
tensorflow1: nn與cnn實現情感分類
0.資料集以及執行環境
資料集的地址:情緒分析的資料集,能稍微看懂英文就應該知道如何下載了
執行環境:Windows10,IDE:pycharm或者是Linux
0.資料預處理
"0","1467810369","Mon Apr 06 22:19:45 PDT 2009","NO_QUERY","_TheSpecialOne_","@switchfoot http://twitpic.com/2y1zl - Awww, that's a bummer. You shoulda got David Carr of Third Day to do it. ;D"上圖是原始資料的情況,總共有6個欄位,主要是第一個欄位(情感評價的結果)以及最後一個欄位(tweet內容)是有用的。針對csv檔案,我們使用pandas進行讀取然後進行處理。處理的程式碼如下:
# 提取檔案中的有用的欄位 def userfull_filed(org_file, outuput_file): data = pd.read_csv(os.path.join(data_dir, org_file), header=None, encoding='latin-1') clf = data.values[:, 0] content = data.values[:, -1] new_clf = [] for temp in clf: # 這個處理就是將情感評論結果進行所謂的one_hot編碼 if temp == 0: new_clf.append([1, 0]) # 消極評論 # elif temp == 2: # new_clf.append([0, 1, 0]) # 中性評論 else: new_clf.append([0, 1]) # 積極評論 df = pd.DataFrame(np.c_[new_clf, content], columns=['emotion0', 'emotion1', 'content']) df.to_csv(os.path.join(data_dir, outuput_file), index=False)
這樣處理的原因是,將情感評論值變成一個one-hot編碼形式,這樣我們進行nn或者是cnn處理的最後一層的輸出單元為2(但有個巨大的bug那就是實際上訓練集沒有中性評論)
接下來利用nltk(這個簡直是英語文字的自然語言的神奇呀)來生成單詞集合,程式碼如下:
def sentence_english_manage(line): # 英文句子的預處理 pattern = re.compile(r"[!#$%&'()*+,-./:;<=>[email protected][\]^_`{|}~0123456789]") line = re.sub(pattern, '', line) # line = [word for word in line.split() if word not in stopwords] return line def create_lexicon(train_file): lemmatizer = WordNetLemmatizer() df = pd.read_csv(os.path.join(data_dir, train_file)) count_word = {} # 統計單詞的數量 all_word = [] for content in df.values[:, 2]: words = word_tokenize(sentence_english_manage(content.lower())) # word_tokenize就是一個分詞處理的過程 for word in words: word = lemmatizer.lemmatize(word) # 提取該單詞的原型 all_word.append(word) # 儲存所有的單詞 count_word = Counter(all_word) # count_word = OrderetodDict(sorted(count_word.items(), key=lambda t: t[1])) lex = [] for word in count_word.keys(): if count_word[word] < 100000 and count_word[word] > 100: # 過濾掉一些單詞 lex.append(word) with open('lexcion.pkl', 'wb') as file_write: pickle.dump(lex, file_write) return lex, count_word
