CentOS7 從零開始搭建 Hadoop2.7叢集
阿新 • • 發佈:2019-02-06
序言
- 準備四臺安裝好CentOS Minimal 的機器,且已經配置網路環境。(只需要記住四臺機器的IP地址,主機名後面設定)
- 機器1: 主機名 node, IP: 192.168.169.131
- 機器1: 主機名 node1, IP: 192.168.169.133
- 機器1: 主機名 node2, IP: 192.168.169.132
- 機器1: 主機名 node3, IP: 192.168.169.134
檔案準備
新增使用者組與使用者
groupadd hadoop useradd -d /home/hadoop -g hadoop hadoop複製本機檔案到目標機器
pscp.exe -pw 12345678 hadoop-2.7.3.tar.gz root@192.168.169.131:/usr/local pscp.exe -pw 12345678 spark-2.0.0-bin-hadoop2.7.tgz root@192.168.169.131:/usr/local解壓並複製檔案
tar -zxvf /usr/local/jdk-8u101-linux-x64.tar.gz #重新命名 mv /usr/local/jdk1.8.0_101 /usr/local/jdk1.8 tar -zxvf /usr/local/hadoop-2.7.3.tar.gz mv /usr/local/hadoop-2.7.3 /home/hadoop/hadoop2.7
許可權修改
修改夾所有者
chmod -R hadoop:hadoop /home/hadoop/hadoop2.7修改組執行許可權
chmod -R g=rwx /home/hadoop/hadoop2.7
配置系統環境
配置系統變數
echo 'export JAVA_HOME=/usr/local/jdk1.8' >> /etc/profile echo 'export JRE_HOME=$JAVA_HOME/jre' >> /etc/profile echo 'export CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar'>> /etc/profile echo 'export HADOOP_HOME=${hadoopFolder}' >> /etc/profile echo 'export PATH=$HADOOP_HOME/bin:$PATH' >> /etc/profile source /etc/profile配置主機域名
hostname node #當前機器名稱 echo NETWORKING=yes >> /etc/sysconfig/network echo HOSTNAME=node >> /etc/sysconfig/network #當前機器名稱,避免重啟主機名失效 echo '192.168.169.131 node' >> /etc/hosts echo '192.168.169.133 node1' >> /etc/hosts echo '192.168.169.132 node2' >> /etc/hosts echo '192.168.169.134 node3' >> /etc/hosts關閉防火牆
systemctl stop firewalld.service systemctl disable firewalld.service
配置Hadoop叢集
修改配置檔案
sed -i 's/\${JAVA_HOME}/\/usr\/local\/jdk1.8\//' $HADOOP_HOME/etc/hadoop/hadoop-env.sh sed -i 's/# export JAVA_HOME=\/home\/y\/libexec\/jdk1.6.0\//export JAVA_HOME=\/usr\/local\/jdk1.8\//' $HADOOP_HOME/etc/hadoop/yarn-env.sh sed -i 's/# export JAVA_HOME=\/home\/y\/libexec\/jdk1.6.0\//export JAVA_HOME=\/usr\/local\/jdk1.8\//' $HADOOP_HOME/etc/hadoop/mapred-env.sh配置從節點主機名
echo node1 > $HADOOP_HOME/etc/hadoop/slaves echo node2 >> $HADOOP_HOME/etc/hadoop/slaves echo node3 >> $HADOOP_HOME/etc/hadoop/slaves拷貝檔案並覆蓋以下檔案
- /home/hadoop/hadoop2.7/etc/hadoop/core-site.xml
