
關於詞向量的一篇好的入門文章
很好,正好可藉此機會介紹詞向量、word2vec以及DeepNLP整套相關的東西:
文章很長,是從CSDN上寫好複製過來的,亦可直接跳到部落格觀看:
here we go.
·············································border··············································
From RxNLP.Scofield轉載註明出處。·············································Header··············································
《DeepNLP的表示學習·詞嵌入來龍去脈·深度學習(Deep Learning)·自然語言處理(NLP)·表示(Representation)》
·············································border··············································
Indexing:
〇、序
一、DeepNLP的核心關鍵:語言表示(Representation)
二、NLP詞的表示方法型別
1、詞的獨熱表示one-hot representation
2、詞的分散式表示distributed representation
三、NLP語言模型
四、詞的分散式表示
1. 基於矩陣的分佈表示
2. 基於聚類的分佈表示
3. 基於神經網路的分佈表示,詞嵌入( word embedding)
五、詞嵌入( word embedding)
1、概念
2、理解
六、神經網路語言模型與word2vec
1、神經網路語言模型
2.word2vec與CBOW、Skip-gram
3.個人對word embedding的理解
七、後言
References
·············································border··············································
〇、序 之前一段時間,在結合深度學習做NLP的時候一直有思考一些問題,其中有一個問題算是最核心一個:究竟深度網路是怎麼做到讓各種NLP任務解決地如何完美呢?到底我的資料在NN中發什麼了什麼呢?
並且,不少的terms like: 詞向量、word embedding、分散式表示、word2vec、glove等等,這一鍋粥的名詞術語分別代表什麼,他們具體的關係是什麼,他們是否處於平級關係?
出於對知識結構追求完整梳理的強迫症的老毛病,於是不停地查資料、思考、keep revolving……
然後就感覺有一點小進展了。想到,不如將個人對其的理解,無論對錯,先拿出來跟peer分享下,或許能交換出更有意義的東西呢?
整篇文章的構架是按照屬於概念在邏輯上的先後大小順序,一層一層一級一級地往下剖析、比較、說明。
另外說明下,here整篇文字內容相對是比較入門,甚至有的點可能描述的不太客觀正確,限於當前的認知水平……還請您海涵,希望您在評論中指正!
一、DeepNLP的核心關鍵:語言表示(Representation) 最近有一個新名詞:Deep Learning + NLP = DeepNLP。當常規的機器學習Machine Learning升級發展到了一定的階段後,慢慢的被後起的深度學習Deep Learning奪勢而去,並如火如荼地引領了一波新高潮,因為Deep Learning有machinelearning過而不及之處!那當Deep Learning進入NLP領域,自然是要橫掃ACL一批paper才是。事實也是這樣的。
先提下資料特徵表示問題。資料表示是機器學習的核心問題,在過去的Machine Learning階段,大量興起特徵工程,人工設計大量的特徵解決資料的有效表示問題。而到了Deep Learning,想都別想,end-2-end,一步到位,hyper-parameter自動幫你選擇尋找關鍵的特徵引數。
那麼,Deep Learning如何能在NLP中發揮出應有的real power呢?很明顯,先不提如何設計出很強勢的網路結構,不提如何在NLP中引入基於NN的解決例如情感分析、實體識別、機器翻譯、文字生成這些高階任務,咱們首先得把語言表示這一關過了——如何讓語言表示成為NN能夠處理的資料型別。
我們看看影象和語音是怎麼表示資料的:
<img src="https://pic2.zhimg.com/v2-79c5bc427f8d337a45534d226e83ee4d_b.jpg" data-rawwidth="857" data-rawheight="324" class="origin_image zh-lightbox-thumb" width="857" data-original="https://pic2.zhimg.com/v2-79c5bc427f8d337a45534d226e83ee4d_r.jpg">

在語音中,用音訊頻譜序列向量所構成的matrix作為前端輸入餵給NN進行處理,good;在影象中,用圖片的畫素構成的matrix展平成vector後組成的vector序列餵給NN進行處理,good;那在自然語言處理中呢?噢你可能知道或者不知道,將每一個詞用一個向量表示出來!想法是挺簡單的,對,事實上就是這麼簡單,然而真有這麼簡單嗎?可能沒這麼簡單。
有人提到,影象、語音屬於比較自然地低階資料表示形式,在影象和語音領域,最基本的資料是訊號資料,我們可以通過一些距離度量,判斷訊號是否相似,在判斷兩幅圖片是否相似時,只需通過觀察圖片本身就能給出回答。而語言作為人類在進化了幾百萬年所產生的一種高層的抽象的思維資訊表達的工具,其具有高度抽象的特徵,文字是符號資料,兩個詞只要字面不同,就難以刻畫它們之間的聯絡,即使是“麥克風”和“話筒”這樣的同義詞,從字面上也難以看出這兩者意思相同(語義鴻溝現象),可能並不是簡單地一加一那麼簡單就能表示出來,而判斷兩個詞是否相似時,還需要更多的背景知識才能做出回答。
那麼據上是不是可以自信地下一個結論呢:如何有效地表示出語言句子是決定NN能發揮出強大擬合計算能力的關鍵前提!
