
基於CNN的影象修復(CNN-based Image Inpainting)
阿新 • • 發佈:2019-01-01
本文簡單介紹兩篇基於CNN進行影象修復的論文,論文以及原始碼分別為:
兩篇論文的網路框架基本一樣:
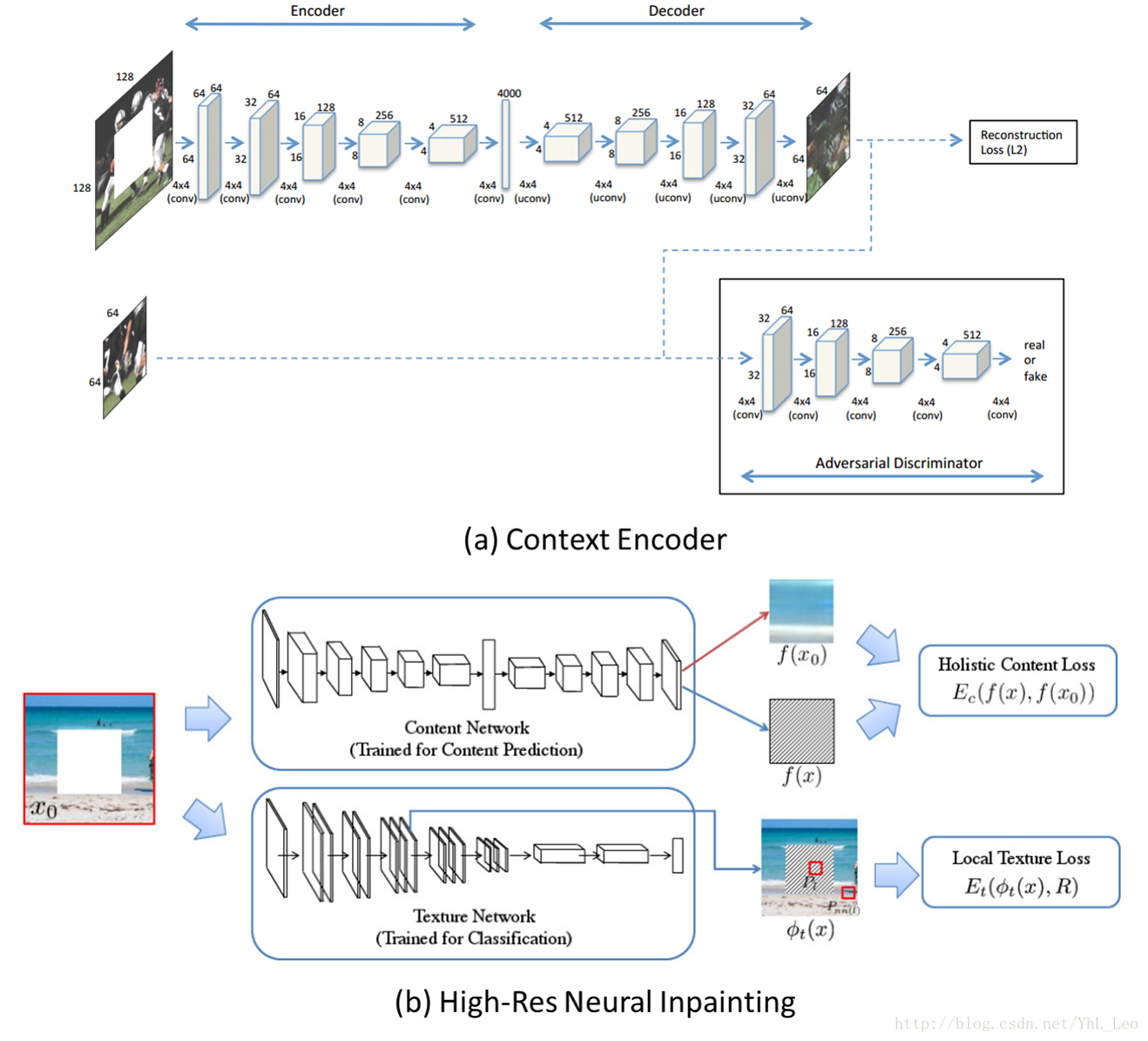
主要思路都是結合Encoder-Decoder 網路結構和 GAN (Generative Adversarial Networks),Encoder-Decoder 階段用於學習影象特徵和生成影象待修補區域對應的預測圖,GAN部分用於判斷預測圖來自訓練集和預測集的可能性,當生成的預測圖與GroundTruth在影象內容上達到一致,並且GAN的判別器無法判斷預測圖是否來自訓練集或預測集時,就認為網路模型引數達到了最優狀態。
因此,網路訓練的過程中損失函式都由兩部分組成:
- Encoder-decoder 部分的影象內容約束(Reconstruction Loss)
- GAN部分的對抗損失(Adversarial Loss)
其中,兩篇論文在Adversarial Loss都是一致的,發表的時間也早於WassersteinGAN,所以並沒有在這方面進行改進。所以,兩者的主要差異就在Reconstruction Loss。
Context Encoders 採用最簡單的整體內容約束,也就是預測圖與原圖的
詳細內容可以閱讀原文。
貼出一組對比圖:

References: