
[C語言]宣告解析器cdecl修改版
一、寫在前面
K&R曾經在書中承認,"C語言宣告的語法有時會帶來嚴重的問題。"。由於歷史原因(BCPL語言只有唯一一個型別——二進位制字),C語言宣告的語法在各種合理的組合下會變得晦澀難懂。不過在15級的優先順序規則加持下,C語言的宣告仍然有跡可循。這篇文章講解了一個通常取名為"cdecl"(不同於函式呼叫約定)的小型程式,該程式常用來解析C語言的宣告。本程式的基始版本來源於《C專家程式設計》p75,約140行程式碼。
博主在這個程式的基礎上,增加了兩個模組的功能:
1、struct/enum/union關鍵字後標籤
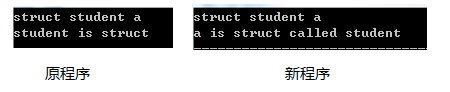
有如下宣告:struct student a; 在這個宣告中student是作為struct後可選的"結構標籤"出現的,a才是變數名稱。
2、函式引數的處理
源程式略過了函式引數處理的模組,在此,我們加入了此功能,儘管有些簡化。

二、宣告的組成部分
通常情況下來講,一個C語言宣告由三部分組成:型別說明符+宣告名稱(declarator)+分號,如int a;

三、優先順序規則
1、宣告從它的名字開始讀取,隨後按照優先順序順序依次讀取。
2、優先順序從高到低依次是:
2.1、宣告中被括號括起來的那部分
2,2、字尾操作符:
符號 () 表示這是一個函式
符號 [] 表示這是一個數組
2.3、字首操作符:*代表"指向...的指標"
3、如果const/volatile關鍵字後面緊跟型別說明符(如int),那麼該關鍵字作用於型別說明符。在其他情況下,const/volatile關鍵字作用於它左邊緊鄰的指標星號。
因此運用該規則分析如下宣告:char *(*c[10])();
第一步:找到變數名c
第二步:處理c後的[10],表示"c是一個有10個元素的陣列"
第三步:處理c前的*,表示"陣列元素為指標"
第四步:處理c所在括號後的括號,表示"陣列的元素型別是函式指標"
第五步:處理(*c[10])前的星號,表示"陣列元素指向的函式的返回值是一個指標"
第六步:處理char,表示"陣列元素指向的函式的返回值是一個指向char的指標"
綜上,該宣告表示:C是一個有10個元素的陣列,陣列元素型別是函式指標,其所指向的函式的返回值是一個指向char的指標。
四、程式執行流程
由於C語言宣告並不可以從左往右直接解析,所以我們需要一個棧結構來儲存在讀取到宣告名稱前的所有欄位,以便在讀取到id後再分析。
- struct token{
- char type;
- char string[MAXTOKENLEN];
- };
-
struct token stack[MAXTOKENS];
將所有欄位分為三類:名稱、型別以及限定詞,使用列舉型別,使之與char type對應。
- enum type_tag {
- IDENTIFIER,QUALIFIER,TYPE
-
};
主函式有兩大功能,一是找到identifier,二是處理剩下的宣告。
- int main (void)
- {
- read_to_first_identifier();
- deal_with_declarator();
- return 0;
-
}
第一個函式從左往右讀入輸入資料,一個讀取一個欄位(宣告的基本單位),若欄位不是id(識別符號),則將其壓入棧中,再讀取下一個欄位,直到讀取到欄位,該階段任務結束。
第二個函式在得到id後開始工作。根據語法規則,先讀取id後的字元,判斷其為陣列還是函式。在處理完id後的欄位後,再依次出棧解析前面的宣告。

五、各模組程式碼
5.1、讀取識別符號:read_to_first_identifier();
使用一個迴圈,每次讀取一個欄位,並判斷其是否為識別符號,是,則退出,並輸出。對於正在讀取的識別符號,使用一個全域性變數struct token thistoken儲存,在處理完該欄位後,若其不為識別符號,則壓入棧中。
- void read_to_first_identifier()
- {
- gettoken();
- while(thistoken.type != IDENTIFIER)
- {
- push(thistoken);
- gettoken();
- }
- printf("%s is ",thistoken.string);
- gettoken();
- }
5.2、讀取各欄位:gettoken();
我們假設各個含有英文字母的欄位(如型別說明符、識別符號等)都以空格隔開,因此我們可以從我們讀取到的第一個非空字元開始,判斷它的型別。識別符號前的符號有一下幾種:說明符、指標(*)。所以我們將其單獨處理。
- void gettoken()
- {
- char *p = thistoken.string;
- while((*p = getchar()) == ' ');
- if(isalnum(*p))
- {
- while(isalnum(*++p = getchar()));
- ungetc(*p,stdin);
- *p = '\0';