<configuration> <property> <name>fs.defaultFS</name> <value>hdfs://node:9000/</value> <description>namenode settings</description> </property> <property> <name>hadoop.tmp.dir</name> <value>/home/hadoop/tmp/hadoop-${user.name}</value> <description> temp folder </description> </property> <property> <name>hadoop.proxyuser.hadoop.hosts</name> <value>*</value> </property> <property> <name>hadoop.proxyuser.hadoop.groups</name> <value>*</value> </property> </configuration>- /home/hadoop/hadoop2.7/etc/hadoop/hdfs-site.xml
<configuration> <property> <name>dfs.namenode.http-address</name> <value>node:50070</value> <description> fetch NameNode images and edits.注意主機名稱 </description> </property> <property> <name>dfs.namenode.secondary.http-address</name> <value>node1:50090</value> <description> fetch SecondNameNode fsimage </description> </property> <property> <name>dfs.replication</name> <value>3</value> <description> replica count </description> </property> <property> <name>dfs.namenode.name.dir</name> <value>file:///home/hadoop/hadoop2.7/hdfs/name</value> <description> namenode </description> </property> <property> <name>dfs.datanode.data.dir</name> <value>file:///home/hadoop/hadoop2.7/hdfs/data</value> <description> DataNode </description> </property> <property> <name>dfs.namenode.checkpoint.dir</name> <value>file:///home/hadoop/hadoop2.7/hdfs/namesecondary</value> <description> check point </description> </property> <property> <name>dfs.webhdfs.enabled</name> <value>true</value> </property> <property> <name>dfs.stream-buffer-size</name> <value>131072</value> <description> buffer </description> </property> <property> <name>dfs.namenode.checkpoint.period</name> <value>3600</value> <description> duration </description> </property> </configuration>- /home/hadoop/hadoop2.7/etc/hadoop/mapred-site.xml
<configuration> <property> <name>mapreduce.framework.name</name> <value>yarn</value> </property> <property> <name>mapreduce.jobtracker.address</name> <value>hdfs://trucy:9001</value> </property> <property> <name>mapreduce.jobhistory.address</name> <value>node:10020</value> <description>MapReduce JobHistory Server host:port, default port is 10020.</description> </property> <property> <name>mapreduce.jobhistory.webapp.address</name> <value>node:19888</value> <description>MapReduce JobHistory Server Web UI host:port, default port is 19888.</description> </property> </configuration>- /home/hadoop/hadoop2.7/etc/hadoop/yarn-site.xml
