
# 從零開始搭建Hadoop2.7.1的分散式叢集
Hadoop 2.7.1 (2015-7-6更新),Hadoop的環境配置不是特別的複雜,但是確實有很多細節需要注意,不然會造成許多配置錯誤的情況。儘量保證一次配置正確防止反覆修改。
網上教程有很多關於Hadoop配置的,但是每一個教程都對應了一個版本資訊,有一些教程也存在很大的問題,配置環境,系統環境都沒說清楚。在此我將記錄下來從零搭建Hadoop2.7.1的過程,以及搭建過程中所遇到的一些問題。
一 操作環境說明
1.1 :作業系統: window8.1
1.2 :虛擬機器版本:VMware12
二 材料準備
2.1 ubuntu-14.10-desktop-amd64.iso (Ubuntu 光碟映像)
2.2 jdk-8u65-linux-x64.gz (Java 環境包)
2.3 hadoop-2.7.1.tar.gz (Hadoop 環境包)
三 搭建開始
3.1 Vmware 建立虛擬機器
根據Hadoop的排程規則,我們將使用VMware 12 載入 ubuntu….iso來建立三個Ubuntu 虛擬機器。建立用典型安裝即可,以下是虛擬機器的一些資訊
虛擬機器1:Master Ubuntu 14.10 64bit
虛擬機器2:Slave1 Ubuntu 14.10 64bit
虛擬機器3:Slave2 Ubuntu 14.10 64bit
以下操作將需要在所有配置機器上進行
3.2 解壓檔案
將jdk-8u65-linux-x64.gz 和hadoop-2.7.1.tar.gz 拷貝到3臺虛擬機器的一個資料夾中。我這裡拷貝到了Home/Download資料夾中, 然後右鍵選擇 Extract Here. (當然也可以zxvf)
3.3 配置JAVA
把jdk-8u65-linux-x64 重新命名為jdk-8u65-linux-x64.tar.gz 並右鍵Extract Here,生成檔案jdk 1.8.0_65
開啟終端輸入命令:
sudo mkdir /usr/lib/jvm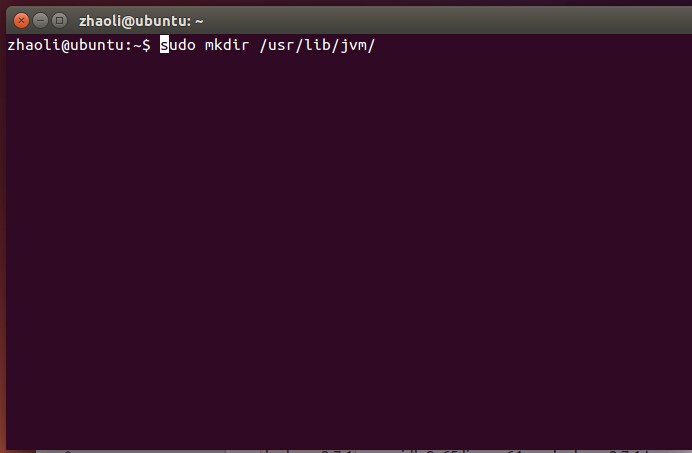
sudo cp -r Downloads/jdk1.8.0 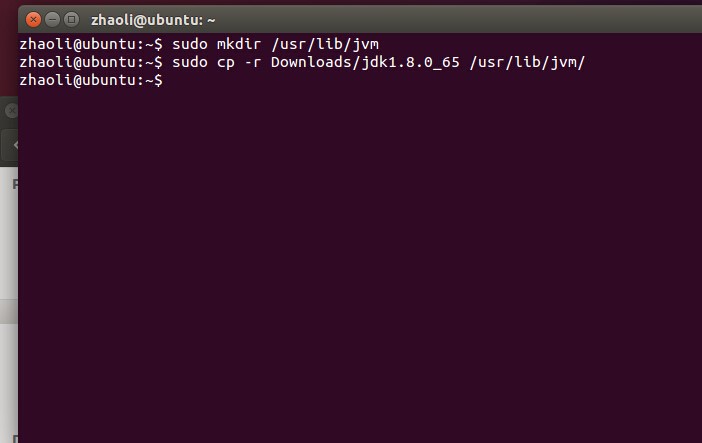
新增環境變數
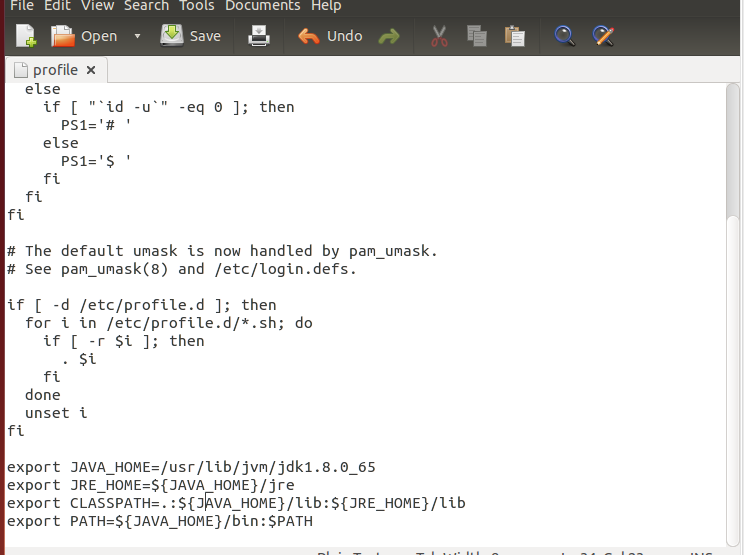
sudo gedit /etc/profile在末尾加上四行:
export JAVA_HOME=/usr/lib/jvm/jdk1.8.0_65
export JRE_HOME=${JAVA_HOME}/jre
export CLASSPATH=.:${JAVA_HOME}/lib:${JRE_HOME}/lib
export PATH=${JAVA_HOME}/bin:$PATH
輸如命令使環境生效
source /etc/profile輸如命令檢視環境是否配置成功
java –version
出現如上資訊說明配置成功
3.4 SSH 安裝以及配置
更新apt (由於是新系統可能會花一些時間)
sudo apt-get update安裝ssh
sudo apt-get install openssh-server已有ssh或者安裝成功了的輸入命令
ps -e | grep ssh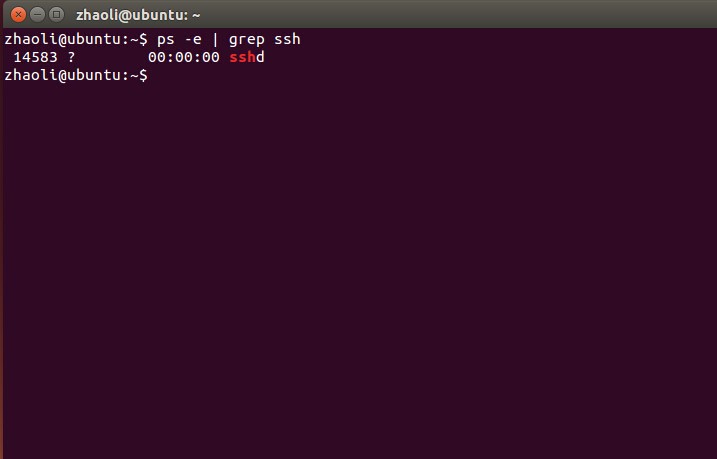
如果用的是和我相同的ubuntu版本安裝會遇到問題。安裝過程中遇到404 Not Find(如果沒有則跳過直接驗證SSH)
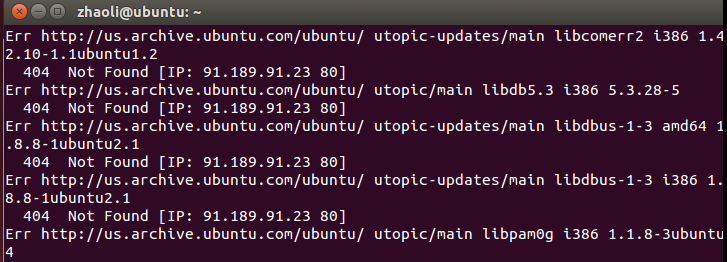
下載sources.list 存入Home目錄下輸入命令覆蓋原檔案
sudo cp sources.list /etc/apt/sources.list更行apt-get
sudo apt-get update再次安裝ssh
sudo apt-get install openssh-server如遇到版本問題則參考以下命令安裝
sudo apt-get install openssh-client=1:6.6p1-2ubuntu1驗證SSH是否成功安裝輸入
ssh localhost出現以下提示說明安裝成功

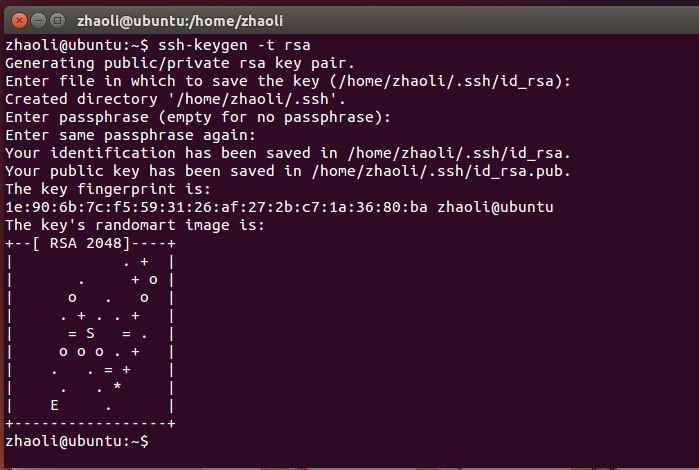
生成金鑰Pair
ssh-keygen –t rsa輸入後一直回車選擇預設即可
mater主機中輸入命令複製一份公鑰到home中
cp .ssh/id_rsa.pub ~/id_rsa_master.pub把master的home目錄下的id_rsa_master.pub拷到slave1,slave2的home下
slave1和 slave2的home目錄下分別輸入命令
cat id_rsa_master.pub >> .ssh/authorized_keys至此實現了mater對slave1, slave2的無密碼登陸
以下配置將僅僅在master主機上進行
3.5 配置 Hadoop
(為了配置方便,將解壓縮好的hadoop-2.7.1資料夾拷貝到home根目錄下面)
