
開發Kafka通用資料平臺中介軟體
目錄:
一. Kafka概述
二. Kafka啟動命令
三.我們為什麼使用Kafka
四. Kafka資料平臺中介軟體設計及程式碼解析
五.未來Kafka開發任務
一. Kafka概述
Kafka是Linkedin於2010年12月份建立的開源訊息系統,它主要用於處理活躍的流式資料。活躍的流式資料在web網站應用中非常常見,這些活動資料包括頁面訪問量(Page View)、被檢視內容方面的資訊以及搜尋情況等內容。 這些資料通常以日誌的形式記錄下來,然後每隔一段時間進行一次統計分析。
傳統的日誌分析系統是一種離線處理日誌資訊的方式,但若要進行實時處理,通常會有較大延遲。而現有的訊息佇列系統能夠很好的處理實時或者近似實時的應用,但未處理的資料通常不會寫到磁碟上,這對於Hadoop
1.1 Kfka部署結構:
(圖1)
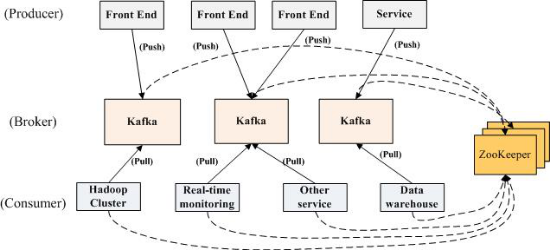
1.2 Kafka關鍵字:
•Broker : Kafka訊息伺服器,訊息中心。一個Broker可以容納多個Topic。
•Producer :訊息生產者,就是向Kafka broker發訊息的客戶端。
•Consumer :訊息消費者,向Kafka broker取訊息的客戶端。
•Zookeeper :管理Producer
•Topic :可以為各種訊息劃分為多個不同的主題,Topic就是主題名稱。Producer可以針對某個主題進行生產,Consumer可以針對某個主題進行訂閱。
•Consumer Group: Kafka採用廣播的方式進行訊息分發,而Consumer叢集在消費某Topic時, Zookeeper會為該叢集建立Offset消費偏移量,最新Consumer加入並消費該主題時,可以從最新的Offset點開始消費。
•Partition:Kafka採用對資料檔案切片(Partition)的方式可以將一個
(圖2)
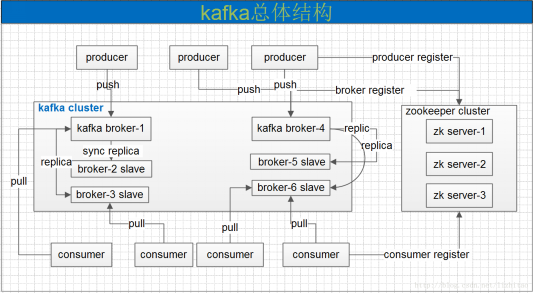
1.3 訊息收發流程:
•啟動Zookeeper及Broker.
