
基於深度學習的視訊檢測(四) yolo-v2和darkflow
yolo-v1
核心思想:從R-CNN到Fast R-CNN一直採用的思路是proposal+分類 (proposal 提供位置資訊, 分類提供類別資訊)精度已經很高,但是速度還不行。 YOLO提供了另一種更為直接的思路: 直接在輸出層迴歸bounding box的位置和bounding box所屬的類別(整張圖作為網路的輸入,把 Object Detection 的問題轉化成一個 Regression 問題)。
主要特點
1. 速度快,能夠達到實時的要求。在 Titan X 的 GPU 上 能夠達到 45 幀每秒。 2. 使用全圖作為 Context 資訊,背景錯誤(把背景錯認為物體)比較少。 3. 泛化能力強。
大致流程

1. Resize成448*448,圖片分割得到7*7網格(cell),一個cell設定兩個bounding box
2. CNN提取特徵和預測:卷積部分負責提特徵。全連線部分負責預測:
a) 7*7*2=98個bounding box(bbox) 的座標x_{center},y_{center},w,h 和是否有物體的confidence 。
b) 7*7=49個cell所屬20個物體的概率。
3. 過濾bbox(通過NMS( NON-MAXIMUM SUPPRESSION))

網路設計


網路結構借鑑了 GoogLeNet
缺陷
1. YOLO對相互靠的很近的物體(挨在一起且中點都落在同一個格子上的情況),還有很小的群體檢測效果不好,這是因為一個網格中只預測了兩個框,並且只屬於一類。
2. 測試影象中,當同一類物體出現的不常見的長寬比和其他情況時泛化能力偏弱。
3. 由於損失函式的問題,定位誤差是影響檢測效果的主要原因,尤其是對小物體的處理上,還有待加強。
yolo-v2
精度的改進(Better)
Batch Normalization
CNN 在訓練過程中網路每層輸入的分佈一直在改變, 會使訓練過程難度加大,但可以通過normalize每層的輸入解決這個問題。**新的YOLO網路在每一個卷積層後新增batch normalization**,通過這一方法,mAP獲得了2%的提升。batch normalization 也有助於規範化模型,可以在捨棄dropout優化後依然不會過擬合。
High Resolution Classifier
目前的目標檢測方法中,基本上都會使用ImageNet預訓練過的模型(classifier)來提取特徵,如果用的是AlexNet網路,那麼輸入圖片會被resize到不足256 * 256,導致解析度不夠高,給檢測帶來困難。為此,新的YOLO網路把解析度直接提升到了448 * 448,這也意味之原有的網路模型必須進行某種調整以適應新的解析度輸入。
對於YOLOv2,作者首先對分類網路(自定義的darknet)進行了fine tune,解析度改成448 * 448,在ImageNet資料集上訓練10輪(10 epochs),訓練後的網路就可以適應高解析度的輸入了。然後,作者對檢測網路部分(也就是後半部分)也進行fine tune。
之前的 YOLO v1以解析度224*224訓練分類網路,YOLO v2 將分類網路的解析度提高到 448*448,高解析度樣本對於效果有一定的提升(文中mAp提高了約4%)。
Convolutional With Anchor Boxes
之前的YOLO利用全連線層的資料完成邊框的預測,導致丟失較多的空間資訊,定位不準。作者在這一版本中借鑑了Faster R-CNN中的anchor思想,回顧一下,anchor是RNP網路中的一個關鍵步驟,說的是在卷積特徵圖上進行滑窗操作,每一箇中心可以預測9種不同大小的建議框。看到YOLOv2的這一借鑑,我只能說SSD的作者是有先見之明的。
YOLO v1: S*S* (B*5 + C) => 7*7(2*5+20)
其中B對應Box數量,5對應 Rect 定位+置信度。 每個Grid只能預測對應兩個Box,這兩個Box共用一個分類結果(20 classes),這是很不合理的臨時方案,看來作者為第二篇論文預留了改進,沒想被 SSD 搶了風頭。
