
機器學習:貝葉斯分類器,樸素貝葉斯,拉普拉斯平滑
阿新 • • 發佈:2018-12-31
數學基礎:
數學基礎是貝葉斯決策論Bayesian DecisionTheory,和傳統統計學概率定義不同。
頻率學派認為頻率是是自然屬性,客觀存在的。
貝葉斯學派,從觀察這出發,事物的客觀隨機性只是觀察者不知道結果,也就是觀察者的知識不完備,對於知情者而言,事物沒有隨機性,隨機性的根源不是來源於事物,而是來自於觀察者對事物的只是狀態。
從這個角度而言,貝葉斯學派是唯心主義,頻率學派是唯物主義。
貝葉斯決策論Bayesian DecisionTheory
貝葉斯決策是在某個先驗分佈下使得平均風險最小得決策。
引數估計
分為極大似然估計(Maximum Likelihood Estimate)和極大後驗概率估計(Maximum a posteriori estimation)
極大似然估計(Maximum Likelihood Estimate),使所有得樣本發生得概率最大,這個不考慮先驗概率得影響,屬於頻率派得做法.
極大後驗概率估計(Maximum a posteriori estimation),為貝葉斯學派得做法,加入了後驗概率概念,p( |X)為引數 在樣本X下得真實得出現概率,p( )為先驗概率。
可以看出極大後驗概率多了一個lnp( ,也就是增加了先驗。
樸素貝葉斯(Naive Bayes)
分為2個部分:樸素對應著獨立性假設,每個樣本都認為是相互獨立得,貝葉斯對應著後驗概率最大化。
貝葉斯估計在估計引數時使用了極大似然估計獲取先驗概率,做決策時使用得時MAP估計。
演算法描述如下:

簡單理解(X—>Y): 通過訓練集資料,先計算出Y得分佈概率,這個就是計算先驗概率,然後計算條件概率,也就是在已知分類Y得情況下為 的概率,就是X的某個屬性的概率,根據先驗概率和條件概率,可以求出 的發生概率,在哪種分類y= 下的概率最大, 就是哪種分類。
以下是西瓜書的描述,參考一下:

我們需要求的是使之最大的y=
,也就是哪個分類使之最大:


分為2步:
使用ML估計匯出模型的具體引數:先驗概率,條件概率
使用MAP估計作為模型的決策,輸出使後驗概率最大化的類別。
拉普拉斯平滑
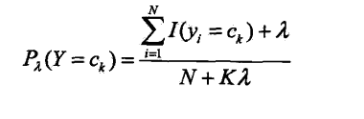
當
為0時極大似然估計,
為1為拉普拉斯平滑,K為x的第k個屬性可能的取值數目
# 核心陣列,記錄第i類資料的個數,cat為category
self._cat_counter = None
# 定義計算先驗概率的函式,lb為各個估計中的平滑項lamda
# lb的預設值為1,也就是預設使用拉普拉斯平滑
def get_prior_probability(self,lb =1):
return [(_c_num + lb) / (len(self._y) + lb*len(self._cat_counter)) for _c_num in self._cat_counter]