
深度學習-----資料預處理是必要的,一些經驗化的預處理措施
資料歸一化
更多詳細資訊,參照網址:非常值得一看:
http://blog.csdn.net/qq_26898461/article/details/50463052
http://blog.csdn.net/bea_tree/article/details/51519844
資料預處理中,標準的第一步是資料歸一化。雖然這裡有一系列可行的方法,但是這一步通常是根據資料的具體情況而明確選擇的。特徵歸一化常用的方法包含如下幾種:
- 簡單縮放
- 逐樣本均值消減(也稱為移除直流分量)
- 特徵標準化(使資料集中所有特徵都具有零均值和單位方差)
簡單縮放
在簡單縮放中,我們的目的是通過對資料的每一個維度的值進行重新調節(這些維度可能是相互獨立的),使得最終的資料向量落在
Eg:在處理自然影象時,我們獲得的畫素值在 [0,255] 區間中,常用的處理是將這些畫素值除以 255,使它們縮放到 [0,1] 中.
逐樣本均值消減
如果你的資料是平穩的(即資料每一個維度的統計都服從相同分佈),那麼你可以考慮在每個樣本上減去資料的統計平均值(逐樣本計算)。
Eg:對於影象,這種歸一化可以移除影象的平均亮度值 (intensity)。很多情況下我們對影象的照度並不感興趣,而更多地關注其內容,這時對每個資料點移除畫素的均值是有意義的。注意:
特徵標準化
特徵標準化指的是(獨立地)使得資料的每一個維度具有零均值和單位方差。這是歸一化中最常見的方法並被廣泛地使用(例如,在使用支援向量機(SVM)時,特徵標準化常被建議用作預處理的一部分)。在實際應用中,特徵標準化的具體做法是:首先計算每一個維度上資料的均值(使用全體資料計算),之後在每一個維度上都減去該均值。下一步便是在資料的每一維度上除以該維度上資料的標準差。
Eg:處理音訊資料時,常用 Mel 倒頻係數 MFCCs 來表徵資料。然而MFCC特徵的第一個分量(表示直流分量)數值太大,常常會掩蓋其他分量。這種情況下,為了平衡各個分量的影響,通常對特徵的每個分量獨立地使用標準化處理。
PCA/ZCA白化
在做完簡單的歸一化後,白化通常會被用來作為接下來的預處理步驟,它會使我們的演算法工作得更好。實際上許多深度學習演算法都依賴於白化來獲得好的特徵。
在進行 PCA/ZCA 白化時,首先使特徵零均值化是很有必要的,這保證了 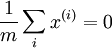 。特別地,這一步需要在計算協方差矩陣前完成。(唯一例外的情況是已經進行了逐樣本均值消減,並且資料在各維度上或畫素上是平穩的。)
。特別地,這一步需要在計算協方差矩陣前完成。(唯一例外的情況是已經進行了逐樣本均值消減,並且資料在各維度上或畫素上是平穩的。)
接下來在 PCA/ZCA 白化中我們需要選擇合適的 epsilon(回憶一下,這是規則化項,對資料有低通濾波作用)。 選取合適的 epsilon 值對特徵學習起著很大作用
標準流程
在這一部分中,我們將介紹幾種在一些資料集上有良好表現的預處理標準流程.
自然灰度影象
灰度影象具有平穩特性,我們通常在第一步對每個資料樣本分別做均值消減(即減去直流分量),然後採用 PCA/ZCA 白化處理,其中的 epsilon 要足夠大以達到低通濾波的效果。
彩色影象
對於彩色影象,色彩通道間並不存在平穩特性。因此我們通常首先對資料進行特徵縮放(使畫素值位於 [0,1] 區間),然後使用足夠大的 epsilon 來做 PCA/ZCA。注意在進行 PCA 變換前需要對特徵進行分量均值歸零化。
音訊 (MFCC/頻譜圖)
對於音訊資料 (MFCC 和頻譜圖),每一維度的取值範圍(方差)不同。例如 MFCC 的第一分量是直流分量,通常其幅度遠大於其他分量,尤其當特徵中包含時域導數 (temporal derivatives) 時(這是音訊處理中的常用方法)更是如此。因此,對這類資料的預處理通常從簡單的資料標準化開始(即使得資料的每一維度均值為零、方差為 1),然後進行 PCA/ZCA 白化(使用合適的 epsilon)。
MNIST 手寫數字
MNIST 資料集的畫素值在 [0,255] 區間中。我們首先將其縮放到 [0,1] 區間。實際上,進行逐樣本均值消去也有助於特徵學習。注:也可選擇以對 MNIST 進行 PCA/ZCA 白化,但這在實踐中不常用。