分析鳶尾花資料集
阿新 • • 發佈:2019-01-01
3. 邏輯迴歸分析
從圖中可以看出,資料集線性可分的,可以劃分為3類,分別對應三種類型的鳶尾花,下面採用邏輯迴歸對其進行分類預測。前面使用X=[x[0] for x in DD]獲取第一列資料,Y=[x[1] for x in DD]獲取第二列資料,這裡採用另一種方法,iris.data[:, :2]獲取其中兩列資料(兩個特徵),完整程式碼如下:
下面作者對匯入資料集後的程式碼進行詳細講解。import matplotlib.pyplot as plt import numpy as np from sklearn.datasets import load_iris from sklearn.linear_model import LogisticRegression #載入資料集 iris = load_iris() X = X = iris.data[:, :2] #獲取花卉兩列資料集 Y = iris.target #邏輯迴歸模型 lr = LogisticRegression(C=1e5) lr.fit(X,Y) #meshgrid函式生成兩個網格矩陣 h = .02 x_min, x_max = X[:, 0].min() - .5, X[:, 0].max() + .5 y_min, y_max = X[:, 1].min() - .5, X[:, 1].max() + .5 xx, yy = np.meshgrid(np.arange(x_min, x_max, h), np.arange(y_min, y_max, h)) #pcolormesh函式將xx,yy兩個網格矩陣和對應的預測結果Z繪製在圖片上 Z = lr.predict(np.c_[xx.ravel(), yy.ravel()]) Z = Z.reshape(xx.shape) plt.figure(1, figsize=(8,6)) plt.pcolormesh(xx, yy, Z, cmap=plt.cm.Paired) #繪製散點圖 plt.scatter(X[:50,0], X[:50,1], color='red',marker='o', label='setosa') plt.scatter(X[50:100,0], X[50:100,1], color='blue', marker='x', label='versicolor') plt.scatter(X[100:,0], X[100:,1], color='green', marker='s', label='Virginica') plt.xlabel('Sepal length') plt.ylabel('Sepal width') plt.xlim(xx.min(), xx.max()) plt.ylim(yy.min(), yy.max()) plt.xticks(()) plt.yticks(()) plt.legend(loc=2) plt.show()
lr = LogisticRegression(C=1e5)
lr.fit(X,Y)
初始化邏輯迴歸模型並進行訓練,C=1e5表示目標函式。
x_min, x_max = X[:, 0].min() - .5, X[:, 0].max() + .5
y_min, y_max = X[:, 1].min() - .5, X[:, 1].max() + .5
xx, yy = np.meshgrid(np.arange(x_min, x_max, h), np.arange(y_min, y_max, h))
獲取的鳶尾花兩列資料,對應為花萼長度和花萼寬度,每個點的座標就是(x,y)。 先取X二維陣列的第一列(長度)的最小值、最大值和步長h(設定為0.02)生成陣列,再取X二維陣列的第二列(寬度)的最小值、最大值和步長h生成陣列, 最後用meshgrid函式生成兩個網格矩陣xx和yy,如下所示:
[[ 3.8 3.82 3.84 ..., 8.36 8.38 8.4 ] [ 3.8 3.82 3.84 ..., 8.36 8.38 8.4 ] ..., [ 3.8 3.82 3.84 ..., 8.36 8.38 8.4 ] [ 3.8 3.82 3.84 ..., 8.36 8.38 8.4 ]] [[ 1.5 1.5 1.5 ..., 1.5 1.5 1.5 ] [ 1.52 1.52 1.52 ..., 1.52 1.52 1.52] ..., [ 4.88 4.88 4.88 ..., 4.88 4.88 4.88] [ 4.9 4.9 4.9 ..., 4.9 4.9 4.9 ]]
Z = lr.predict(np.c_[xx.ravel(), yy.ravel()])
呼叫ravel()函式將xx和yy的兩個矩陣轉變成一維陣列,由於兩個矩陣大小相等,因此兩個一維陣列大小也相等。np.c_[xx.ravel(), yy.ravel()]是獲取矩陣,即:
xx.ravel() [ 3.8 3.82 3.84 ..., 8.36 8.38 8.4 ] yy.ravel() [ 1.5 1.5 1.5 ..., 4.9 4.9 4.9] np.c_[xx.ravel(), yy.ravel()] [[ 3.8 1.5 ] [ 3.82 1.5 ] [ 3.84 1.5 ] ..., [ 8.36 4.9 ] [ 8.38 4.9 ] [ 8.4 4.9 ]]
總結下:上述操作是把第一列花萼長度資料按h取等分作為行,並複製多行得到xx網格矩陣;再把第二列花萼寬度資料按h取等分,作為列,並複製多列得到yy網格矩陣;最後將xx和yy矩陣都變成兩個一維陣列,呼叫np.c_[]函式組合成一個二維陣列進行預測。
呼叫predict()函式進行預測,預測結果賦值給Z。即:
Z = logreg.predict(np.c_[xx.ravel(), yy.ravel()])
[1 1 1 ..., 2 2 2]
size: 39501Z = Z.reshape(xx.shape)
呼叫reshape()函式修改形狀,將其Z轉換為兩個特徵(長度和寬度),則39501個數據轉換為171*231的矩陣。Z = Z.reshape(xx.shape)輸出如下:
[[1 1 1 ..., 2 2 2]
[1 1 1 ..., 2 2 2]
[0 1 1 ..., 2 2 2]
...,
[0 0 0 ..., 2 2 2]
[0 0 0 ..., 2 2 2]
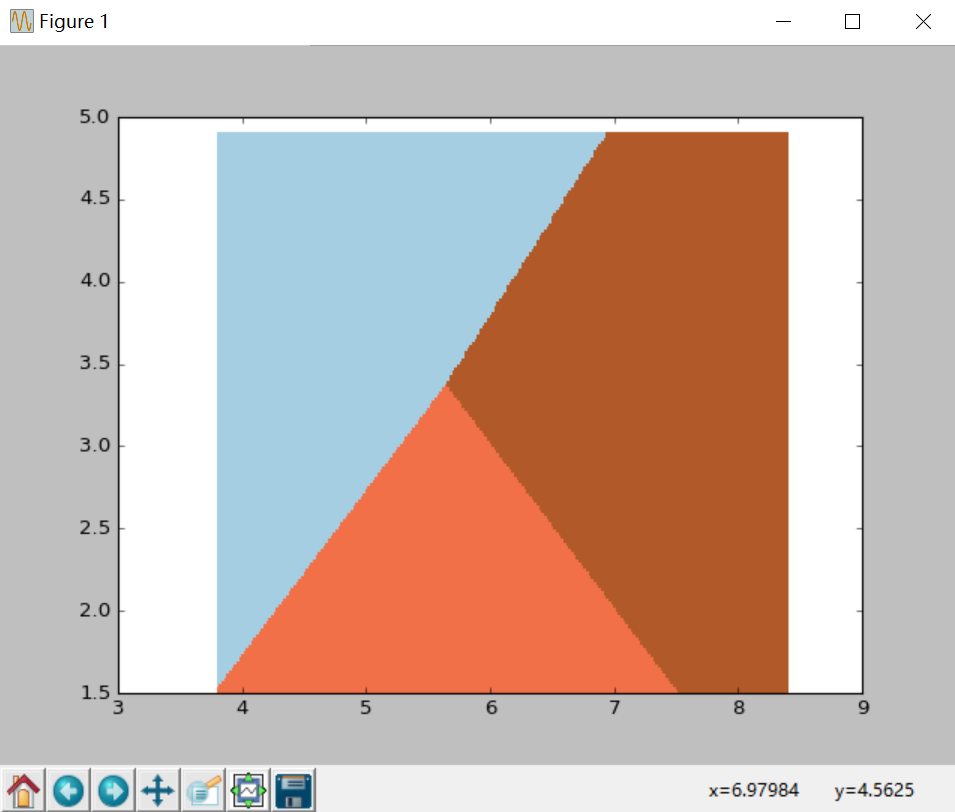
[0 0 0 ..., 2 2 2]]plt.pcolormesh(xx, yy, Z, cmap=plt.cm.Paired)
呼叫pcolormesh()函式將xx、yy兩個網格矩陣和對應的預測結果Z繪製在圖片上,可以發現輸出為三個顏色區塊,分佈表示分類的三類區域。cmap=plt.cm.Paired表示繪圖樣式選擇Paired主題。輸出的區域如下圖所示: