
faster rcnn中 損失函式(一)——softmax,softmax loss和cross entropy的講解
先理清下從全連線層到損失層之間的計算。來看下面這張圖,(非常好的圖)。
T類 N表示前一層特徵層flatten後的數字 fltten後的特徵 無限大小的T類 從0-1的T類向量

這張圖的等號左邊部分就是全連線層做的事,W是全連線層的引數,我們也稱為權值,X是全連線層的輸入,也就是特徵。從圖上可以看出特徵X是N*1的向量,這是怎麼得到的呢?【答:flat成N*1的向量】這個特徵就是由全連線層前面多個卷積層和池化層處理後得到的,假設全連線層前面連線的是一個卷積層,這個卷積層的輸出是100個特徵(也就是我們常說的feature map的channel為100),每個特徵的大小是4*4,那麼在將這些特徵輸入給全連線層之前會將這些特徵flat成N*1的向量
解釋完X,再來看W,W是全連線層的引數,是個T*N的矩陣,這個N和X的N對應,T表示類別數,比如你是7分類,那麼T就是7。我們所說的訓練一個網路,對於全連線層而言就是尋找最合適的W矩陣。因此全連線層就是執行WX得到一個T*1的向量(也就是圖中的logits[T*1]),這個向量裡面的每個數都沒有大小限制的,也就是從負無窮大到正無窮大。然後如果你是多分類問題,一般會在全連線層後面接一個softmax層,這個softmax的輸入是T*1的向量,輸出也是T*1的向量(也就是圖中的prob[T*1],這個向量的每個值表示這個樣本屬於每個類的概率),只不過輸出的向量的每個值的大小範圍為0到1。
現在你知道softmax的輸出向量是什麼意思了,就是概率,該樣本屬於各個類的概率!
那麼softmax執行了什麼操作可以得到0到1的概率呢?先來看看softmax的公式(以前自己看這些內容時候對公式也很反感,不過靜下心來看就好了):
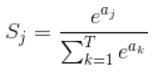
Sj是softmax的輸出向量S的第j個值
公式非常簡單,前面說過softmax的輸入是WX,假設模型的輸入樣本是I,討論一個3分類問題(類別用1,2,3表示),樣本I的真實類別是2,那麼這個樣本I經過網路所有層到達softmax層之前就得到了WX,也就是說WX是一個3*1的向量,那麼上面公式中的aj就表示這個3*1的向量中的第j個值(最後會得到S1,S2,S3
因此我們訓練全連線層的W的目標就是使得其輸出的WX在經過softmax層計算後其對應於真實標籤的預測概率要最高。
舉個例子:假設你的WX=[1,2,3],那麼經過softmax層後就會得到[0.09,0.24,0.67],這三個數字表示這個樣本屬於第1,2,3類的概率分別是0.09,0.24,0.67。
#_RPN Module中間內部的就加 _
class _RPN(nn.Module):
""" region proposal network """
def __init__(self, din):
super(_RPN, self).__init__()
self.din = din # get depth of input feature map, e.g., 512 /zf256 vgg 512
self.anchor_scales = cfg.ANCHOR_SCALES#[8 16 32]
self.anchor_ratios = cfg.ANCHOR_RATIOS#[0.5 1 2]
self.feat_stride = cfg.FEAT_STRIDE[0]#16
# define the conv+relu layers processing input feature map
self.RPN_Conv = nn.Conv2d(self.din, 512, 3, 1, 1, bias=True)#input_c,output_c,kenal,stride,padding
#relu不需要自定義,直接放到foward裡面
# define bg/fg classifcation score layer
self.nc_score_out = len(self.anchor_scales) * len(self.anchor_ratios) * 2 # 2(bg/fg) * 9 (anchors)
self.RPN_cls_score = nn.Conv2d(512, self.nc_score_out, 1, 1, 0)
# define anchor box offset prediction layer
self.nc_bbox_out = len(self.anchor_scales) * len(self.anchor_ratios) * 4 # 4(coords) * 9 (anchors)
self.RPN_bbox_pred = nn.Conv2d(512, self.nc_bbox_out, 1, 1, 0)
# define proposal layer
self.RPN_proposal = _ProposalLayer(self.feat_stride, self.anchor_scales, self.anchor_ratios)
# define anchor target layer #初始化自定義_AnchorTargetLayer裡面的__init__
self.RPN_anchor_target = _AnchorTargetLayer(self.feat_stride, self.anchor_scales, self.anchor_ratios)
self.rpn_loss_cls = 0
self.rpn_loss_box = 0
@staticmethod
def reshape(x, d):
#d表示第二個維度
input_shape = x.size()#
x = x.view(
input_shape[0],#輸入的維度 n c h w
int(d),
int(float(input_shape[1] * input_shape[2]) / float(d)),
input_shape[3]
)
return x
def forward(self, base_feat, im_info, gt_boxes, num_boxes):
# base_feat的來源
#faster_rcnn中 feed image data to base model to obtain base feature map
# base_feat = self.RCNN_base(im_data)
#RCNN_base在vgg16的_init_modules中
# not using the last maxpool layer
# self.RCNN_base = nn.Sequential(*list(vgg.features._modules.values())[:-1])
batch_size = base_feat.size(0)
# return feature map after convrelu layer
rpn_conv1 = F.relu(self.RPN_Conv(base_feat), inplace=True)
# get rpn classification score
rpn_cls_score = self.RPN_cls_score(rpn_conv1)
rpn_cls_score_reshape = self.reshape(rpn_cls_score, 2)#n 2 9*h w
rpn_cls_prob_reshape = F.softmax(rpn_cls_score_reshape)———————————–華麗的分割線——————————————
弄懂了softmax,就要來說說softmax loss了。
那softmax loss是什麼意思呢?如下:
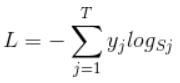
L是損失。
y是標籤向量如y=[0,0,0,1,0]
Sj是softmax的輸出向量S的第j個值,前面已經介紹過了,表示的是預測的這個樣本屬於第j個類別的概率。
yj前面有個求和符號,j的範圍也是1到類別數T,因此y是一個1*T的向量,裡面的T個值,而且只有1個值是1,其他T-1個值都是0。那麼哪個位置的值是1呢?答案是真實標籤對應的位置的那個值是1,其他都是0。所以這個公式其實有一個更簡單的形式:
![]()
當然此時要限定j是指向當前樣本的真實標籤。