最後生成一個只含有有用資訊的文字內容
1.利用NN進行文字情感分類
1.1神經網路結構的搭建
在這裡我設計了兩層的隱藏層,單元數分別為1500/1500。神經網路的整個結構程式碼如下:
with open('lexcion.pkl', 'rb') as file_read:
lex = pickle.load(file_read)
n_input_layer = len(lex) # 輸入層的長度
n_layer_1 = 1500 # 有兩個隱藏層
n_layer_2 = 1500
n_output_layer = 2 # 輸出層的大小
X = tf.placeholder(shape=(None, len(lex)), dtype=tf.float32, name="X")
Y = tf.placeholder(shape=(None, 2), dtype=tf.float32, name="Y")
batch_size = 500
dropout_keep_prob = tf.placeholder(tf.float32)
def neural_network(data):
layer_1_w_b = {
'w_': tf.Variable(tf.random_normal([n_input_layer, n_layer_1])),
'b_': tf.Variable(tf.random_normal([n_layer_1]))
}
layer_2_w_b = {
'w_': tf.Variable(tf.random_normal([n_layer_1, n_layer_2])),
'b_': tf.Variable(tf.random_normal([n_layer_2]))
}
layer_output_w_b = {
'w_': tf.Variable(tf.random_normal([n_layer_2, n_output_layer])),
'b_': tf.Variable(tf.random_normal([n_output_layer]))
}
# wx+b
# 這裡有點需要注意那就是最後輸出層不需要加啟用函式
# 同時加入了dropout引數
full_conn_dropout_1 = tf.nn.dropout(data, dropout_keep_prob)
layer_1 = tf.add(tf.matmul(full_conn_dropout_1, layer_1_w_b['w_']), layer_1_w_b['b_'])
layer_1 = tf.nn.sigmoid(layer_1)
full_conn_dropout_2 = tf.nn.dropout(layer_1, dropout_keep_prob)
layer_2 = tf.add(tf.matmul(full_conn_dropout_2, layer_2_w_b['w_']), layer_2_w_b['b_'])
layer_2 = tf.nn.sigmoid(layer_2)
layer_output = tf.add(tf.matmul(layer_2, layer_output_w_b['w_']), layer_output_w_b['b_'])
# layer_output = tf.nn.softmax(layer_output)
return layer_output比起我看的程式碼,這裡我加入了dropout的引數,使得訓練不會過擬合。但實際操作中,我發現加不加這個資料對於整個實驗的影響並沒有那麼大。