•Producer連線Broker後,將訊息釋出到Broker中指定Topic上(可以指定Patition)。
•Broker叢集接收到Producer發過來的訊息後,將其持久化到硬碟,並將訊息該保留指定時長(可配置),而不關注訊息是否被消費。
•Consumer連線到Broker後,啟動訊息泵對Broker進行偵聽,當有訊息到來時,會觸發訊息泵迴圈獲取訊息,獲取訊息後Zookeeper將記錄該Consumer的訊息Offset。
1.4 Kafka特性:
•高吞吐量
•負載均衡:通過zookeeper對Producer,Broker,Consumer的動態加入與離開進行管理。
•拉取系統:由於kafka broker會持久化資料,broker沒有記憶體壓力,因此,consumer非常適合採取pull的方式消費資料
•動態擴充套件:當需要增加broker結點時,新增的broker會向zookeeper註冊,而producer及consumer會通過zookeeper感知這些變化,並及時作出調整。
•訊息刪除策略:資料檔案將會根據broker中的配置要求,保留一定的時間之後刪除。kafka通過這種簡單的手段,來釋放磁碟空間。
二. Kafka啟動命令:
啟動Zookeeper服務:
zookeeper-server-start.bat ../../config/zookeeper.properties
啟動Broker服務:
kafka-server-start.bat ../../config/server.properties
通過Zookeeper的協調在Broker中建立一個Topic(主題)
kafka-topics.bat --create --zookeeper localhost:2181 --replication-factor 1 --partitions 1 --topic testTopic
查詢當前Broker中某個指定主題的配置資訊
kafka-run-class.bat kafka.admin.TopicCommand --describe --zookeeper localhost:2181 --topic testTopic
啟動一個數據生產者Producer
kafka-console-producer.bat --broker-list localhost:9092 --topic testTopic
啟動一個數據消費者Consumer
kafka-console-consumer.bat --zookeeper localhost:2181 --topic testTopic --from-beginning
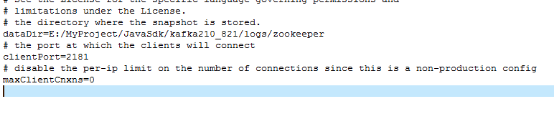
Zookeeper配置檔案,zookeeper.properties配置片段
Broker配置檔案,server.properties配置片段
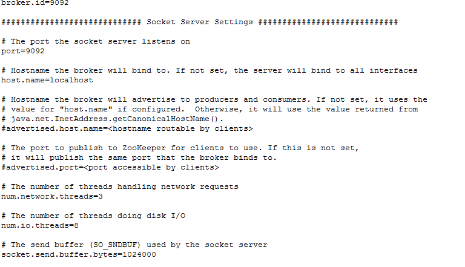
關於kafka收發訊息相關的配置項
1.在Broker Server中屬性(這些屬性需要在Server啟動時載入):
//每次Broker Server能夠接收的最大包大小,該引數要與consumer的fetch.message.max.bytes屬性進行匹配使用
* message.max.bytes 1000000(預設)
//Broker Server中針對Producer傳送方的資料緩衝區。Broker Server會利用該緩衝區迴圈接收來至Producer的資料 包,緩衝區過小會導致對該資料包的分段數量增加,但不會影響資料包尺寸限制問題。
socket.send.buffer.bytes 100 * 1024(預設)
//Broker Server中針對Consumer接收方的資料緩衝區。意思同上。
socket.receive.buffer.bytes 100 * 1024(預設)
//Broker Server中針對每次請求最大的緩衝區尺寸,包括Prodcuer和Consumer雙方。該值必須大於 message.max.bytes屬性
* socket.request.max.bytes 100 * 1024 * 1024(預設)