在hadoop-2.7.1資料夾下建立檔案,輸入
mkdir hadoop-2.7.1/tmp
mkdir hadoop-2.7.1/hdfs
mkdir hadoop-2.7.1/hdfs/name
mkdir hadoop-2.7.1/hdfs/data輸入命令檢視ip地址
ifconfig -a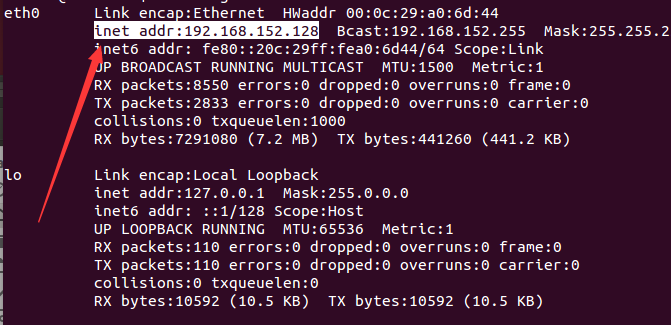
eg. 我所使用的IP地址
虛擬機器1:Master 192.168.152.128
虛擬機器2:Slave1 192.168.152.129
虛擬機器3:Slave2 192.168.152.130
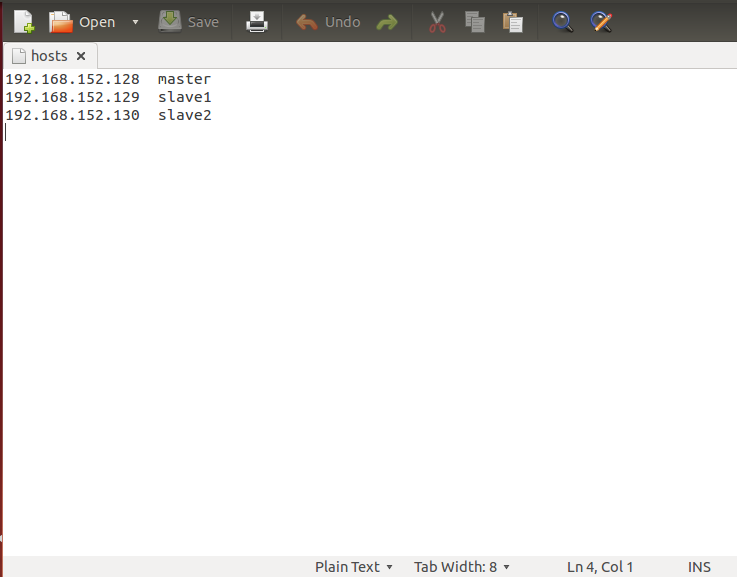
修改hosts
sudo gedit /etc/hosts具體IP地址由上面給出,可根據自己的配置情況自行調整
為了方便修改hostname
sudo gedit /etc/hostnamemaster 的改為 master
slave1 的改為 slave1
slave2 的改為 slave2
修改環境變數
cd ~/hadoop-2.7.1/(1)hadoop-env.sh
gedit etc/hadoop/hadoop-env.sh找到JAVA_HOME=… 一行修改為JAVA HOME的路徑
export JAVA_HOME=/usr/lib/jvm/jdk1.8.0_65(2)core-site.xml
gedit etc/hadoop/core-site.xml在configuration標籤中新增
<property>
<name>fs.defaultFS</name>
<value>hdfs://master:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>file:/home/zhaoli/hadoop-2.7.1/tmp</value>
</property>
(3)mapred-site.xml
建立並編輯
cp etc/hadoop/mapred-site.xml.template etc/hadoop/mapred-site.xml
gedit etc/hadoop/mapred-site.xml
在configuration標籤中新增
<property>
<name>fs.defaultFS</name>
<value>hdfs://master:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>file:/home/zhaoli/hadoop-2.7.1/tmp</value>