1.2獲取訓練與測試資料
原本的教程其實有一套自己的提取資料的過程,但我看了一眼感覺有些麻煩,我就自己寫了一個數據提取的方法,程式碼如下:
def get_random_n_lines(i, data, batch_size):
# 從訓練集中找訓批量訓練的資料
# 這裡的邏輯需要理解,同時我們要理解要從積極與消極的兩個集合中分層取樣
if ((i * batch_size) % len(data) + batch_size) > len(data):
rand_index = np.arange(start=((i*batch_size) % len(data)),
stop=len(data))
else:
rand_index = np.arange(start=((i*batch_size) % len(data)),
stop=((i*batch_size) % len(data) + batch_size))
return data[rand_index, :]
def get_test_data(test_file):
# 獲取測試集的資料用於測試
lemmatizer = WordNetLemmatizer()
df = pd.read_csv(os.path.join('data', test_file))
# groups = df.groupby('emotion1')
# group_neg_pos = groups.get_group(0).values # 獲取非中性評論的資訊
group_neg_pos = df.values
test_x = group_neg_pos[:, 2]
test_y = group_neg_pos[:, 0:2]
new_test_x = []
for tweet in test_x:
words = word_tokenize(tweet.lower())
words = [lemmatizer.lemmatize(word) for word in words]
features = np.zeros(len(lex))
for word in words:
if word in lex:
features[lex.index(word)] = 1
new_test_x.append(features)
return new_test_x, test_y上面是提取訓練集所需的程式碼,設計了一個提取一個batch_size大小的資料,因為我是分別從積極評論與消極評論中分別提取一定量的資料,所以要呼叫兩次該程式碼。
下面這個則是提取測試集的程式碼,借用了詞袋模型的思想,對一條tweet在字典長度的維度上進行一個編碼過程。其實訓練集也是這樣處理的,但我寫了兩次有點傻。
1.3訓練過程
借用別人部落格中的程式碼,我進行了細微的修改,主要調整了程式碼的部分位置,添加了tensorboard的內容以及模型儲存的內容,程式碼如下:
def train_neural_network():
# 配置tensorboard
tensorboard_dir = "tensorboard/nn"
if not os.path.exists(tensorboard_dir):
os.makedirs(tensorboard_dir)
# 損失函式
predict = neural_network(X)
cost_func = tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits(logits=predict, labels=Y))
tf.summary.scalar("loss", cost_func)
optimizer = tf.train.AdamOptimizer().minimize(cost_func)
# 準確率
correct = tf.equal(tf.argmax(predict, 1), tf.argmax(Y, 1))
accuracy = tf.reduce_mean(tf.cast(correct, 'float'))