<configuration> <property> <name>yarn.resourcemanager.hostname</name> <value>node</value> </property> <property> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value> </property> <property> <name>yarn.nodemanager.aux-services.mapreduce.shuffle.class</name> <value>org.apache.hadoop.mapred.ShuffleHandler</value> </property> <property> <name>yarn.resourcemanager.address</name> <value>node:8032</value> </property> <property> <name>yarn.resourcemanager.scheduler.address</name> <value>node:8030</value> </property> <property> <name>yarn.resourcemanager.resource-tracker.address</name> <value>node:8031</value> </property> <property> <name>yarn.resourcemanager.admin.address</name> <value>node:8033</value> </property> <property> <name>yarn.resourcemanager.webapp.address</name> <value>node:8088</value> </property> </configuration>
配置無密碼登入
在所有主機上建立目錄並賦予許可權
mkdir /home/hadoop/.ssh chomod 700 /home/hadoop/.ssh在node主機上生成RSA檔案
ssh-keygen -t rsa -P '' -f ~/.ssh/id_rsa生成並拷貝 authorized_keys檔案
cp /home/hadoop/.ssh/id_rsa.pub authorized_keys scp /home/hadoop/.ssh/authorized_keys node1:/home/hadoop/.ssh scp /home/hadoop/.ssh/authorized_keys node2:/home/hadoop/.ssh scp /home/hadoop/.ssh/authorized_keys node3:/home/hadoop/.ssh在所有主機上修改擁有者和許可權
chmod 600 .ssh/authorized_keys chown -R hadoop:hadoop .ssh修改ssh 配置檔案
註釋掉 # AuthorizedKeysFile .ssh/authorized_keys重新啟動ssh
service sshd restartNote: 第一次連線仍然需要輸入密碼。
啟動Hadoop
進入Node 主機,並切換到hadoop賬號
su hadoop格式化 namenode
/home/hadoop/hadoop2.7/bin/hdfs namenode -format啟動 hdfs
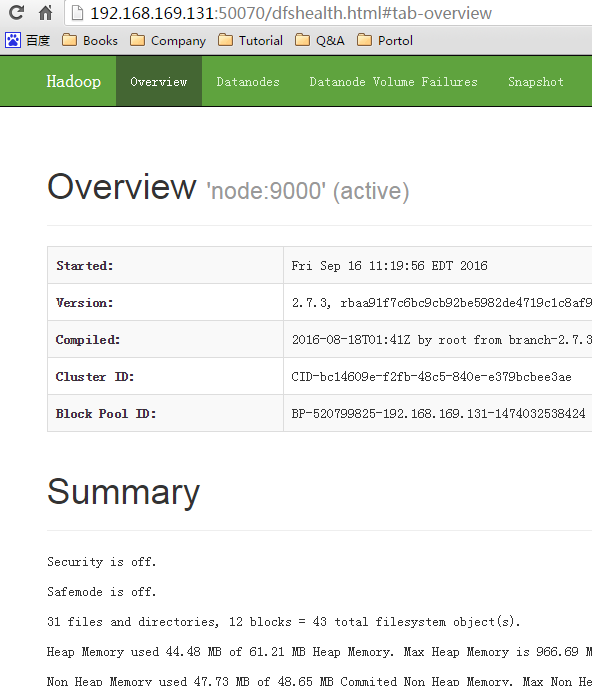
/home/hadoop/hadoop2.7/sbin/start-dfs.sh驗證 hdfs 狀態
啟動 yarn
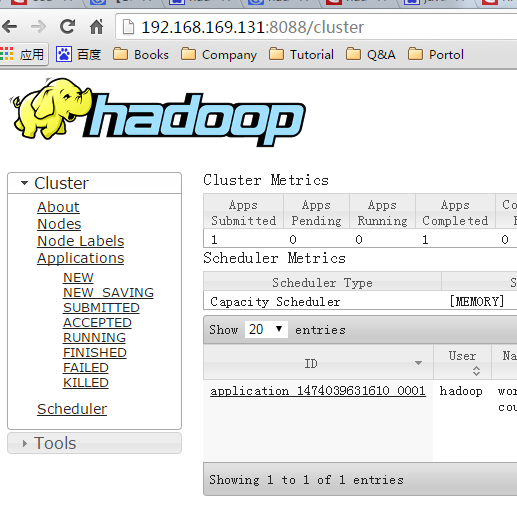
/home/hadoop/hadoop2.7/sbin/start-yarn.sh- 驗證 yarn 狀態
預設舉例
建立資料夾
/home/hadoop/hadoop2.7/bin/hadoop fs -mkdir -p /data/wordcount /home/hadoop/hadoop2.7/bin/hadoop fs -mkdir -p /output/上傳檔案
hadoop fs -put /home/hadoop/hadoop2.2/etc/hadoop/*.xml /data/wordcount/ hadoop fs -ls /data/wordcount執行Map-Reduce
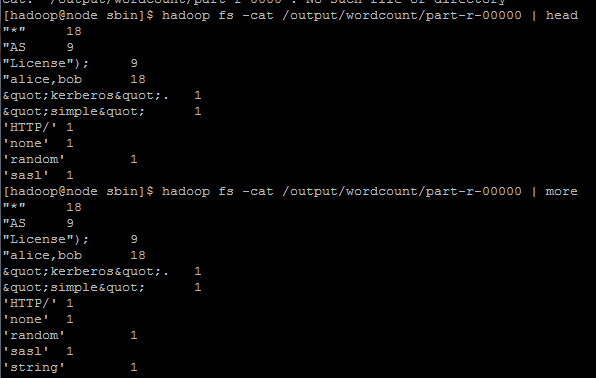
hadoop jar /home/hadoop/hadoop2.2/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.2.0.jar wordcount /data/wordcount /output/wordcount檢視狀態
http://192.168.169.131:8088/cluster瀏覽結果
hadoop fs -cat /output/wordcount/part-r-00000 | more