
在Hadoop平臺中執行MapReduce WordCount程式
阿新 • • 發佈:2018-12-31
一、實驗名稱
在Hadoop平臺執行MapReduce程式
二、實驗過程
1.設定環境變數
(1)編輯~/.bashrc檔案,新增下列語句
export HADOOP_HOME=/usr/local/hadoop
export CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar:$($HADOOP_HOME/bin/hadoopclasspath):$CLASSPATH
(2)source ~/.bashrc使環境變數生效
2.編譯Java檔案
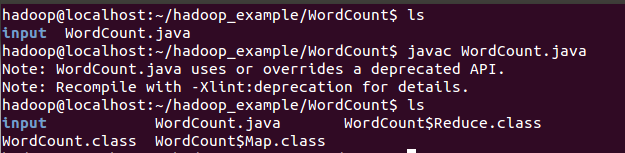
3.將class檔案打包生成jar檔案
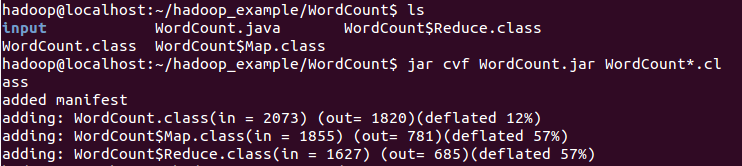
4.開啟HDFS、YARN服務
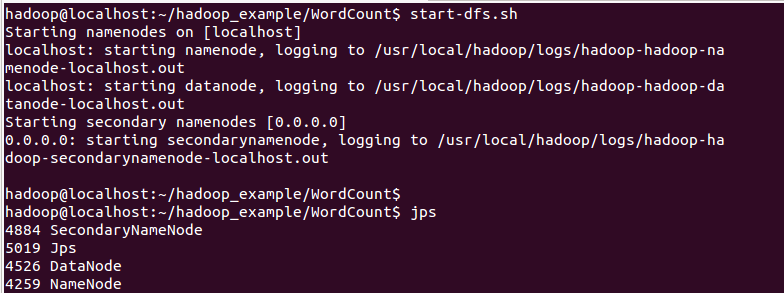
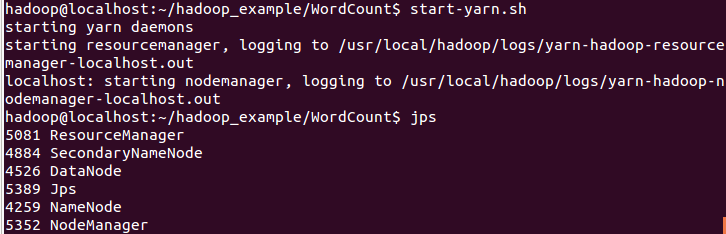
5.5.上傳檔案計數檔案至HDFS檔案系統中
hdfs相關操作:
hdfs dfs -rm 刪除HDFS檔案系統中的檔案或目錄
hdfs dfs -mkdir 建立目錄
hdfs dfs -ls 列出目錄下所有檔案
hdfs dfs -put 上傳檔案到HDFS
hdfs dfs -get 從HDFS下載檔案到本地
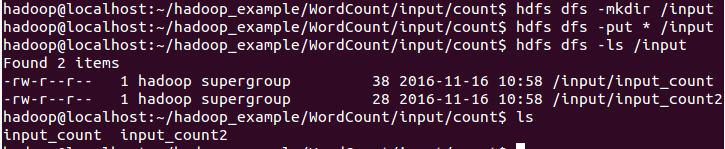
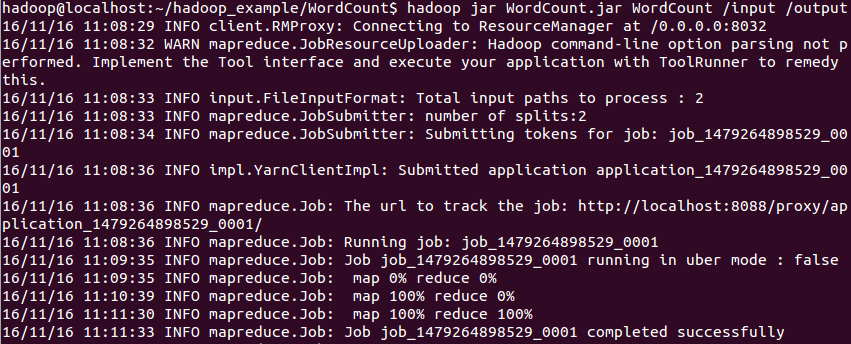
6.在Hadoop平臺中執行MapReduce Job
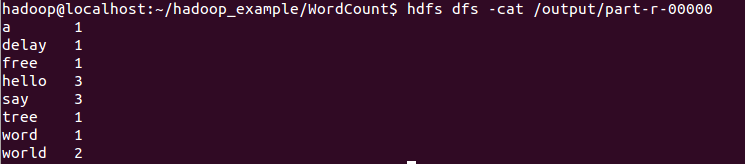
7.檢視執行結果
8.具體程式
import java.io.IOException; import java.util.*; import org.apache.hadoop.fs.Path; import org.apache.hadoop.conf.*; import org.apache.hadoop.io.*; import org.apache.hadoop.mapreduce.*; import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; import org.apache.hadoop.mapreduce.lib.input.TextInputFormat; import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; import org.apache.hadoop.mapreduce.lib.output.TextOutputFormat; public class WordCount { public static class Map extends Mapper<LongWritable, Text, Text, IntWritable> { private final static IntWritable one = new IntWritable(1); private Text word = new Text(); public void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException { String line = value.toString(); StringTokenizer tokenizer = new StringTokenizer(line); while (tokenizer.hasMoreTokens()) { word.set(tokenizer.nextToken()); context.write(word, one); } } } public static class Reduce extends Reducer<Text, IntWritable, Text, IntWritable> { public void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException { int sum = 0; for (IntWritable val : values) { sum += val.get(); } context.write(key, new IntWritable(sum)); } } public static void main(String[] args) throws Exception { Configuration conf = new Configuration(); Job job = new Job(conf, "wordcount"); job.setOutputKeyClass(Text.class); job.setOutputValueClass(IntWritable.class); job.setMapperClass(Map.class); job.setReducerClass(Reduce.class); job.setInputFormatClass(TextInputFormat.class); job.setOutputFormatClass(TextOutputFormat.class); FileInputFormat.addInputPath(job, new Path(args[0])); FileOutputFormat.setOutputPath(job, new Path(args[1])); job.waitForCompletion(true); } }