tf.summary.scalar("accuracy", accuracy)
merged_summary = tf.summary.merge_all()
writer = tf.summary.FileWriter(tensorboard_dir)
df = pd.read_csv(os.path.join('data', 'new_train_data.csv'))
# data = df.values
group_by_emotion0 = df.groupby('emotion0')
group_neg = group_by_emotion0.get_group(0).values
group_pos = group_by_emotion0.get_group(1).values
test_x, test_y = get_test_data('new_test_data.csv')
with tf.Session() as sess:
sess.run(tf.initialize_all_variables())
writer.add_graph(sess.graph)
lemmatizer = WordNetLemmatizer() # 判斷詞幹所用的
saver = tf.train.Saver()
i = 0
# pre_acc = 0 # 儲存前一次的準確率以和後一次的進行比較
while i < 5000:
rand_neg_data = get_random_n_lines(i, group_neg, batch_size)
rand_pos_data = get_random_n_lines(i, group_pos, batch_size)
rand_data = np.vstack((rand_neg_data, rand_pos_data)) # 矩陣合併
np.random.shuffle(rand_data) # 打亂順序
batch_y = rand_data[:, 0:2] # 獲取得分情況
batch_x = rand_data[:, 2] # 獲取內容資訊
new_batch_x = []
for tweet in batch_x:
words = word_tokenize(tweet.lower())
words = [lemmatizer.lemmatize(word) for word in words]
features = np.zeros(len(lex))
for word in words:
if word in lex:
features[lex.index(word)] = 1 # 一個句子中某個詞可能出現兩次,可以用+=1,其實區別不大
new_batch_x.append(features)
# batch_y = group_neg[:, 0: 3] + group_pos[:, 0: 3]
loss, _, train_acc = sess.run([cost_func, optimizer, accuracy],
feed_dict={X: new_batch_x, Y: batch_y, dropout_keep_prob: 0.6})
if i % 100 == 0:
print("第{}次迭代,損失函式為{}, 訓練的準確率為{}".format(i, loss, train_acc))
s = sess.run(merged_summary, feed_dict={X: new_batch_x, Y: batch_y, dropout_keep_prob: 0.6})
writer.add_summary(s, i)
if i % 100 == 0:
# print(sess.run(accuracy, feed_dict={X: new_batch_x, Y: batch_y}))
test_acc = accuracy.eval({X: test_x[:200], Y: test_y[:200], dropout_keep_prob: 1.0})
print('測試集的準確率:', test_acc)
i += 1
if not os.path.isdir('./checkpoint'):
os.mkdir('./checkpoint')
saver.save(sess, './checkpoint/model.ckpt') # 儲存session其實這個過程沒什麼可說的,基本是一個套路。
1.4執行結果
我是在實驗室的伺服器上跑的上述程式碼,跑了幾個小時,主要感覺還是模型的儲存的時間比較長。因為整個模型的引數還是相當大的。最後的結果在tensorboard上顯示結果為:
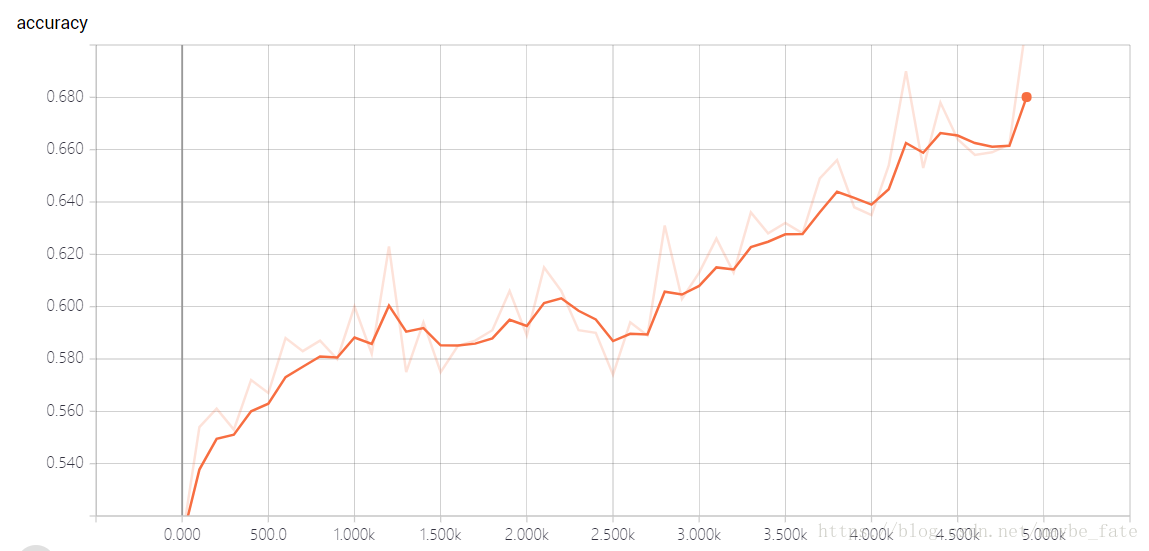
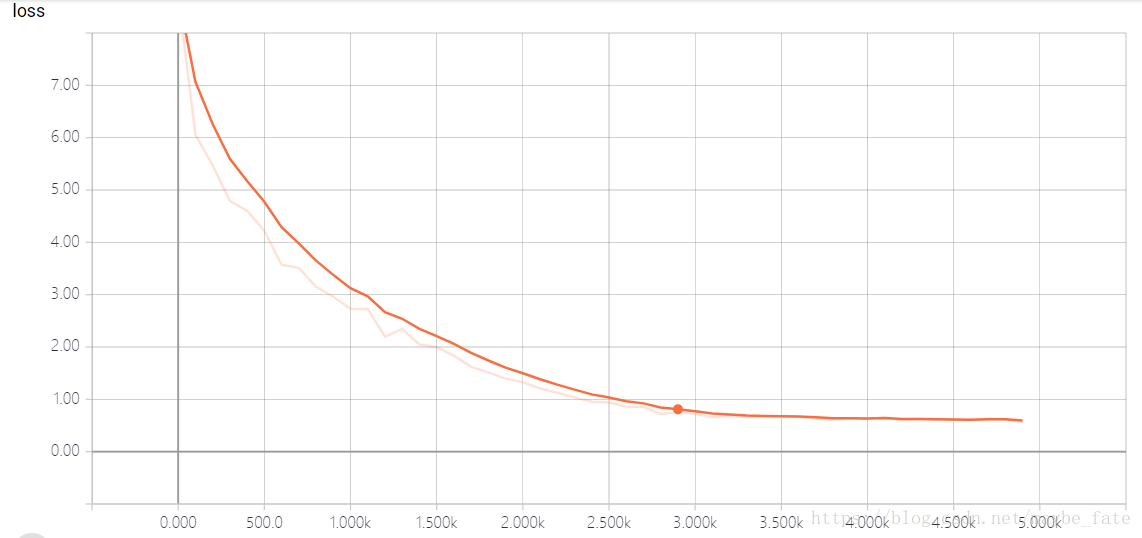
整體來說效果還可以。
2.利用CNN進行情感分類
這個專案實際上是一個CNN在NLP上的一個應用。一般而言,CNN是用來處理像影象、視訊等矩陣類的東西,而他是如何應用到自然語言的呢?我們可以引入詞嵌入矩陣這個概念,類似於Word2Vec這種東西,我們可以將一個詞語或是字元拓展為一個長度為K的特徵向量空間,這樣藉助詞袋模型,我們就可以將一個句子或是文件拓展成一個矩陣。這樣我們就可以引入卷積以及池化等方法來分析這些資料。
這裡分享一個大神的部落格,是專門針對CNN在NLP上的應用implementing-a-cnn-for-text-classification-in-tensorflow,通過這篇論文你可以充分了解如何利用tensorflow來實現分文分類以及cnn的一些解釋。情緒分析與這個是基本一致的方法,我們也可以從這篇部落格中詳細瞭解整個流程。
接下來我們開始講解CNN的情感分類的過程。從資料的預處理、CNN網路的構建、訓練這三個方面進行講解:
1.1神經網路的搭建:
這是一個重點的內容,我先引用一個圖片,然後使用程式碼慢慢解釋,圖片如下:
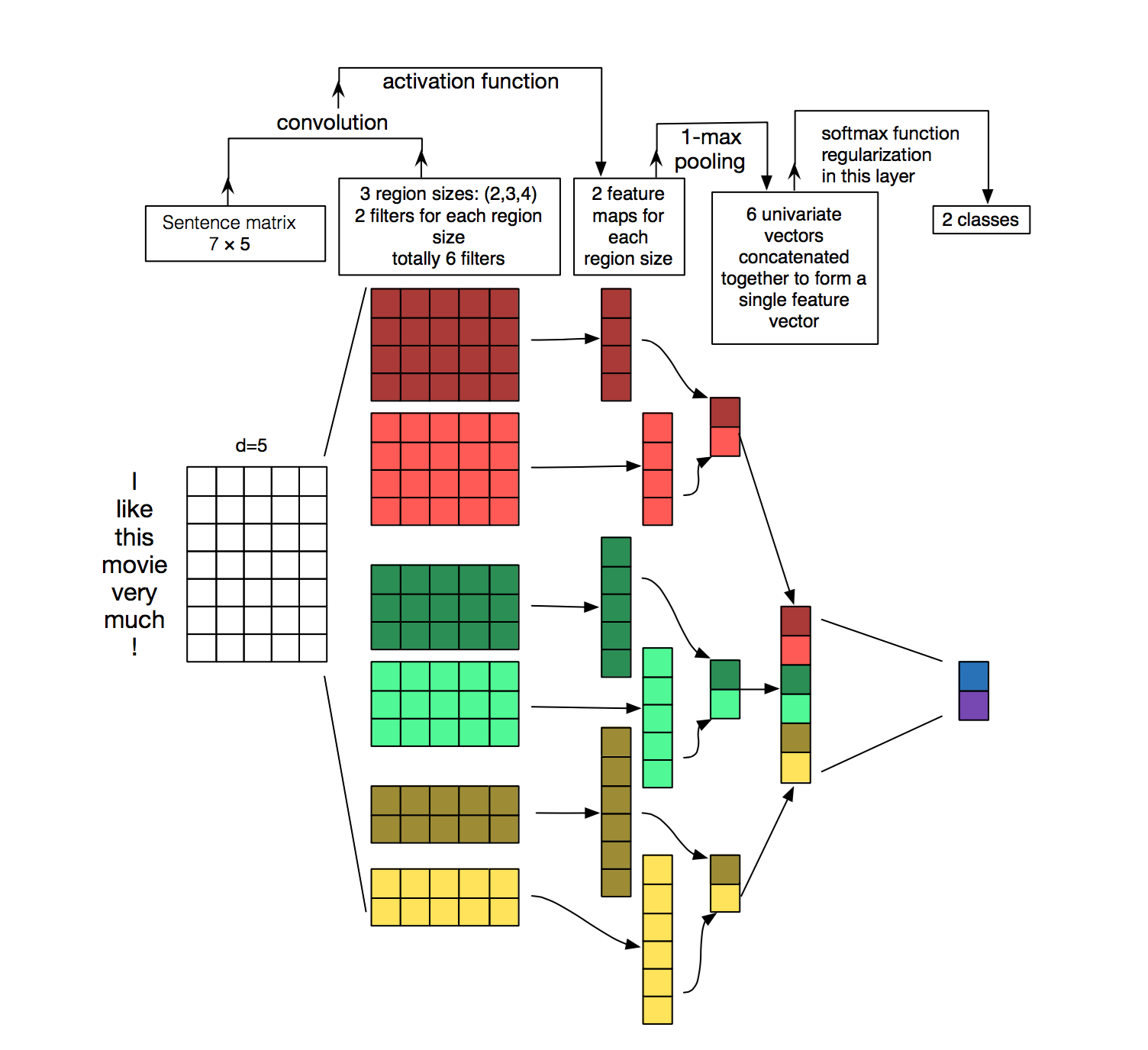
圖片有點大,順便附上程式碼:
with open('lexcion.pkl', 'rb') as file_read:
lex = pickle.load(file_read)
input_size = len(lex) # 輸入的長度
num_classes = 2 # 分類的數量
batch_size = 64
seq_length = 100 # 一個tweet的固定長度
X = tf.placeholder(tf.int32, [None, seq_length])
Y = tf.placeholder(tf.float32, [None, num_classes])
dropout_keep_prob = tf.placeholder(tf.float32)def neural_network():
'''
整個流程的解釋:
輸入為一個X,shape=[None, 8057],8057為字典的長度
首先利用embedding_lookup的方法,將X轉換為[None, 8057, 128]的向量,但有個疑惑就是emdeding_lookup的實際用法,在ceshi.py中有介紹
接著expande_dims使結果變成[None, 8057, 128, 1]的向量,但這樣做的原因不是很清楚,原因就是通道數的設定
然後進行卷積與池化:
卷積核的大小有3種,每種卷積後的feature_map的數量為128
卷積核的shape=[3/4/5, 128, 1, 128],其中前兩個為卷積核的長寬,最後一個為卷積核的數量,第三個就是通道數
卷積的結果為[None, 8057-3+1, 1, 128],矩陣的寬度已經變為1了,這裡要注意下
池化層的大小需要注意:shape=[1, 8055, 1, 1]這樣的化池化後的結果為[None, 1, 1, 128]
以上就是一個典型的文字CNN的過程
:return:
'''
''' 進行修改採用短編碼 '''
''' tf.name_scope() 與 tf.variable_scope()的作用基本一致'''
with tf.name_scope("embedding"):