來舉個例子吧。假設一個5分類問題,然後一個樣本I的標籤y=[0,0,0,1,0],也就是說樣本I的真實標籤是4,假設模型預測的結果概率(softmax的輸出)p=[0.1,0.15,0.05,0.6,0.1],可以看出這個預測是對的,那麼對應的損失L=-log(0.6),也就是當這個樣本經過這樣的網路引數產生這樣的預測p時,它的損失是-log(0.6)。那麼假設p=[0.15,0.2,0.4,0.1,0.15],這個預測結果就很離譜了,因為真實標籤是4,而你覺得這個樣本是4的概率只有0.1(遠不如其他概率高,如果是在測試階段,那麼模型就會預測該樣本屬於類別3),對應損失L=-log(0.1)。那麼假設p=[0.05,0.15,0.4,0.3,0.1],這個預測結果雖然也錯了,但是沒有前面那個那麼離譜,對應的損失L=-log(0.3)。我們知道log函式在輸入小於1的時候是個負數,而且log函式是遞增函式,所以-log(0.6) < -log(0.3) < -log(0.1)。簡單講就是你預測錯比預測對的損失要大,預測錯得離譜比預測錯得輕微的損失要大。
以rpn中的SoftmaxLoss為例,輸入:(1,2,9*h,w)和標籤(1,1,9*h,w),每一個子loss,就是把(1,2,9*h,w)中的2分類概率和(1,1,9*h,w)對比,找出屬於哪一個,再用![]() 求。
求。
———————————–華麗的分割線———————————–
理清了softmax loss,就可以來看看cross entropy了。
corss entropy是交叉熵的意思,它的公式如下:
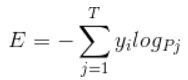
是不是覺得和softmax loss的公式很像。當cross entropy的輸入P是softmax的輸出時,cross entropy等於softmax loss。
Pj是輸入的概率向量P的第j個值,所以如果你的概率是通過softmax公式得到的,那麼cross entropy就是softmax loss。這是我自己的理解,如果有誤請糾正。
#cross_entropy要求輸入是Variable預測的是2D,label是1D
self.rpn_loss_cls = F.cross_entropy(rpn_cls_score, rpn_label)# (b*9*h*w,2) (b*9*h*w,)
相關推薦
faster rcnn中 損失函式(一)——softmax,softmax loss和cross entropy的講解
先理清下從全連線層到損失層之間的計算。來看下面這張圖,(非常好的圖)。 T類 N表示前一層特徵層flatten後的數字 fltten後的特徵 無限大小的T類 從0-1的T類向量
faster rcnn中損失函式(二)—— Smoooh L1 Loss的講解
1. 使用Smoooh L1 Loss的原因 對於邊框的預測是一個迴歸問題。通常可以選擇平方損失函式(L2損失)f(x)=x^2。但這個損失對於比較大的誤差的懲罰很高。 我們可以採用稍微緩和一點絕對損失函式(L1損失)f(x)=|x|,它是隨著誤差線性增長,而不是平方增長
EmguCV Image類中的函式(一)
轉載自http://blog.csdn.net/qq_22033759/article/details/47807553 1、Image<TColor, TDepth> AbsDiff 返回兩幅圖片或此圖與某個yanse畫素的差的絕對值的圖片 2
python中的函式(一)
接觸過C語言的朋友對函式這個詞肯定非常熟悉,無論在哪門程式語言當中,函式(當然在某些語言裡稱作方法,意義是相同的)都扮演著至關重要的角色。今天就來了解一下Python中的函式用法。 一.函式的定義 在某些程式語言當中,函式宣告和函式定義是區分開的(在這些程式語言當中函式宣
Windows +TensorFlow+Faster Rcnn 詳細安裝步驟(一)
Windows下Python版本TensorFlow需要Python 3.5支援,因此建議使用Anaconda,避免和原本電腦Python版本衝突等問題。(另外,你完全可以按照這個流程來,但如果你想偷懶,Windows +TensorFlow+Faster Rcnn整個安裝
JVM(一)——GC,記憶體分配和垃圾回收
心得:Java中垃圾回收和記憶體可以實現高度的自動化,棧幀可以由JVM自動分配和回收,區域性變量表和運算元棧也可以在編譯時就確定好,堆中的記憶體分配和回收才是JVM關注的重點,JVM實現大多采用可達性分析來標記存活物件,什麼時候標記?讓使用者執行緒主動跑到那些安
tensorflow+faster rcnn程式碼理解(一):構建vgg前端和RPN網路
0.前言 該程式碼執行首先就是呼叫vgg類建立一個網路物件self.net if cfg.FLAGS.network == 'vgg16': self.net = vgg16(batch_size=cfg.FLAGS.ims_per_batch) 該類位於vgg.py中,如下:
OPENCV----在APP性能測試中的應用(一)
核心 color frame pan ems span urn sqrt || 應用項目: APP的性能測試 應用場景: APP啟動速度 視頻開播速度 加載速度 等~~ 緣來: 基於APP日誌和UiAutomator的測試方案,測試結果不能直白且精確的
Faster rcnn代碼理解(1)
感覺 組織 等我 ont 包含 還要 定義 fig 訓練數據 這段時間看了不少論文,回頭看看,感覺還是有必要將Faster rcnn的源碼理解一下,畢竟後來很多方法都和它有相近之處,同時理解該框架也有助於以後自己修改和編寫自己的框架。好的開始吧~ 這裏我們跟著Faster
C++中的常量(一) const限定符
無法 簡單的 對象 可能 函數重載 struct 理解 變量 必須 最近在重新看<<C++ Primer>>,第一遍的時候const和constexpr看得並不太懂,這次又有了些更新的理解,當然可能仍然有許多不對的地方... 首先,const限定符即
Java語言中的----繼承(一)
java語言中的----繼承(一)day10 Java語言中的繼承(一)一、繼承概述: 繼承:什麽是繼承,程序中的繼承與生活中的繼承還是有區別的,在程序中繼承以後,你的父類和你的子類同樣的也具有某一成員變量。那麽我們為什麽藥學習繼承?是因為我們在編程的時候我們會有大量的代碼需要重寫,從而導致我們代碼比較
java中的異常(一)
數組 col logs exception 並且 test 但是 blog ring java異常的概念 執行期的錯誤(javac xxx.java) 運行期的錯誤(java xxx) 這裏講的是運行期出現的錯誤 class TestEx { public s
持有對象——Java中的容器(一)
接口 中移動 tex 結構 collect 成對 .get void 概念 泛型和類型安全的容器 使用Java SE5之前,編譯器允許向容器中插入不正確的類型,Java SE5引入泛型之後,應用預定義的泛型可以在編譯期防止將錯誤類型的對象放到容器中。 基本概念 Col
MVVM模式解析和在WPF中的實現(一)
開發 特點 還需 如果 情況下 依次 顯示 尋找 這也 MVVM模式簡介 MVVM是Model、View、ViewModel的簡寫,這種模式的引入就是使用ViewModel來降低View和Model的耦合,說是降低View和Model的耦合。也可以說是是降低界面和邏輯的耦合
MySQL數據庫中的索引(一)——索引實現原理
物理地址 關鍵字 必須 增加 pic 搜索索引 而是 哈希索引 掃描 今天我們來探討一下數據庫中一個很重要的概念:索引。 MySQL官方對索引的定義為:索引(Index)是幫助MySQL高效獲取數據的數據結構,即索引是一種數據結構。 我們知道,數據庫查詢是數據庫的最主要功能
Spring中的IOC(一)
style info ide bean BE @override color div warn 1. 什麽是IOC的功能? * IoC -- Inverse of Control,控制反轉,將對象的創建權反轉給Spring!! * 使用IOC可以
WPF中的動畫——(一)基本概念
問題 code AD soft msdn 動畫 易維 sof lean 原文:WPF中的動畫——(一)基本概念WPF的一個特點就是支持動畫,我們可以非常容易的實現漂亮大方的界面。首先,我們來復習一下動畫的基本概念。計算機中的動畫一般是定格動畫,也稱之為逐幀動畫,它通過每幀不
貝葉斯在機器學習中的應用(一)
需要 基礎 under 情況下 學生 意義 span 公式 ext 貝葉斯在機器學習中的應用(一) 一:前提知識 具備大學概率論基礎知識 熟知概率論相關公式,並知曉其本質含義/或實質意義
Web API中的路由(一)——基本路由
名稱 nts delete nal dict quest 添加 let web api 一.Web API中的路由概念 路由的作用用一句話說明:通過request的uri找到處理該請求的Controller,Action,以及給Action的參數賦值。 web api
從二維數組中查找(一)
說明 div row num fun true ret 結束 排序 在一個二維數組中(每個一維數組的長度相同),每一行都按照從左到右遞增的順序排序,每一列都按照從上到下遞增的順序排序。請完成一個函數,輸入這樣的一個二維數組和一個整數,判斷數組中是否含有該整數。 fun