2.在Consumer中的屬性(這些屬性需要在程式中配置Consumer時設定)
//Consumer用於接收來自Broker的資料緩衝區,意思同socket.send.buffer.bytes。
socket.receive.buffer.bytes 64 * 1024(預設)
//Consumer用於每次接收訊息包的最大尺寸,該屬性需要與Broker中的message.max.bytes屬性配對使用
* fetch.message.max.bytes 1024 * 1024(預設)
3.在Producer中的屬性(這些屬性需要在程式中配置Consumer時設定)
//Producer用於傳送資料緩衝區,意思同socket.send.buffer.bytes。
send.buffer.bytes 100 * 1024(預設)
三. 我們為什麼使用Kafka
當前專案中,我們更希望從企業獲得儘可能多的有價值資料。最直接獲取大資料的方式是採用寫應用直連目標企業資料庫來獲得資料。但這種方式在實際應用中,會由於企業擔心開放本地資料庫而導致的安全隱患很難實施。另外,這種方式會與企業本地資料庫結構耦合度過高,會出現多家企業多個應用的情況,缺少統一的資料互動平臺,導致後期維護困難。
3.1 Kafka在當前專案中問題:
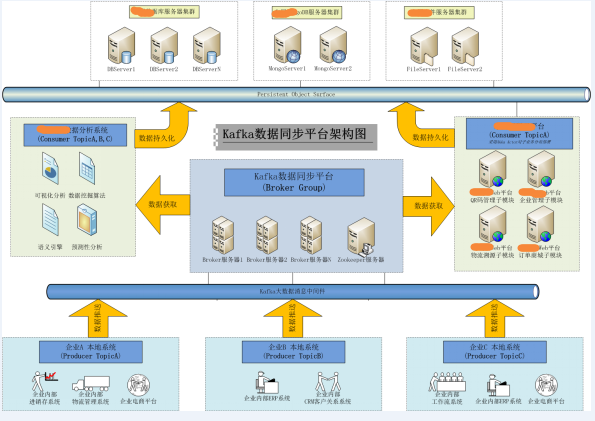
當前案例,我們想把某企業的本地資料實時同步到資料中心中,之後對這些資料進行二次分析處理。我們的目標是建立統一的資料同步平臺,便於在日後的多企業多系統中能有統一的實施標準,所以選用了Kafka訊息系統作為支撐。
Producer(資料傳送方)以獨立執行緒方式常駐某企業內部應用中,依靠一定的時間週期,從本地資料庫獲得資料並推送至Broker中。而Consumer(快銷組資料接收方)也是獨立與WEB框架常駐記憶體,獲得資料訊息後儲存至資料中心中。
但目前Kafka在實施中面臨以下問題:
1.Producer/Consumer均獨立於Web框架,Producer依靠訊息片輪詢檢索/傳送最新資料,執行效率低。
2.Producer會直接針對某企業內部資料庫表結構操作,導致程式碼與企業業務耦合度過高,而無法平滑移植到其他企業系統中。
3.由於Producer/Consumer是獨立於Web框架的,在外圍負責資料的採集及推送,與Web專案主程式無切合度。
4.目前針對Kafka的資料傳輸異常處理比較簡陋,當Broker或 Zookeeper等出現異常時,有可能會導致資料安全性問題。
3.2實現目標:
針對以上問題,我們要實現如下目標:
1.把Producer/Consumer的資料推送/獲取的過程封裝成Class或者Jar包的形式,供Java Web框架呼叫,從而形成與企業內部Web應用或計算中心資料分析Web應用融合一體。
2.資料的推送/獲取只針對Java Object物件,不要針對資料庫表結構,不能與企業特有資料耦合度過高,形成通用的資料介面。Producer需要對Object進行序列化,Consumer需要對序列化後的二進位制資訊進行反序列化重建Object返回給呼叫者。
3.訊息的推送/獲取的整個生命週期中,要把重要事件通知給外部呼叫者,比如:Broker,Zookeeper是否有異常,資料推送/獲取是否成功,如果失敗需要保留失敗記錄便於進行後期資料恢復等。(需要在中介軟體中建立回撥機制通知呼叫者)
4.可對多企業多應用進行平滑移植,移植過程中儘可能保持整體Kafka資料平臺結構的零修改。
四. Kafka資料平臺中介軟體設計
4.1解決方案:
基於以上待完成目標,我們有了以下解決方案。
3.2 實現要點:
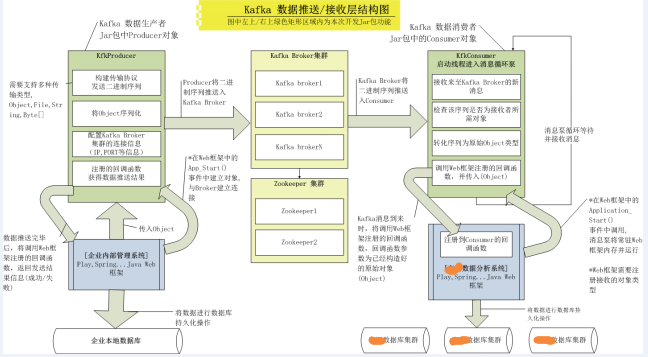
KfkProducer(資料生產者)
•KfkProducer物件需要在Web框架中的Application_OnStart()中啟動,常駐程序,只與Broker連線一次,資料傳送過程不能與Broker建立連線。(實踐中發現Kafka的 Broker如果有異常,重啟Broker後Producer不用再次連線即可傳送)
•Web框架可以隨時呼叫推送介面將物件(Object)推送至Broker.
•Object序列化後形成二進位制資訊,並且要保證在Consumer所處框架中能順利還原.
•可傳送多種物件(Object,File ,Byte[]等),簡化外圍框架針對待發送資料所做操作,簡化呼叫介面。
•資料傳送使用Kafka中最新的非同步式資料傳送API,不能由於傳送時間過長或Broker異常等問題阻塞呼叫者。
•需要對整個傳送生命期進行跟蹤反饋異常資訊,若傳送失敗,需要將待發送資料使用回撥機制通知到框架呼叫者。
•詳細測試Broker,或Zookeeper產生異常時,Producer可能會出現的情況。
•在針對多企業多應用中,可依靠Topic進行區分資料主題,這樣可實現多應用部署時框架零修改問題。
KfkConsumer(資料消費者)
•KfkConsumer需要在計算中心內部Web框架中的Application_OnStart()中啟動,常駐程序,只與Broker連線一次,並啟動訊息泵等待訊息到來。(實踐中發現Kafka的 Broker如果有異常,重啟Broker後Consumer不用再次連線即可正常獲取訊息)
•需要定義回撥介面,該回調介面由外圍框架程式註冊處理程式,當資料訊息到來時,Consumer需要把資料傳送至該介面,之後由呼叫者處理。
•呼叫者需要註冊所接受的物件型別,因為Broker中同一Topic下會有各種資料物件(UserInfo,CompanyInfo,ProductInfo...)存在,所以必須提供接收物件的註冊介面,以方便呼叫者有針對性的獲取。
•資料到來時,要針對傳送方序列化的二進位制資訊進行反序列化操作,並能準確還原成原始物件。
•需要對整個接收生命期進行跟蹤反饋異常資訊,若訊息泵停止或異常,需要通知到框架呼叫者。
實現以上要點後,需要將KfkProducer及KfkConsumer物件打包成Jar包的形式,更靈活的部署到企業本地Web框架及計算中心內部Web框架中。
3.3 程式碼實現及分析:
3.3.1 KfkProducer 物件:資料生產者物件,封裝了關於資料傳送的相關功能。
介面函式/子物件 |
說明 |
KfkProducer () |
建構函式中需要呼叫者提供Broker叢集的Ip,Port等資訊。 Kafka支援Broker叢集列表。(127.0.0.1:9092,127.0.0.1:9093)
|
Connect() |
該函式需要完成對Broker叢集的連線。
|
Send() |
該函式入口為Object物件,需要對該物件進行Serialize操作,根據待發送資料構造KfkMsg物件,並取得由KfkMsg序列化後的Byte[]陣列,之後呼叫Kafka的非同步傳送方式及掛接回調處理函式。
要實現多個Send()介面,需要提供對Object,File ,Byte[]等多種資料型別的支援,方便呼叫者操作。
|
Close() |
該函式完成對Broker連線進行關閉。
|
SendCallback傳送回撥物件 onCompletion()傳送回撥介面 |
在kafka非同步傳送函式send()中註冊,在收到Broker返回的傳送是否成功資訊後,會觸發該函式,並呼叫ProducerEvent物件的onSendMsg()函式,向呼叫者傳送成功與否結果。
成功則返回呼叫者RecordMetadata資訊(BrokerServer中的資料offset,Partition位置ID,Topic主題)
失敗者返回呼叫者原始資料資訊,便於日後恢復。
|
ProducerEvent介面物件 onSendMsg() |
為呼叫者提供的回撥介面,呼叫者在註冊後,即可重寫onSendMsg()函式,以便接到通知後,處理當前事件(傳送資料成功與否)狀態。
|
3.3.2 KfkConsumer物件:資料消費者物件,封裝了關於資料接收的相關功能。
介面函式/子物件 |
說明 |
KfkConsumer() |
建構函式中需要呼叫者提供Zookeeper叢集的Ip,Port等資訊。(即將推出的Kafka0.9.X版本將支援直連Broker叢集的機制)
該物件繼承至Thread物件,為執行緒物件。 |
connect() |
配置Zookeeper連線相關屬性,並連線Zookeeper伺服器。
|
run() |
執行緒主函式,該函式將啟動Kafka訊息泵等待Broker的訊息到來。
訊息到來後,將呼叫KfkMsg物件對二進位制序列化資訊進行還原物件操作(KfkMsg將對序列化資料進行反序列化操作,並重新還原原始物件操作)。
物件還原後,將呼叫呼叫者註冊的回撥介面,將物件傳出。
|
close() |
關閉Consumer與Broker,Zookeeper的Socket連線。
|
ConsumerEvent接收回調物件 onRecvMsg()接收回調函式 |
為呼叫者提供的回撥介面,呼叫者在註冊後,即可重寫onRecvMsg()函式,以便接到通知後,收取物件或處理當前事件。
|
3.3.3 KfkMsg物件:資料訊息物件,封裝了資料物件的序列化/反序列化操作,構造多種型別的傳送物件,封裝傳送協議等操作。
介面函式/子物件 |
說明 |
MsgBase物件 |
訊息包基類,可以在Consumer接到資料訊息後,形成多種物件的反序列化多型性。
|
MsgObject物件 serializeMsg()序列化函式 deserializeMsg()反序列化函式 |
針對Object資料的序列化和反序列化操作,及訊息體封裝,通訊協議構造等操作。
|
MsgByteArr物件 serializeMsg()序列化函式 deserializeMsg()反序列化函式 |
針對Byte[]資料的序列化和反序列化操作,及訊息體封裝,通訊協議構造等操作。
|
MsgFile物件 serializeMsg()序列化函式 deserializeMsg()反序列化函式 |
針對二進位制檔案的序列化和反序列化操作,及訊息體封裝,通訊協議構造等操作。
|
getMsgType()函式
|
負責對Consumer接收的序列化資訊進行首次協議解析,判斷物件型別(Object,File,byte[])之後構造對應的MsgXXX物件,以便使呼叫者進行反序列化多型功能。
|
3.3.4 SerializeUtils物件:序列化操作工具類,完成在Jar包內部對外部物件的序列化/反序列化基礎從操作。
介面函式/子物件 |
說明 |
deserialize()函式 |
將序列化後的二進位制陣列byte[]還原成原始Object.
由於如果使用預設的ObjectInputStream物件進行反序列化操作,在Jar內將無法找到外部呼叫者定義的物件名,也即無法反序列化成功,報無法找到外部物件的異常。
所以必須重寫resolveClass()函式,載入當前執行緒範圍內的Class上下文。
|
Serialize()函式 |
將Object序列化成二進位制陣列,byte[]。
|
3.3.5 呼叫者Web框架部署:
KfkProducer部署:
部署要點 |
說明 |
1.註冊傳送訊息回撥函式 |
在WEB框架中的Application_OnStart()事件中向Jar註冊傳送訊息回撥函式。並重寫onSendMsg()回撥介面,用於接受傳送成功/失敗訊息,傳送失敗後,可以在Web框架中針對返回的原始資料資訊做備份/恢復處理。
|
2.建立與Broker之間的連線 |
在WEB框架中的 Application_OnStart()事件中呼叫KfkProducer connect()函式,連線遠端Broker。
|
3.將KfkProducer傳入框架 |
經過前兩步操作後,我們已經順利建立KfkProducer物件,現在我們需要把該物件傳入Web框架中後續頁面處理類中,以方便呼叫其send()函式進行資料傳送。
在Play中我們使用了cache物件機制,可以在Play Web App全生命期內獲得KfkProducer物件例項。
|
4.關閉與Broker之間的連線 |
在WEB框架中的Application_OnStop()事件中呼叫KfkProducer的close()函式,關閉遠端Broker連線。
|
KfkConsumer部署:
部署要點 |
說明 |
1.註冊傳送訊息回撥函式 |
在WEB框架中的Application_OnStart()事件中向Jar註冊訊息接收回調函式。並重寫onRecvMsg()回撥介面,用於接受來自Broker的資料資訊。
在onRecvMsg()函式中,還需針對傳入的Object物件進行instanceof比對操作,區分特定物件。
|