embedding_size = 64
'''
這裡出現了一個問題沒有註明上限與下限
'''
# embeding = tf.get_variable("embedding", [input_size, embedding_size]) # 詞嵌入矩陣
embedding = tf.Variable(tf.random_uniform([input_size, embedding_size], -1.0, 1.0)) # 詞嵌入矩陣
# with tf.Session() as sess:
# # sess.run(tf.initialize_all_variables())
# temp = sess.run(embedding)
embedded_chars = tf.nn.embedding_lookup(embedding, X)
embedded_chars_expanded = tf.expand_dims(embedded_chars, -1) # 設定通道數
# 卷積與池化層
num_filters = 256 # 卷積核的數量
filter_sizes = [3, 4, 5] # 卷積核的大小
pooled_outputs = []
for i, filter_size in enumerate(filter_sizes):
with tf.name_scope("conv_maxpool_{}".format(filter_size)):
filter_shape = [filter_size, embedding_size, 1, num_filters] # 要注意下卷積核大小的設定
W = tf.Variable(tf.truncated_normal(filter_shape, stddev=0.1))
b = tf.Variable(tf.constant(0.1, shape=[num_filters]))
conv = tf.nn.conv2d(embedded_chars_expanded, W, strides=[1, 1, 1, 1], padding="VALID")
h = tf.nn.relu(tf.nn.bias_add(conv, b)) # 煞筆忘了加這個偏置的加法
pooled = tf.nn.max_pool(h, ksize=[1, seq_length - filter_size + 1, 1, 1],
strides=[1, 1, 1, 1], padding='VALID')
pooled_outputs.append(pooled)
num_filters_total = num_filters * len(filter_sizes)
'''
# tensor t3 with shape [2, 3]
# tensor t4 with shape [2, 3]
tf.shape(tf.concat([t3, t4], 0)) # [4, 3]
tf.shape(tf.concat([t3, t4], 1)) # [2, 6]
'''
h_pool = tf.concat(pooled_outputs, 3) # 原本是一個[None, 1, 1, 128]變成了[None, 1, 1, 384]
h_pool_flat = tf.reshape(h_pool, [-1, num_filters_total]) # 拉平處理 [None, 384]
# dropout
with tf.name_scope("dropout"):
h_drop = tf.nn.dropout(h_pool_flat, dropout_keep_prob)
# output
with tf.name_scope("output"):
# 這裡就是最後的一個全連線層處理
# from tensorflow.contrib.layers import xavier_initializer
W = tf.get_variable("w", shape=[num_filters_total, num_classes],
initializer=tf.contrib.layers.xavier_initializer()) # 這個初始化要記住
b = tf.Variable(tf.constant(0.1, shape=[num_classes]))
output = tf.nn.xw_plus_b(h_drop, W, b)
# output = tf.nn.relu(output)
return output在程式碼的最上面實際上比較詳細的介紹了整個流程,首先這個卷積過程和一般的卷積過程不一樣。卷積核是一個矩形的,其寬度與詞嵌入矩陣的維度是一樣的,他是在長度的方向進行卷積過程,實際含義就是尋找3個詞(或者是5個或者是4個)詞之間的特徵屬性,這樣卷積的結果如上圖所示成了一個1維的向量結果,然後我們進行一個max_pool操作,其他大小與卷積後生成的向量一樣,最後我們得到了一個個1*1大小的向量。我們利用concat方法將這些向量合併,最後接入一個全連線層,然後softmax之後我們就可以得到分類的結果。整體流程在程式碼中有些,而且所有的tensor大小也註明了。
這裡我需要說的是,一開始我使用的與NN一樣的tweet向量化的方法,即將tweet對映到一個字典長度的維度上,但實驗之後發現效果並不好,於是我再檢視資料是發現了另一種文字向量化的方法,就是規定每條tweet長度固定均為100,這是在統計後得出的一個基本結果(我統計過訓練集中tweet的長度一般在100以下,而且之後我還進行了資料的一個預處理,就是刪除標點符號與數字),這樣我們就可以將tweet對映到一個100維的向量上,這樣矩陣就比較稠密點,而且訓練的batch_size可以調的比較大,我們通常採用“多了截斷/少了補充”的策略。
1.2就是最後的訓練
在訓練階段,我順便學習了tensorboard以及模型儲存的方法,程式碼如下,基本上是一種常見的訓練格式:
def train_neural_netword():
# 配置tensorboard
tensorboard_dir = "tensorboard/cnn"
if not os.path.exists(tensorboard_dir):
os.makedirs(tensorboard_dir)
output = neural_network()
# 構建準確率的計算過程
predictions = tf.argmax(output, 1)
correct_predictions = tf.equal(predictions, tf.argmax(Y, 1))
accuracy = tf.reduce_mean(tf.cast(correct_predictions, "float")) # 強制轉換
tf.summary.scalar("accuracy", accuracy)
# 構建損失函式的計算過程
optimizer = tf.train.AdamOptimizer(0.001)
loss = tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits(logits=output, labels=Y))
tf.summary.scalar("loss", loss) # 將損失函式加入
grads_and_vars = optimizer.compute_gradients(loss)
train_op = optimizer.apply_gradients(grads_and_vars)
# 將引數儲存如tensorboard中
merged_summary = tf.summary.merge_all()
writer = tf.summary.FileWriter(tensorboard_dir)
# 構建模型的儲存模型
saver = tf.train.Saver(tf.global_variables())
# 資料集的獲取
df = pd.read_csv(os.path.join('data', 'new_train_data.csv'))
group_by_emotion0 = df.groupby('emotion0')
group_neg = group_by_emotion0.get_group(0).values
group_pos = group_by_emotion0.get_group(1).values
test_x, test_y = get_test_data('new_test_data.csv')
with tf.Session() as sess:
sess.run(tf.initialize_all_variables())
# sess.run(tf.global_variables_initializer())
# 將影象加入tensorboard中
writer.add_graph(sess.graph)
lemmatizer = WordNetLemmatizer()
i = 0
pre_acc = 0
while i < 10000:
rand_neg_data = get_random_n_lines(i, group_neg, batch_size)
rand_pos_data = get_random_n_lines(i, group_pos, batch_size)
rand_data = np.vstack((rand_neg_data, rand_pos_data))
np.random.shuffle(rand_data)
batch_x = rand_data[:, 3]
batch_y = rand_data[:, 0: 3]
new_batch_x = []
for tweet in batch_x:
# 這段迴圈的意義就是將單詞提取詞幹,並將字元轉換成下標
words = word_tokenize(tweet.lower())
words = [lemmatizer.lemmatize(word) for word in words]
features = np.zeros(len(lex))
for word in words:
if word in lex:
features[lex.index(word)] = 1 # 一個句子中某個詞可能出現兩次,可以用+=1,其實區別不大
new_batch_x.append(features)
_, loss_ = sess.run([train_op, loss], feed_dict={X: new_batch_x, Y: batch_y, dropout_keep_prob: 0.5})
if i % 20 == 0:
# 每二十次儲存一次tensorboard
s = sess.run(merged_summary, feed_dict={X: new_batch_x, Y: batch_y, dropout_keep_prob: 0.5})
writer.add_summary(s, i)
if i % 10 == 0:
# 每10次打印出一個損失函式與準確率(這是指評測的準確率)
print(loss_)
accur = sess.run(accuracy, feed_dict={X: test_x, Y: test_y, dropout_keep_prob: 1.0})
if accur > pre_acc:
# 當前的準確率高於之前的準確率,更新模型
pre_acc = accur
print("準確率:", pre_acc)
tf.summary.scalar("accur", accur)
saver.save(sess, "cnn_model/model.ckpt")
i += 12.3執行結果
在tensorboard上視覺化的結果如下:
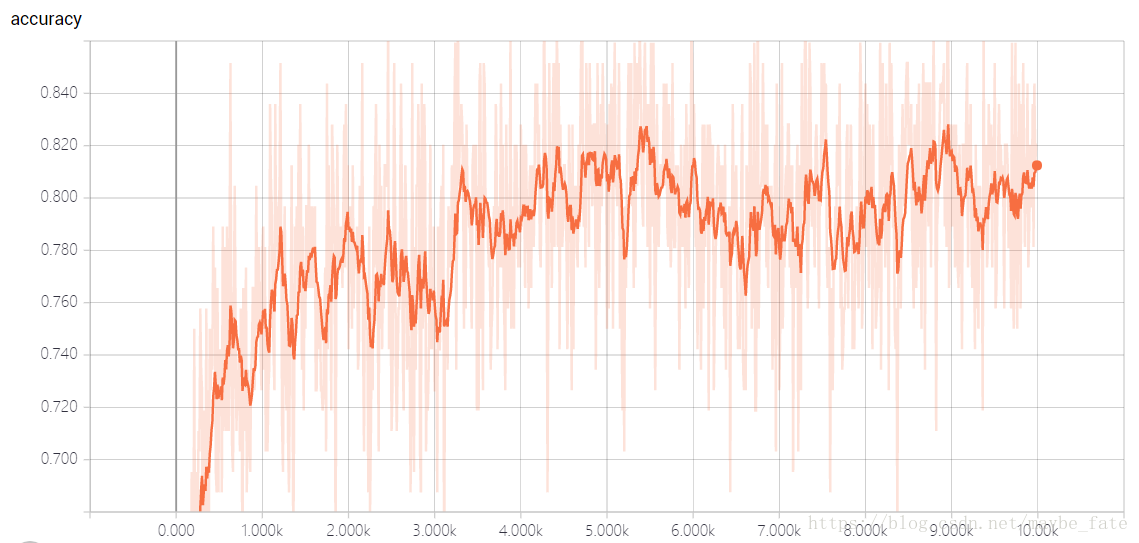
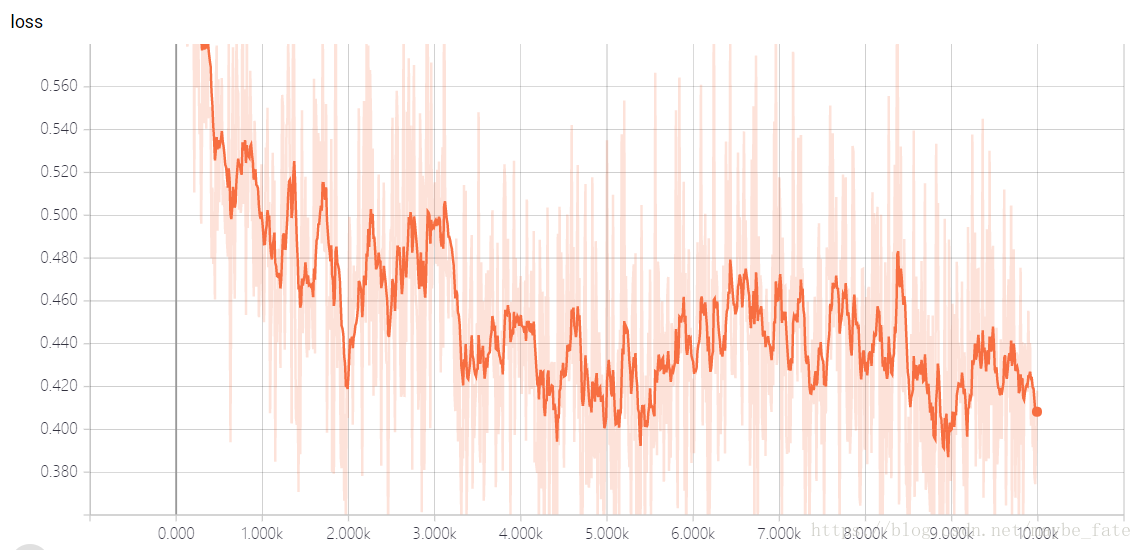
說實話最後的訓練效果並不好,我也不清楚是為什麼,希望知道的同學告訴我一聲吧。
3.後記
感謝CSDN使用者“MachineLP”,我的整個流程是在他的基礎上進行修改。實在是受益匪淺。
以上的程式碼會貼到我的github上(點選開啟連結)