
基於圖的圖像分割(Graph-Based Image Segmentation)
一、介紹
基於圖的圖像分割(Graph-Based Image Segmentation),論文《Efficient Graph-Based Image Segmentation》,P. Felzenszwalb, D. Huttenlocher,International Journal of Computer Vision, Vol. 59, No. 2, September 2004
論文下載和論文提供的C++代碼在這裏。
Graph-Based Segmentation是經典的圖像分割算法,其作者Felzenszwalb也是提出DPM(Deformable Parts Model)算法的大牛。
Graph-Based Segmentation算法是基於圖的貪心聚類算法,實現簡單,速度比較快,精度也還行。不過,目前直接用它做分割的應該比較少,很多算法用它作墊腳石,比如Object Propose的開山之作《Segmentation as Selective Search for Object Recognition》就用它來產生過分割(over segmentation)。
二、圖的基本概念
因為該算法是將圖像用加權圖抽象化表示,所以補充圖的一些基本概念。
1、圖
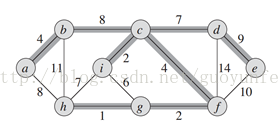
是由頂點集V(vertices)和邊集E(edges)組成,表示為G=(V, E),頂點v∈V,在論文即為單個的像素點
2、樹
特殊的圖,圖中任意兩個頂點,都有路徑相連接,但是沒有回路。如下圖中加粗的邊所連接而成的圖。如果看成一團亂連的珠子,只保留樹中的珠子和連線,那麽隨便選個珠子,都能把這棵樹中所有的珠子都提起來。
如果頂點i和h這條邊也保留下來,那麽頂點h,i,c,f,g就構成了一個回路。
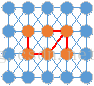
3、最小生成樹(minimum spanning tree)
特殊的樹,給定需要連接的頂點,選擇邊權之和最小的樹。
論文中,初始化時每一個像素點都是一個頂點,然後逐漸合並得到一個區域,確切地說是連接這個區域中的像素點的一個MST。如下圖,棕色圓圈為頂點,線段為邊,合並棕色頂點所生成的MST,對應的就是一個分割區域。分割後的結果其實就是森林。
三、相似性
既然是聚類算法,那應該依據何種規則判定何時該合二為一,何時該繼續劃清界限呢?對於孤立的兩個像素點,所不同的是灰度值,自然就用灰度的距離來衡量兩點的相似性,本文中是使用RGB的距離,即

當然也可以用perceptually uniform的Luv或者Lab色彩空間,對於灰度圖像就只能使用亮度值了,此外,還可以先使用紋理特征濾波,再計算距離,比如先做Census Transform再計算Hamming distance距離。
四、全局閾值 >> 自適應閾值,區域的類內差異、類間差異
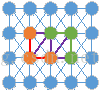
上面提到應該用亮度值之差來衡量兩個像素點之間的差異性。對於兩個區域(子圖)或者一個區域和一個像素點的相似性,最簡單的方法即只考慮連接二者的邊的不相似度。如下圖,已經形成了棕色和綠色兩個區域,現在通過紫色邊來判斷這兩個區域是否合並。那麽我們就可以設定一個閾值,當兩個像素之間的差異(即不相似度)小於該值時,合二為一。叠代合並,最終就會合並成一個個區域,效果類似於區域生長:星星之火,可以燎原。
舉例說明:

對於上右圖,顯然應該聚成上左圖所示的3類:高頻區h,斜坡區s,平坦區p。
如果我們設置一個全局閾值,那麽如果h區要合並成一塊的話,那麽該閾值要選很大,但是那樣就會把p和s區域也包含進來,分割結果太粗。如果以p為參考,那麽閾值應該選特別小的值,那樣的話p區是會合並成一塊,但是h區就會合並成特別特別多的小塊,如同一面支離破碎的鏡子,分割結果太細。顯然,全局閾值並不合適,那麽自然就得用自適應閾值。對於p區該閾值要特別小,s區稍大,h區巨大。
先來兩個定義,原文依據這兩個附加信息來得到自適應閾值。
一個區域內的類內差異Int(C):

可以近似理解為一個區域內部最大的亮度差異值,定義是MST中不相似度最大的一條邊。
倆個區域的類間差異Diff(C1, C2):

即連接兩個區域所有邊中,不相似度最小的邊的不相似度,也就是兩個區域最相似的地方的不相似度。
直觀的判斷,當:

時,兩個區域應當合並!
五、算法步驟
1、計算每一個像素點與其8鄰域或4鄰域的不相似度。
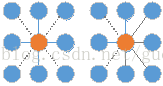
如上圖,實線為只計算4領域,加上虛線就是計算8鄰域,由於是無向圖,按照從左到右,從上到下的順序計算的話,只需要計算右圖中灰色的線即可。
2、將邊按照不相似度non-decreasing排列(從小到大)排序得到e1, e2, ..., en。
3、選擇ei
4、對當前選擇的邊ej(vi和vj不屬於一個區域)進行合並判斷。設其所連接的頂點為(vi, vj),
if 不相似度小於二者內部不相似度:
5、更新閾值以及類標號
else:
6、如果i < n,則按照排好的順序,選擇下一條邊轉到Step 4,否則結束。
六、論文提供的代碼
打開本博文最開始的連接,進入論文網站,下載C++代碼。下載後,make編譯程序。命令行運行格式:
/******************************************** sigma 對原圖像進行高斯濾波去噪 k 控制合並後的區域的數量 min: 後處理參數,分割後會有很多小區域,當區域像素點的個數小於min時,選擇與其差異最小的區域合並 input 輸入圖像(PPM格式) output 輸出圖像(PPM格式) sigma: Used to smooth the input image before segmenting it. k: Value for the threshold function. min: Minimum component size enforced by post-processing. input: Input image. output:Output image. Typical parameters are sigma = 0.5, k = 500, min = 20. Larger values for k result in larger components in the result. */ ./segment sigma k min input output
七、OpenCV3.3 cv::ximgproc::segmentation::GraphSegmentation類
/opencv_contrib/modules/ximgproc/include/opencv2/ximgproc/segmentation.hpp
基於圖的圖像分割(Graph-Based Image Segmentation)