
sklearn iris(鳶尾花)資料集應用
資料背景
由Fisher在1936年整理,包含4個特徵(Sepal.Length(花萼長度)、Sepal.Width(花萼寬度)、Petal.Length(花瓣長度)、Petal.Width(花瓣寬度)),特徵值都為正浮點數,單位為釐米。目標值為鳶尾花的分類(Iris Setosa(山鳶尾)、Iris Versicolour(雜色鳶尾),Iris Virginica(維吉尼亞鳶尾))。
測試程式碼
新建lr_riis.py檔案,編寫程式碼
# -*- coding:utf-8 -*-
import numpy as np
from sklearn import datasets
from 執行結果為:
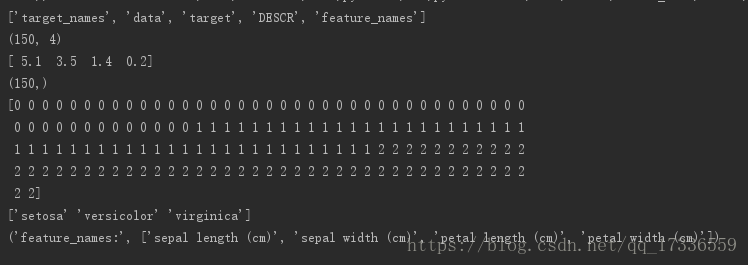
由結果可知:
iris中有5個key值
iris.data 包含了四個特徵值,例如[5.1, 3.5, 1.4, 0.2]
iris.target為目標值
iris.feature_names為特徵名稱
模型預測實踐
重新更新下程式碼
# -*- coding:utf-8 -*-
import numpy as np
from sklearn import datasets
from 執行結果為:
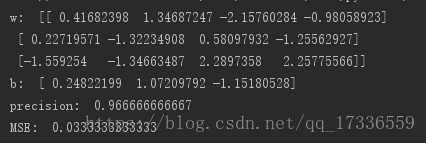
相關推薦
sklearn iris(鳶尾花)資料集應用
資料背景 由Fisher在1936年整理,包含4個特徵(Sepal.Length(花萼長度)、Sepal.Width(花萼寬度)、Petal.Length(花瓣長度)、Petal.Width(花瓣寬度)),特徵值都為正浮點數,單位為釐米。目標值為鳶尾花的分類(
人工智慧考試——k近鄰演算法對鳶尾花(iris)資料集進行分析
一、題目 通過修改提供的k_nn.c檔案,讀取鳶尾花的資料集,其中iris_training_set.txt和iris_test_set.txt分別為訓練集和測試集,兩個資料集中最後一列為類別標籤,其餘列為表示花瓣和萼片長度和寬度的輸入特徵。通過計算測試集中的每個輸入行和訓
java實現k-means演算法(用的鳶尾花iris的資料集,從mysq資料庫中讀取資料)
k-means演算法又稱k-均值演算法,是機器學習聚類演算法中的一種,是一種基於形心的劃分方法,其中每個簇的中心都用簇中所有物件的均值來表示。其思想如下: 輸入: k:簇的數目;D:包含n個物件的資料集。輸出:k個簇的集合。 方法: 從D中隨機選擇幾個物件作為起始質心
決策樹分類鳶尾花資料集
import numpy as np import pandas as pd import matplotlib as mpl import matplotlib.pyplot as plt from sklearn.tree import DecisionTreeClassifier iris_
Logistics迴歸分類鳶尾花資料集
import numpy as np from sklearn.linear_model import LogisticRegression import matplotlib.pyplot as plt import matplotlib as mpl import pandas as pd fr
分類問題(一):SVM(Python——基於skearn實現鳶尾花資料集分類)
第一步: # -*- coding: utf-8 -*- """ Created on Fri Sep 21 14:26:25 2018 @author: bd04 """ # !/usr/bin/env python # encoding: utf-8 __auth
Tensorflow訓練鳶尾花資料集
圖片資料集:鳶尾花 (一共五個類別) { 資料集連結:https://pan.baidu.com/s/1l86AiiVibPI03qWslEyqZA 密碼:oq5d } 程式程式碼如下: # -*- coding: utf-8 -*- from skimage im
【python資料探勘課程】十九.鳶尾花資料集視覺化、線性迴歸、決策樹花樣分析
這是《Python資料探勘課程》系列文章,也是我這學期上課的部分內容。本文主要講述鳶尾花資料集的各種分析,包括視覺化分析、線性迴歸分析、決策樹分析等,通常一個數據集是可以用於多種分析的,希望這篇文章對大