2.註冊需要接收的Object型別 |
向Jar包中註冊需要接收的物件型別,比如本應用需要接收(UserInfo,CompanyInfo,ProdcutInfo等物件)。 註冊後,來自Broker的廣播訊息將被Jar包過濾,只返回呼叫者所需的物件資料。
|
3.建立與Zookeeper(Broker)之間的連線 |
在WEB框架中的 Application_OnStart()事件中呼叫KfkConsumer connect()函式,連線遠端Zookeeper/Broker。
|
4.啟動訊息泵執行緒 |
相關推薦開發Kafka通用資料平臺中介軟體目錄: 一. Kafka概述 二. Kafka啟動命令 三.我們為什麼使用Kafka 四. Kafka資料平臺中介軟體設計及程式碼解析 五.未來Kafka開發任務 一. Kafka概述 Kafka是Linkedin於2010年 三層架構-伺服器端:通用WebService資料互動中介軟體概述2、在WebService服務介面中, 新增對外互動的介面函式。以我們的中介軟體為例,一般處理的都是資料庫中的業務資料,那我們就需要處理好資料庫連線、提供基本的增刪改查介面。既然使用的是Webservice介面,那麼介面引數型別可以為WideString或者OleVariant等Delphi簡單型別,使其他語 MySQL開源資料傳輸中介軟體架構設計實踐本文根據洪斌10月27日在「3306π」技術 Meetup - 武漢站現場演講內容整理而成。 主要內容: 本次分享將介紹目前資料遷移、資料同步、資料消費,多IDC架構中資料複製技術所面臨問題及現有的產品和方案,並分享新開源的能在異構資料儲存之間提供高效能和強大複製功能的DTLE相關技術 增量資料同步中介軟體增量資料同步中介軟體DataLink分享(已開源) https://www.cnblogs.com/ucarinc/p/9770990.html 專案介紹 名稱: DataLink['deitə liŋk] 譯意: 資料鏈路,資料(自動)傳輸器 語言: 純java開發(JDK1.8+) 定位: 滿足各種異 Porter 3.0 釋出,隨行付資料同步中介軟體資料同步中介軟體 Porter 3.0釋出。 Porter是一個外掛友好型的資料聚合、分發中介軟體,提供源端、目標端、資料過濾等外掛自定義開發的能力,能夠根據場景需要輕鬆定製同步任務。 目前Porter 3.0版本已釋出,這是一個里程碑式的更新版本,新增單機模式,同時對管 資料計算中介軟體技術綜述傳統企業大資料架構的問題 上圖是大家都很熟悉的基於 Hadoop 體系的開源大資料架構圖。在這個架構中,大致可以分成三層。最下一層是資料採集,通常會採用 kafka 或者 Flume 將 web 日誌通過訊息佇列傳送到儲存層或者計算層。對於資料儲存,目前 Apache 社群提 增量資料同步中介軟體DataLink分享(已開源)專案介紹 名稱: DataLink['deitə liŋk]譯意: 資料鏈路,資料(自動)傳輸器語言: 純java開發(JDK1.8+)定位: 滿足各種異構資料來源之間的實時增量同步,一個分散式、可擴充套件的資料同步系統開源地址:https://github.com/ucarGroup/DataLink 此次 獲取postman的form-data資料的中介軟體記錄一下獲取postman的form-data資料的中介軟體 var express = require(‘express’); var bodyParser = require(‘body-parser’); var multer = require(‘multer’); var app 愛可生開源資料傳輸中介軟體DTLE亮相「3306π」深圳站年會12月15日,上海愛可生資訊科技股份有限公司贊助的「3306π」年會-深圳站成功舉辦,此次年會圍繞MySQL核心技術,邀請各大行業一線大咖分享最新鮮的前沿技術與最生動的實踐案例。愛可生技術服務總監洪斌現場分享了開源資料傳輸中介軟體DTLE的相關技術。 技 愛可生MySQL開源資料傳輸中介軟體DTLE首次技術分享10月27日,上海愛可生資訊科技股份有限公司贊助的「3306π」技術 Meetup - 武漢站成功舉辦,愛可生技術服務總監洪斌分享了《MySQL 開源資料傳輸中介軟體架構設計實踐》的主題演講,並對愛可生10月24日最新開源專案 DTLE 相關技術細節進行了詳細講解。 D 愛可⽣開源MySQL資料傳輸中介軟體—DTLE2018年10⽉24⽇,企業級資料處理技術整體解決方案提供商上海愛可⽣資訊科技股份有限公司正式開源其 MySQL 資料傳輸中介軟體DTLE。 DTLE: http://dtle.cloud https://gith 大資料開發:實時資料平臺和流計算大資料開發 1、實時資料平臺整體架構 實時資料平臺的支撐技術主要包含四個方面:實時資料採集(如Flume),訊息中介軟體(如Kafka), 流計算框架(如Storm, Spark, Flink和Beam),以及資料實時儲存(如列 分散式資料層中介軟體詳解:如何實現分庫分表+動態資料來源+讀寫分離優知學院 2018-10-13 12:10:20 分散式資料層中介軟體: 1.簡介: 分散式資料訪問層中介軟體,旨在為供一個通用資料訪問層服務,支援MySQL動態資料來源、讀寫分離、分散式唯一主鍵生成器、分庫分表、動態化配置等功能,並且支援從客戶端角度對 阿里Canal框架(資料同步中介軟體)初步實踐最近在工作中需要處理一些大資料量同步的場景,正好運用到了canal這款資料庫中介軟體,因此特意花了點時間來進行該中介軟體的的學習和總結。 背景介紹 早期,阿里巴巴B2B公司因為存在杭州和美國雙機房部署,存在跨機房同步的業務需求。不過早期的資料庫同步業務,主要是基於trigger的方式獲取增量變更,不過從2 流程快速開發平臺,工作流引擎中介軟體,工作質量考核設計工作質量考核設計 關鍵字:CCBPM工作質量考核時效考核 需求背景: 我們把在工作流程引擎中的考核分為兩種模式,一種是時效考核、另外一種是質量考核。 時效考核就是對使用者的操作進行時間點的記錄,然後按照一定的規則進行計算出來該人員提前、超時、逾期完成工作的情況進行量化的評 Senparc.Weixin.MP SDK 微信公眾平臺開發教程(二十二):在 .NET Core 2.0/3.0 中使用 MessageHandler 中介軟體概述 在 《Senparc.Weixin.MP SDK 微信公眾平臺開發教程(六):瞭解MessageHandler》 中我們已經瞭解了 MessageHandler 的執行原理和使用方法,從我設計了這種處理方式到現在已經 6 年多的時間,這是一種非常穩定而且(在如此複雜環境下)相對易於維護的 aNDROID平臺應用軟體開發平臺 lis oid andro music 5% baidu .com aid aNDROID%E4%BA%8B%E4%BB%B6%E7%9B%91%E5%90%AC%E5%9B%9E%E8%B0%83%E6%9C%BA%E5%88%B6 http://music.hao Kafka-API中介軟體MQ訊息佇列在Maven專案中的配置使用操作 (分散式釋出訂閱訊息系統)一、 Maven依賴 <dependency> <groupId>com.foriseland.fjf.mq</groupId> <artifactId>fjf-mq-kafka</artifactId> & 中介軟體系列ActiveMQ,Rocketmq,Rabbitmq,Kafka,Mycat讓你深入理解學習中介軟體以前的網路主要是客戶端與伺服器(C/S)結構或瀏覽器/伺服器(B/S) 形式的兩層結構,隨著企業資訊的不斷擴大,企業級應用不再滿足於簡單的兩層系統,而是向著三層和多層體系結構發展。中介軟體就是在其中加入一箇中間層,以支援更多的功能和服務。 一、什麼是中介軟體 &n 中介軟體系列ActiveMQ,Rocketmq,Rabbitmq,Kafka,Mycat讓你深入理解學習中介軟體視訊教程網盤中介軟體系列ActiveMQ,Rocketmq,Rabbitmq,Kafka,Mycat讓你深入理解學習中介軟體視訊教程網盤39套Java架構師,高併發,高效能,高可用,分散式,叢集,電商,快取,微服務,微信支付寶支付,公眾號開發,java8新特性,P2P金融專案,程式設計,功能設計,資料庫設計,第 |