二、NLP詞的表示方法型別 接下來將按照上面的思路,引出各種詞的表示方法。按照現今目前的發展,詞的表示分為獨熱表示one-hot、分散式表示distributed。
1、詞的獨熱表示one-hot representation NLP 中最直觀,也是到目前為止最常用的詞表示方法是 One-hot Representation,這種方法把每個詞表示為一個很長的向量。這個向量的維度是詞表大小,其中絕大多數元素為 0,只有一個維度的值為 1,這個維度就代表了當前的詞。關於one-hot編碼的資料很多,街貨,這裡簡單舉個栗子說明:
“話筒”表示為 [0 0 0 1 0 0 0 0 0 0 0 0 0 0 0 0 ...] “麥克”表示為 [0 0 0 0 0 0 0 0 1 0 0 0 0 0 0 0 ...]
每個詞都是茫茫 0 海中的一個 1。這種 One-hot Representation 如果採用稀疏方式儲存,會是非常的簡潔:也就是給每個詞分配一個數字 ID。比如剛才的例子中,話筒記為 3,麥克記為 8(假設從 0 開始記)。如果要程式設計實現的話,用 Hash 表給每個詞分配一個編號就可以了。這麼簡潔的表示方法配合上最大熵、SVM、CRF 等等演算法已經很好地完成了 NLP 領域的各種主流任務。
現在我們分析他的不當處。1、向量的維度會隨著句子的詞的數量型別增大而增大;2、任意兩個詞之間都是孤立的,根本無法表示出在語義層面上詞語詞之間的相關資訊,而這一點是致命的。
2、詞的分散式表示distributed representation 傳統的獨熱表示( one-hot representation)僅僅將詞符號化,不包含任何語義資訊。如何將語義融入到詞表示中?Harris 在 1954 年提出的分佈假說( distributional hypothesis)為這一設想提供了理論基礎:上下文相似的詞,其語義也相似。Firth 在 1957 年對分佈假說進行了進一步闡述和明確:詞的語義由其上下文決定( a word is characterized by thecompany it keeps)。
到目前為止,基於分佈假說的詞表示方法,根據建模的不同,主要可以分為三類:基於矩陣的分佈表示、基於聚類的分佈表示和基於神經網路的分佈表示。儘管這些不同的分佈表示方法使用了不同的技術手段獲取詞表示,但由於這些方法均基於分佈假說,它們的核心思想也都由兩部分組成:一、選擇一種方式描述上下文;二、選擇一種模型刻畫某個詞(下文稱“目標詞”)與其上下文之間的關係。
三、NLP語言模型 在詳細介紹詞的分散式表示之前,需要將NLP中的一個關鍵概念描述清楚:語言模型。語言模型包括文法語言模型和統計語言模型。一般我們指的是統計語言模型。之所以要將語言模型擺在詞表示方法之前,是因為後面的表示方法馬上要用到這一概念。
統計語言模型: 統計語言模型把語言(詞的序列)看作一個隨機事件,並賦予相應的概率來描述其屬於某種語言集合的可能性。給定一個詞彙集合 V,對於一個由 V 中的詞構成的序列S = ⟨w1, · · · , wT ⟩ ∈ Vn,統計語言模型賦予這個序列一個概率P(S),來衡量S 符合自然語言的語法和語義規則的置信度。
用一句簡單的話說,就語言模型就是計算一個句子的概率大小的這種模型。有什麼意義呢?一個句子的打分概率越高,越說明他是更合乎人說出來的自然句子。
就是這麼簡單。常見的統計語言模型有N元文法模型(N-gram Model),最常見的是unigram model、bigram model、trigram model等等。形式化講,統計語言模型的作用是為一個長度為 m 的字串確定一個概率分佈 P(w1; w2; :::; wm),表示其存在的可能性,其中 w1 到 wm 依次表示這段文字中的各個詞。一般在實際求解過程中,通常採用下式計算其概率值:
<img src="https://pic4.zhimg.com/v2-d27151ddaec2cd19f907bc41820cddc7_b.png" data-rawwidth="478" data-rawheight="75" class="origin_image zh-lightbox-thumb" width="478" data-original="https://pic4.zhimg.com/v2-d27151ddaec2cd19f907bc41820cddc7_r.png">
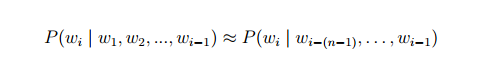
同時通過這些方法均也可以保留住一定的詞序資訊,這樣就能把一個詞的上下文資訊capture住。
具體的語言模型詳情屬於街貨,詳細請自行搜尋。
四、詞的分散式表示
1. 基於矩陣的分佈表示 基於矩陣的分佈表示通常又稱為分佈語義模型,在這種表示下,矩陣中的一行,就成為了對應詞的表示,這種表示描述了該詞的上下文的分佈。由於分佈假說認為上下文相似的詞,其語義也相似,因此在這種表示下,兩個詞的語義相似度可以直接轉化為兩個向量的空間距離。
常見到的Global Vector 模型( GloVe模型)是一種對“詞-詞”矩陣進行分解從而得到詞表示的方法,屬於基於矩陣的分佈表示。
2. 基於聚類的分佈表示 基於聚類的分佈表示我也還不是太清楚,所以就不做具體描述。
3. 基於神經網路的分佈表示,詞嵌入( word embedding)
基於神經網路的分佈表示一般稱為詞向量、詞嵌入( word embedding)或分散式表示( distributed representation)。這正是我們的主角today。
神經網路詞向量表示技術通過神經網路技術對上下文,以及上下文與目標詞之間的關係進行建模。由於神經網路較為靈活,這類方法的最大優勢在於可以表示複雜的上下文。在前面基於矩陣的分佈表示方法中,最常用的上下文是詞。如果使用包含詞序資訊的 n-gram 作為上下文,當 n 增加時, n-gram 的總數會呈指數級增長,此時會遇到維數災難問題。而神經網路在表示 n-gram 時,可以通過一些組合方式對 n 個詞進行組合,引數個數僅以線性速度增長。有了這一優勢,神經網路模型可以對更復雜的上下文進行建模,在詞向量中包含更豐富的語義資訊。
五、詞嵌入( word embedding)
1、概念 基於神經網路的分佈表示又稱為詞向量、詞嵌入,神經網路詞向量模型與其它分佈表示方法一樣,均基於分佈假說,核心依然是上下文的表示以及上下文與目標詞之間的關係的建模。
前面提到過,為了選擇一種模型刻畫某個詞(下文稱“目標詞”)與其上下文之間的關係,我們需要在詞向量中capture到一個詞的上下文資訊。同時,上面我們恰巧提到了統計語言模型正好具有捕捉上下文資訊的能力。那麼構建上下文與目標詞之間的關係,最自然的一種思路就是使用語言模型。從歷史上看,早期的詞向量只是神經網路語言模型的副產品。
2001年, Bengio 等人正式提出神經網路語言模型( Neural Network Language Model ,NNLM),該模型在學習語言模型的同時,也得到了詞向量。所以請注意一點:詞向量可以認為是神經網路訓練語言模型的副產品。
2、理解 前面提過,one-hot表示法具有維度過大的缺點,那麼現在將vector做一些改進:1、將vector每一個元素由整形改為浮點型,變為整個實數範圍的表示;2、將原來稀疏的巨大維度壓縮嵌入到一個更小維度的空間。如圖示:
<img src="https://pic2.zhimg.com/v2-d652e78ec0a60ce27e3ad3057c1ad4c5_b.png" data-rawwidth="468" data-rawheight="392" class="origin_image zh-lightbox-thumb" width="468" data-original="https://pic2.zhimg.com/v2-d652e78ec0a60ce27e3ad3057c1ad4c5_r.png">
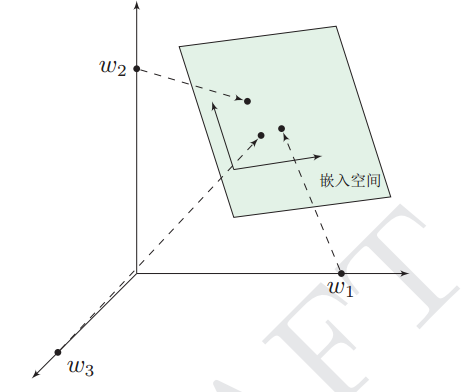
這也是詞向量又名詞嵌入的緣由了。
六、神經網路語言模型與word2vec 好了,到目前為止我們已經對的分散式表示以及詞嵌入的概念的層級關係有了個理性的認識了,那這跟word2vec有什麼聯絡?
1、神經網路語言模型 上面說,通過神經網路訓練語言模型可以得到詞向量,那麼,究竟有哪些型別的神經網路語言模型呢?個人所知,大致有這麼些個:
a) Neural Network Language Model ,NNLMb) Log-Bilinear Language Model, LBLc) Recurrent Neural Network based Language Model,RNNLMd) Collobert 和 Weston 在2008 年提出的 C&W 模型e) Mikolov 等人提出了 CBOW( Continuous Bagof-Words)和 Skip-gram 模型
到這,估計有人看到了兩個熟悉的term:CBOW、skip-gram,有看過word2vec的同學應該對此有所瞭解。我們繼續。
2.word2vec與CBOW、Skip-gram 現在我們正式引出最火熱的另一個term:word2vec。
上面提到的5個神經網路語言模型,只是個在邏輯概念上的東西,那麼具體我們得通過設計將其實現出來,而實現CBOW( Continuous Bagof-Words)和 Skip-gram 語言模型的工具正是well-known word2vec!另外,C&W 模型的實現工具是SENNA。
所以說,分散式詞向量並不是word2vec的作者發明的,他只是提出了一種更快更好的方式來訓練語言模型罷了。分別是:連續詞袋模型Continous Bag of Words Model(CBOW)和Skip-Gram Model,這兩種都是可以訓練出詞向量的方法,再具體程式碼操作中可以只選擇其一,不過據論文說CBOW要更快一些。
順便說說這兩個語言模型。統計語言模型statistical language model就是給你幾個詞,在這幾個詞出現的前提下來計算某個詞出現的(事後)概率。CBOW也是統計語言模型的一種,顧名思義就是根據某個詞前面的C個詞或者前後C個連續的詞,來計算某個詞出現的概率。Skip-Gram Model相反,是根據某個詞,然後分別計算它前後出現某幾個詞的各個概率。
以“我愛北京天安門”這句話為例。假設我們現在關注的詞是“愛”,C=2時它的上下文分別是“我”,“北京天安門”。CBOW模型就是把“我” “北京天安門” 的one hot表示方式作為輸入,也就是C個1xV的向量,分別跟同一個VxN的大小的係數矩陣W1相乘得到C個1xN的隱藏層hidden layer,然後C個取平均所以只算一個隱藏層。這個過程也被稱為線性啟用函式(這也算啟用函式?分明就是沒有啟用函數了)。然後再跟另一個NxV大小的係數矩陣W2相乘得到1xV的輸出層,這個輸出層每個元素代表的就是詞庫裡每個詞的事後概率。輸出層需要跟ground truth也就是“愛”的one hot形式做比較計算loss。這裡需要注意的就是V通常是一個很大的數比如幾百萬,計算起來相當費時間,除了“愛”那個位置的元素肯定要算在loss裡面,word2vec就用基於huffman編碼的Hierarchical softmax篩選掉了一部分不可能的詞,然後又用nagetive samping再去掉了一些負樣本的詞所以時間複雜度就從O(V)變成了O(logV)。Skip gram訓練過程類似,只不過輸入輸出剛好相反。
