
faster rcnn中損失函式(二)—— Smoooh L1 Loss的講解
1. 使用Smoooh L1 Loss的原因
對於邊框的預測是一個迴歸問題。通常可以選擇平方損失函式(L2損失)f(x)=x^2。但這個損失對於比較大的誤差的懲罰很高。
我們可以採用稍微緩和一點絕對損失函式(L1損失)f(x)=|x|,它是隨著誤差線性增長,而不是平方增長。但這個函式在0點處導數不存在,因此可能會影響收斂。
一個通常的解決辦法是,分段函式,在0點附近使用平方函式使得它更加平滑。它被稱之為平滑L1損失函式。它通過一個引數sigma來控制平滑的區域:比如sigma=3 下面的 if |x|<1/3**2的時候,更接近於0的地方。
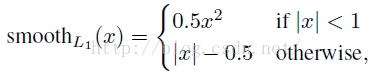

2.
SmoothL1LossLayer 計算一張圖片的損失函式,對應於下圖的加號右邊部分
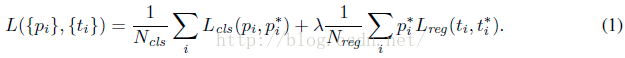
i是mini-batch的anchor的索引。

有物體時pi*為1,否則為0
所以上圖中,迴歸損失中,Pi*Leg(ti, ti*)表明只有fg才有迴歸損失。

ti是一個向量,預測座標 = (tx,ty,tw,th)
ti*是一個向量,是gt包圍盒的座標
![]()
R表示的下一個圖那樣的分段函式。
bottom[0]預測座標,對應於下圖的ti,即rpn_bbox_pred層返回的預測的與初始anchor的偏移。
bottom[1]target座標,對應於下圖的ti*,即anchor_target_layer型別的rpn_data層返回的,rpn_bbox_target,gt與初始每個anchor的偏移。
bottom[2]inside,有物體(fg)時為1,否則為0,對應於上圖的pi*
bottom[3]outside,沒有前景(fg)也沒有後景(bg)的為0,其他為1/(bg+fg)=Ncls,對應於加號右邊的係數部分(但其實這個地方我本人還是不懂,因為論文上說的係數都是一些固定的值,如入=10。初始程式碼一直在更新,估計又換了別的方法。不論如何,在現在的程式碼中outside是乘以了後面的結果)
Lreg的公式就是下圖,另 x=ti - ti*,
其中|x|<1 /sigma*sigma : (x*x)/(sigma*sigma/2)
other: |x|-0.5/(sigma**2)
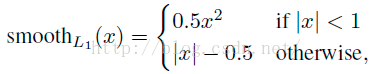
我們可以從下面程式碼中學習到分段函式,如何用矩陣來進行運算,以及loss如何相加(軸):
摘自:pytorch的net_utils.py中
def _smooth_l1_loss(bbox_pred, bbox_targets, bbox_inside_weights, bbox_outside_weights, sigma=1.0, dim=[1]):
sigma_2 = sigma ** 2
box_diff = bbox_pred - bbox_targets### B,9*4,H,W B,9*4,H,W都是variable
in_box_diff = bbox_inside_weights * box_diff# 內部正樣本的diff
abs_in_box_diff = torch.abs(in_box_diff)
#detach返回的Variable和原始的Variable公用同一個data tensor。
#返回一個新的Variable,從當前圖中分離下來的。requires_grad=False,
smoothL1_sign = (abs_in_box_diff < 1. / sigma_2).detach().float()
in_loss_box = torch.pow(in_box_diff, 2) * (sigma_2 / 2.) * smoothL1_sign \
+ (abs_in_box_diff - (0.5 / sigma_2)) * (1. - smoothL1_sign)
out_loss_box = bbox_outside_weights * in_loss_box#bbox_outside_weights 正負樣本都是1/256 背景為0
#注意學習loss的相加,按照軸
loss_box = out_loss_box
for i in sorted(dim, reverse=True):
loss_box = loss_box.sum(i)
loss_box = loss_box.mean()
return loss_boxdetach能用來幹啥
如果我們有兩個網路 A,B
, 兩個關係是這樣的 y=A(x),z=B(y) 現在我們想用 z.backward() 來為 B 網路的引數來求梯度,但是又不想求 A
網路引數的梯度。我們可以這樣:
# y=A(x), z=B(y) 求B中引數的梯度,不求A中引數的梯度
# 第一種方法
y = A(x)
z = B(y.detach())
z.backward()
# 第二種方法
y = A(x)
y.detach_()
z = B(y)
z.backward()在這種情況下,detach 和 detach_ 都可以用。但是如果 你也想用 y
來對 A 進行 BP 呢?那就只能用第一種方法了。因為 第二種方法 已經將 A 模型的輸出 給 detach(分離)了。