- thistoken.type = classify_string();
- return ;
- }
- if(*p == '*')
- {
- strcpy(thistoken.string,"pointer to");
- thistoken.type = '*';
- return ;
- }
- thistoken.string[1] = '\0';
- thistoken.type = *p;
- return ;
- }
對於識別符號及宣告符,我們在讀取完一個欄位後就判斷其型別。對於'*'或其他符號('(''['等),則直接用符號本身作為其型別。
5.3、解析欄位型別:classify_string ();
在我們提取到完整的英文/數字欄位後,通過該函式來推斷其型別。通過strcmp()函式,將其與各個型別說明符對比,如果一樣,則返回型別說明符,如type/qualifier。與因為用strcmp()函式來比較字串時,字串相等,函式返回值為0。為了在相等時得到我們想要的真值,就需要對其進行取反。除了用"!"外,用巨集來解決更方便。
- #define STRCMP(a,R,b) (strcmp(a,b) R 0)
因此,字串的比較就成了如下形式:
- if(STRCMP(s,==,"void"))
- return TYPE;
如果讀取到的欄位並非限定符或者說明符,則認為其為識別符號。
- enum type_tag classify_string()
- {
- char *s = thistoken.string;
- if(STRCMP(s,==,"const"))
- {
- strcpy(s,"read-only");
- return QUALIFIER;
- }
- if(STRCMP(s,==,"volatile"))
- return QUALIFIER;
- if(STRCMP(s,==,"void"))
- return TYPE;
- if(STRCMP(s,==,"char"))
- return TYPE;
- if(STRCMP(s,==,"singed"))
- return TYPE;
- if(STRCMP(s,==,"unsinged"))
- return TYPE;
- if(STRCMP(s,==,"short"))
- return TYPE;
- if(STRCMP(s,==,"int"))
- return TYPE;
- if(STRCMP(s,==,"long"))
- return TYPE;
- if(STRCMP(s,==,"float"))
- return TYPE;
- if(STRCMP(s,==,"double"))
- return TYPE;
- if(STRCMP(s,==,"struct"))
- {
- check_type_or_id(s);
- return TYPE;
- }
- if(STRCMP(s,==,"union"))
- {
- check_type_or_id(s);
- return TYPE;
- }
- if(STRCMP(s,==,"enum"))
- {
- check_type_or_id(s);
- return TYPE;
- }
- return IDENTIFIER;
- }
5.4、解析欄位型別:check_type_or_id();
對於型別struct/type/enum,在宣告該型別變數時,型別後的欄位極有可能是該關鍵字後可選的"結構標籤"。如宣告struct student xxx;,student是作為一個結構標籤存在。該宣告與struct student {內容…}xxx;一致。所以在判斷student時,需要看它後面欄位的型別。如果struct後兩個欄位都為識別符號,則最後一個識別符號才是真的識別符號,型別struct/type/enum後的欄位則是該型別的另一個名字,如:xxx是一個叫student的結構體。
在該模組的實現上,則是在讀取到結構struct/type/enum時,再讀取其後的兩個標籤,再判斷,並將真正的識別符號及其後的內容返回到輸入流中。
- void check_type_or_id(char *s)
- {
- char temp[MAXTOKENLEN] = {'\0'};
- struct token temp_struct_one = thistoken;
- gettoken();
- struct token temp_struct = thistoken;
- gettoken();
- struct token temp_struct3 = thistoken;
- if(thistoken.type==IDENTIFIER)
- {
- strcat(temp,temp_struct_one.string);
- strcat(temp," called ");
- strcat(temp,temp_struct.string);
- strcpy(s,temp);
- thistoken = temp_struct3;
- strcpy(temp_struct_one.string,temp);