分析鳶尾花資料集
3. 邏輯迴歸分析從圖中可以看出,資料集線性可分的,可以劃分為3類,分別對應三種類型的鳶尾花,下面採用邏輯迴歸對其進行分類預測。前面使用X=[x[0] for x in DD]獲取第一列資料,Y=[x[1] for x in DD]獲取第二列資料,這裡採用另一種方法,iris.data[:, :2]獲取其中兩
Python sklearn包——mnist資料集下不同分類器的效能實驗
Preface:使用scikit-learn各種分類演算法對資料進行處理。 2.2、Scikit-learn的測試 scikit-learn已經包含在Anaconda中。也可以在官方下載原始碼包進行安裝。本文程式碼裡封裝瞭如下機器學習演算法,我們修改資料載入函式,即可
樸素貝葉斯對鳶尾花資料集進行分類
注:本人純粹為了練手熟悉各個方法的用法 使用高斯樸素貝葉斯對鳶尾花資料進行分類 程式碼: 1 # 通過樸素貝葉斯對鳶尾花資料進行分類 2 3 from sklearn import datasets 4 from sklearn.model_selection import train_
資料探勘之鳶尾花資料集分析
因為手上沒有iris.data資料,只能通過在sklearn中載入原始資料,並將其轉換為Dataframe格式 主要內容:資料分佈的視覺化(特徵之間分佈、特徵內部、分類精度、熱力圖) 演算法:決策樹 隨機森林 import pandas as pd from skle
實現鳶尾花資料集分類
轉自:http://blog.csdn.net/jasonding1354/article/details/42143659 引入 一個機器可以根據照片來辨別鮮花的品種嗎?在機器學習角度,這其實是一個分類問題,即機器根據不同品種鮮花的資料進行學習,使其可以對未標記的測
XGBoost實現對鳶尾花資料集分類預測
code:import xgboost as xgb import numpy as np import pandas as pd from sklearn.model_selection import
人工智慧深度學習TensorFlow通過感知器實現鳶尾花資料集分類
一.iris資料集簡介 iris資料集的中文名是安德森鳶尾花卉資料集,英文全稱是Anderson’s Iris data set。iris包含150個樣本,對應資料集的每行資料。每行資料包含每個樣本的四個特徵和樣本的類別資訊,所以iris資料集是一個150行5列的二維表。 通俗地說,iris
DL之NN:(sklearn自帶資料集為1797個樣本*64個特徵)利用NN之sklearn、NeuralNetwor.py實現手寫數字圖片識別95%準確率
先檢視sklearn自帶digits手寫資料集(1797*64)import numpy as np from sklearn.datasets import load_digits from skl
(參評)機器學習筆記——鳶尾花資料集(KNN、決策樹、樸素貝葉斯分析)
最開始選取鳶尾花資料集來了解決策樹模型時,筆者是按照學習報告的形式來寫得,在這裡將以原形式上傳。格式較為繁複,希望讀者可以耐心看完,謝謝大家。目錄 6.總結 7.問題 1、問題描述 iris是鳶尾植物,這裡儲存了其萼片和花瓣的長寬,共4個屬性,鳶尾
[Java][機器學習]用決策樹分類演算法對Iris花資料集進行處理
Iris Data Set是很經典的一個數據集,在很多地方都能看到,一般用於教學分類演算法。這個資料集在UCI Machine Learning Repository裡可以找到(還是下載量排第一的資料喲)。這個資料集裡面,每個資料都包含4個值(sepal len
利用線性函式實現鳶尾花資料集分類
在空間中,我們定義分類的線性函式為:g(x)=wTx+bg(x)=w^{T}x+bg(x)=wTx+b 其中樣本x=(x1,x2,...,xl)Tx=(x_{1},x_{2},...,x_{l})^{T}x=(x1,x2,...,xl)T,權向量w=(w1
Google機器學習(二) 鳶尾花資料集(load_iris) 決策樹
Google深度學習系列視訊 ____tz_zs學習筆記 一、在Spyder中寫第一個機器學習的程式: 這裡使用的分類器是決策樹 from sklearn import tree feature = [[140,1],[130,1],[150,0],[170,