補充下,Word embedding的訓練方法大致可以分為兩類:一類是無監督或弱監督的預訓練;一類是端對端(end to end)的有監督訓練。無監督或弱監督的預訓練以word2vec和auto-encoder為代表。這一類模型的特點是,不需要大量的人工標記樣本就可以得到質量還不錯的embedding向量。不過因為缺少了任務導向,可能和我們要解決的問題還有一定的距離。因此,我們往往會在得到預訓練的embedding向量後,用少量人工標註的樣本去fine-tune整個模型。
相比之下,端對端的有監督模型在最近幾年裡越來越受到人們的關注。與無監督模型相比,端對端的模型在結構上往往更加複雜。同時,也因為有著明確的任務導向,端對端模型學習到的embedding向量也往往更加準確。例如,通過一個embedding層和若干個卷積層連線而成的深度神經網路以實現對句子的情感分類,可以學習到語義更豐富的詞向量表達。
3.個人對word embedding的理解 現在,詞向量既能夠降低維度,又能夠capture到當前詞在本句子中上下文的資訊(表現為前後距離關係),那麼我們對其用來表示語言句子詞語作為NN的輸入是非常自信與滿意的。
另外一點很實用的建議,在你做某一項具體的NLP任務時如你要用到詞向量,那麼我建議你:要麼1、選擇使用別人訓練好的詞向量,注意,得使用相同語料內容領域的詞向量;要麼2、自己訓練自己的詞向量。我建議是前者,因為……坑太多了。
七、後言
說到這裡,其實我並沒有想繼續說下去的打算了,即並沒有打算將word2vec的數學原理、詳解啥的統統來一頓講了,因為我發現網上關於講解word2vec的文章實在是太多了,多到幾乎所有的文章都是一樣的。所以我也沒有必要再copy一份過來咯。
所以,要詳細瞭解word2vec、cbow、skip-gram細節的請您仔細搜尋。我相信,在瞭解了這一系列的前提上下文知識的背景下,你再去讀word2vec相關的細節文章時,一定不會感到有多吃力。
另外這也反映出來了一個更大的問題,即網路文章缺少critical思維的原創性。
網上隨便一搜“word2vec”、“詞向量”,然後一大堆的關於word2vec、cbow、skip-gram數學公式的講解,並且還都是千篇一律的東西……但最讓人無法理解的是,基本上沒有人去詳細地提一提這些東西他的出現他的存在的上下文、他的發展的過程、他在整個相關技術框架的所處位置等等。這讓我很鬱悶……
其實順便分享下,在我個人的方法論思維中,一個帶有完整上下文以及結構構建良好的知識框架,在某種程度上,比一些細枝末節的詳細知識點來的重要的多了!因為,一旦構建了一個完備的知識結構框架,那麼剩下你要做的是將一些零零碎碎的細節進行填補而已;而反過來卻根本不行,知識堆砌只會讓你思維混亂,走不了多遠。
所以here我也呼籲各位blogger,大家能充分發揮自己的能動性,主動去創造一些沒有的東西,分享一些獨有的思維見解,也算是對中國網路blog以及CS事業的推動貢獻啊!I mean,即便是copy別人的原來的東西,也最好是咀嚼咀嚼,消化後加上自己的東西再share啊!
References:《How to Generate a Good Word Embedding?》,Siwei Lai, Kang Liu, Liheng Xu, Jun Zhao《基於神經網路的詞和文件語義向量表示方法研究》,來斯惟《面向自然語言處理的分散式表示學習》,邱錫鵬《Deep Learning 實戰之 word2vec》