- }
- else
- {
- thistoken = temp_struct;
- for(int i = strlen(temp_struct3.string)-1;i>=0;i--)
- {
- ungetc(temp_struct3.string[i],stdin);
- }
- }
- if(thistoken.type>=0 && thistoken.type<=2)
- {
- for(int i = strlen(thistoken.string)-1;i>=0;i--)
- {
- ungetc(thistoken.string[i],stdin);
- }
- }
- thistoken = temp_struct_one;
- }
5.5、宣告的處理:deal_with_declarator();
在確定了識別符號之後,我們就可以處理各種宣告、修飾符了。依據優先順序規則,我們先需要觀察識別符號後的符號,以確定其是否是陣列/函式;其後還需要處理指標,最後再處理先前被壓棧的符號。
在開始該階段的處理之前,我們觀察read_to_first_identifier()函式,在該函式的最後一行,我們確定了識別符號後,有進行了一次gettoken(),這次呼叫即將識別符號後的符號讀入,因此現在在函式開頭我們就可以使用switch()直接選擇要處理的情況。
- void deal_with_declarator()
- {
- switch(thistoken.type)
- {
- case '[':
- deal_with_arrays();
- break;
- case '(':
- deal_with_function_args();
- break;
- }
- deal_with_pointers();
- while(top >= 0)
- {
- if(stack[top].type == '(')
- {
- pop;
- gettoken();
- deal_with_declarator();
- }
- else
- {
- printf("%s ",pop.string);
- }
- }
- }
5.6、函式引數的處理:deal_with_function_args();
在《C專家程式設計》中,沒有對函式引數進行處理。在此,我加入了對引數的簡單處理。簡單處理也即,對於複雜宣告的引數,並沒有能正確的處理。在我寫這個模組時,我有一種對整個程式重構的想法,即將宣告的解析抽象成一個獨立的函式,現在程式裡全域性變數對函式功能的拓展限制太大了。
該函式的流程則是,將括號內的欄位全部讀取並輸出,遇到','重新讀取輸出。普通單一的型別說明符可直接輸出(如 int a),而int *a;則無法如此簡單處理。由於輸出使用的是英語,所以該函式大部分的程式碼都是在處理不同引數時英語表述的語法問題,如但單引數的'parameter is'與多引數的'parameters are'等語法細節。處理粗糙,不看也罷。
- void deal_with_function_args()
- {
- char str[MAXTOKENLEN] = {'\0'};
- char para[MAXTOKENLEN] = {'\0'};
- bool flag_no_para = true;
- bool para_is_one = true;
- strcat(str,"function");
- gettoken();
- if(thistoken.type != ')')
- {
- strcat(str," whose parameter");
- flag_no_para = false;
- }
- while(thistoken.type != ')')
- {
- if(thistoken.string[0] == ',')
- {
- if(para_is_one == true)
- {
- strcat(str,"s are");
- para_is_one = false;
- }
- strcat(para," and");
- }
- else
- {
- strcat(para," ");
- strcat(para,thistoken.string);
- }
- gettoken();
- }
- if(para_is_one == true && flag_no_para== false)
- {
- strcat(str," is");
- }
- strcat(str,para);
- gettoken();
- if(flag_no_para == true)
- {
- strcat(str," returning ");
- }
- else
- {
- strcat(str,",it returns ");
- }
- printf("%s",str);
- }
六、一些宣告的解析結果



七、寫在後面
新增的功能並不盡如人意,不過也將這次的修改探索總結出來,以供後來者學習,希望後來者少踩一些坑,老老實實重構去哈哈哈。
最後….預祝新年快樂~
原始碼地址:C語言宣告解析器修改版原始碼