</property>
(4)hdfs-site.xml
gedit etc/hadoop/hdfs-site.xml在configuration標籤中新增
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/home/zhaoli/hadoop-2.7.1/hdfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/home/zhaoli/hadoop-2.7.1/hdfs/data</value>
</property>
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>master:9001</value>
</property>
(5)yarn-site.xml
gedit etc/hadoop/yarn-site.xml在configuration標籤中新增
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.auxservices.mapreduce.shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
<property>
<name>yarn.resourcemanager.address</name>
<value>master:8032</value>
</property>
<property>
<name>yarn.resourcemanager.scheduler.address</name>
<value>master:8030</value>
</property>
<property>
<name>yarn.resourcemanager.resource-tracker.address</name>
<value>master:8031</value>
</property>
<property>
<name>yarn.resourcemanager.admin.address</name>
<value>master:8033</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address</name>
<value>master:8088</value>
</property>
(6)slaves檔案
gedit etc/hadoop/slaves刪除原有內容,根據配置修改,此處為
slave1
slave2
分發配置好的hadoop資料夾到slave1, slave2
前提是設定好ssh
scp -r hadoop-2.7.1 zhaoli@slave1:~/
scp -r hadoop-2.7.1 zhaoli@slave2:~/
格式化hdfs
進入hadoop home目錄
bin/hdfs namenode -format啟動叢集
sbin/start-all.sh啟動後分別在master, slave下輸入jps檢視程序
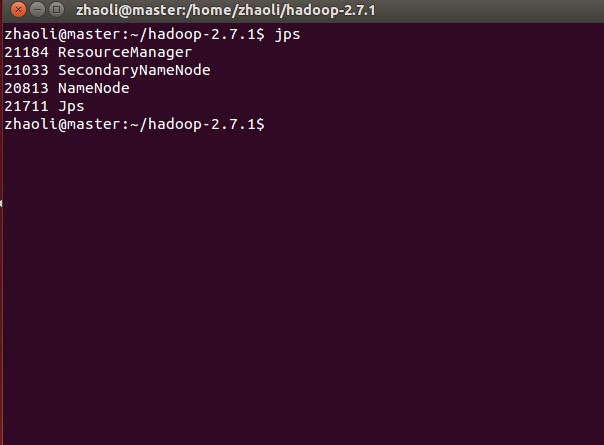
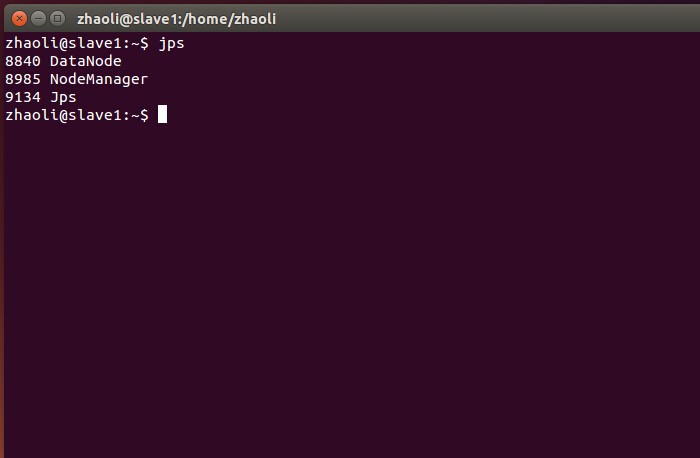
如上則說明啟動成功
執行wordcount測試叢集
進入hadoop home目錄
在hdfs(分散式檔案系統)中建立一個名為input的資料夾
bin/hadoop fs –mkdir /input檢視檔案是否被建立
bin/hadoop fs –ls /hadoop home 下建立一個inputfile 資料夾,並在inputfile裡建立兩個檔案
in1.txt
Hello world hello hadoop
in2.txt
Hello Hadoop hello whatever
上傳兩個檔案進input
bin/hadoop fs -put inputfiles/*.txt /input檢視輸入檔案是否傳入
bin/hadoop fs -ls /input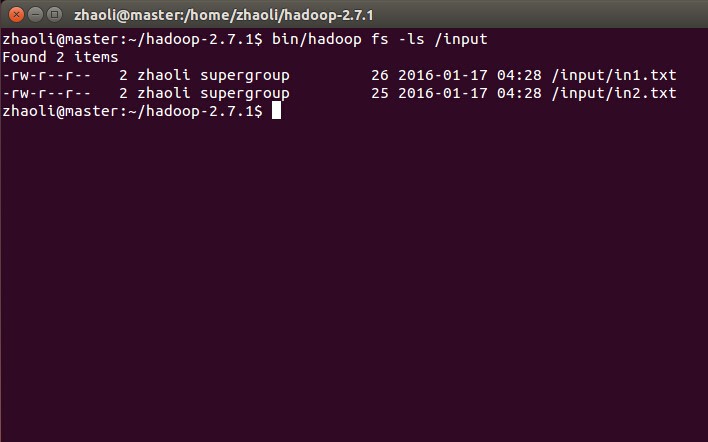
用hadoop jar命令執行Hadoop自帶的wordcount
bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.1.jar wordcount /input /output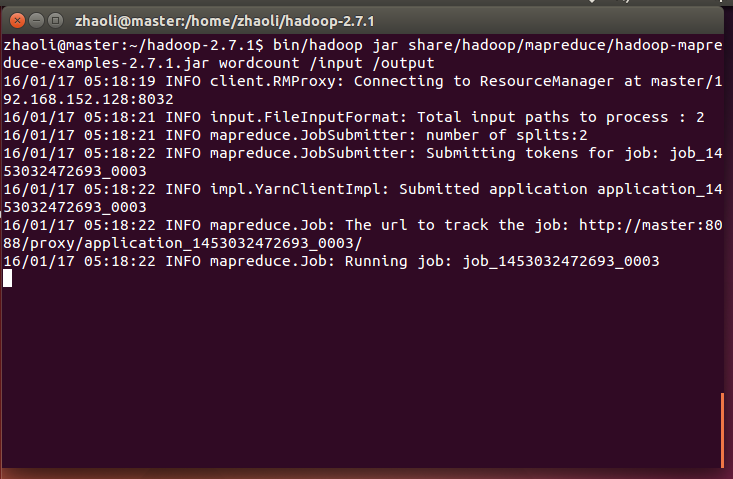
程式開始執行,成功後檢視輸出資料夾
bin/hadoop fs -ls /output
檢視結果
bin/hadoop fs -cat /output/part-r-00000
至此hadoop分散式叢集配置完成!
以上是對Hadoop的配置資訊,希望能夠儘可能的寫得詳細,但是終究不能概括所有的bug。之前也看了很多叢集搭建的書和部落格,還是遇到了很多困難,本次從零開始配置也是為了排除一些干擾,希望能夠幫助到和我一樣摸索前進的人吧。