YOLO v2: S*S*K* (5 + C) => 13*13*9(5+20)
解析度改成了13*13,更細的格子劃分對小目標適應更好,再加上與Faster一樣的K=9,計算量增加了不少。通過Anchor Box改進,mAP由69.5下降到69.2,Recall由81%提升到了88%。
SSD(-): S*S*K*(4 + C) => 7*7*6*( 4+21 )
對應C=21,代表20種分類類別和一種 背景類。
Dimension Clusters
還是針對Anchors,Faster的Anchor對應 K=9,那麼為什麼等於9呢?寬高比為什麼定位成這樣(1:1,1:2,2:1)?對於SSD選擇了K=6,那麼K到底等於幾合適?寬高比又該怎麼設計? 作者給出瞭解決方案,這個解決方案就是聚類。
作者在 VOC 和 COCO 上通過 Ground Truth 進行聚類統計(採用K-means演算法)
Direct location prediction
作者通過使用 維度聚類 和 直接位置預測 這兩項Anchor Boxes改進方法,將 mAP 提高了5%.
Fine-Grained Features
SSD通過不同Scale的Feature Map來預測Box來實現多尺度,而YOLO v2則採用了另一種思路:新增一個passthrough layer,來獲取上一層26x26的特徵,並將該特徵同最後輸出特徵(13*13)相結合,以此來提高對小目標的檢測能力。
通過Passthrough 把26 * 26 * 512的特徵圖疊加成13 * 13 * 2048的特徵圖,與原生的深層特徵圖相連線。
YOLO v2 使用擴充套件後的的特徵圖(add passthrough),將mAP提高了了1%。
PS:這裡實際上是有個Trick,網路最後一層是13*13,相對原來7*7的網路來講,細粒度的處理目標已經double了,再加上上一層26*26的Feature共同決策,這兩層的貢獻等價於SSD的4層以上,但計算量其實並沒有增加多少。
Multi-Scale Training
為了讓 YOLOv2 適應不同Scale下的檢測任務,作者嘗試 通過不同解析度圖片的訓練來提高網路的適應性。
PS:網路只用到了卷積層和池化層,可以進行動態調整(檢測任意大小圖片)
具體做法是:
每經過10批訓練(10 batches)就會隨機選擇新的圖片尺寸,尺度定義為32的倍數,( 320,352,…,608 ),為了最後一層得到特徵圖尺度為13*13(416=13*32),YOLO v2 輸入圖片尺寸為416 * 416,降取樣引數為32。
特點
YOLO v2 在大尺寸圖片上能夠實現高精度,在小尺寸圖片上執行更快,可以說在速度和精度上達到了平衡。
darknet和darkflow
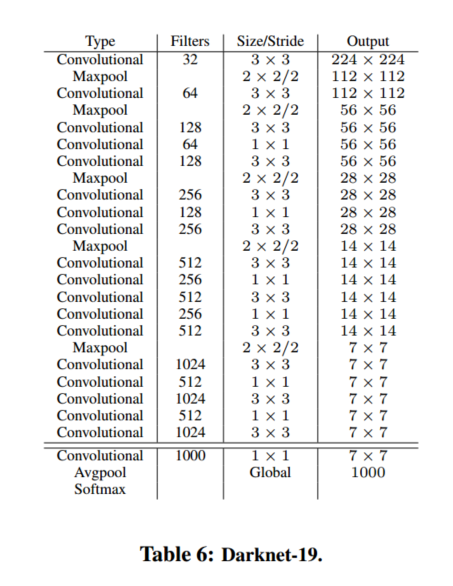
YOLOv2使用了一個新的分類網路作為特徵提取部分,參考了前人的先進經驗,比如類似於VGG,作者使用了較多的3 * 3卷積核,在每一次池化操作後把通道數翻倍。借鑑了network in network的思想,網路使用了全域性平均池化(global average pooling),把1 * 1的卷積核置於3 * 3的卷積核之間,用來壓縮特徵。也用了batch normalization(前面介紹過)穩定模型訓練。
最終得出的基礎模型就是Darknet-19,如下圖,其包含19個卷積層、5個最大值池化層(maxpooling layers ),下圖展示網路具體結構。Darknet-19運算次數為55.8億次,imagenet圖片分類top-1準確率72.9%,top-5準確率91.2%。
darkflow
darkflow實現了將darknet移植到tensorflow上,可以用tensorflow載入darknet訓練好的模型,並使用tensorflow重新訓練,輸出tensorflow graph模型,用於移動裝置。