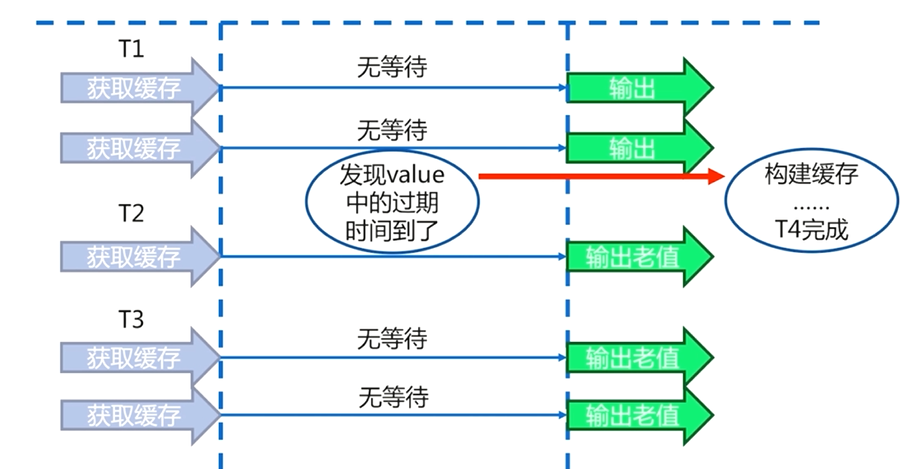
6.4 快取重建解決方法對比
