
京東JData演算法大賽小結(公司內部賽)
總體解決方案
本文將高潛使用者購買意向預測,抽象為一個二分類問題。從使用者,商品,品牌,使用者-商品,使用者-品牌五個維度進行特徵提取。將觀察天未來5天有購買行為的使用者-商品對標記為正樣本,觀察天過去30天至未來5天有互動行為但未購買的使用者-商品對標記為負樣本。由於正負樣本比例極不平衡,採用了對正樣本進行重取樣及負樣本進行下采樣的方式來平衡正負樣本比例。利用xgboost進行模型訓練,最後利用LR對預測結果進行加權。取每個使用者最高預測概率對應的user-sku對,取top12000作為最終輸出結果。
實現方案技術棧
集市堡壘機(環境) + Hive(ETL) + Spark& Spark-Xgboost(Model)
特徵工程
從使用者、商品、品牌、使用者-商品互動、使用者-品牌互動5個維度,再對各個維度從不同週期(1/3/5/7/10/15/30天)進行建模及特徵提取。
3-1 使用者維度(script/dim_feature_v3/dim_user_feature_etl.sql):使用者等級,性別,註冊天數,年齡等級,瀏覽量,點選量,關注量,加購車量,下單量,取消關注量,點選購買率,點選加購率,點選關注率,瀏覽購買轉化率,加購購買轉化率,關注購買轉化率,瀏覽day/sku/brand數,點選day/sku/brand數,關注day/sku/brand數,加購車day/sku/brand數,下單day/sku/brand數,取消關注day/sku/brand數,最近瀏覽/點選/購買/關注距今天數,平均每天瀏覽/點選/購買/關注量(sku/brand數),平均瀏覽/點選/購買/關注行為操作間隔天數
3-2 商品維度(script/dim_feature_v3/dim_sku_feature_etl.sql):商品評論數,好評率,差評率,商品屬性1,屬性2,屬性3,瀏覽量,點選量,關注量,加購車量,下單量,取消關注量,點選購買率,點選加購率,點選關注率,瀏覽購買轉化率,加購購買轉化率,關注購買轉化率,點選購買使用者佔比,點選加購使用者佔比,點選關注使用者佔比,瀏覽購買轉化使用者佔比,加購購買轉化使用者佔比,關注購買轉化使用者佔比,瀏覽使用者數,點選使用者數,關注使用者數,加購車使用者數,下單使用者數,取消關注使用者數,平均每天瀏覽/點選/購買/關注量(使用者數),平均每個使用者瀏覽/點選/購買/關注量
3-3 品牌維度(script/dim_feature_v3/dim_brand_feature_etl.sql):瀏覽量,點選量,關注量,加購車量,下單量,取消關注量,點選購買率,點選加購率,點選關注率,瀏覽購買轉化率,加購購買轉化率,關注購買轉化率,點選購買使用者佔比,點選加購使用者佔比,點選關注使用者佔比,瀏覽購買轉化使用者佔比,加購購買轉化使用者佔比,關注購買轉化使用者佔比,瀏覽使用者數,點選使用者數,關注使用者數,加購車使用者數,下單使用者數,取消關注使用者數,平均每天瀏覽/點選/購買/關注量(使用者數),平均每個使用者瀏覽/點選/購買/關注量,商品熱度(點選量0.01+下單量0.5+加購量0.1-取消關注量0.1+關注量*0.1)
3-4 使用者-商品互動維度(script/dim_feature_v3/dim_user_sku_feature_etl.sql):瀏覽量,點選量,關注量,加購車量,下單量,取消關注量,點選購買率,點選加購率,點選關注率,瀏覽購買轉化率,加購購買轉化率,關注購買轉化率,瀏覽day數,點選day數,關注day數,加購車day數,下單day數,取消關注day數,最近瀏覽/點選/購買/關注距今天數,平均瀏覽/點選/購買/關注行為操作間隔天數
3-5 使用者品牌互動維度(script/dim_feature_v3/dim_user_brand_feature_etl.sql):瀏覽量,點選量,關注量,加購車量,下單量,取消關注量,點選購買率,點選加購率,點選關注率,瀏覽購買轉化率,加購購買轉化率,關注購買轉化率,瀏覽day數,點選day數,關注day數,加購車day數,下單day數,取消關注day數,最近瀏覽/點選/購買/關注距今天數,平均瀏覽/點選/購買/關注行為操作間隔天數
3-6 交叉類特徵(script/dim_feature_v3/feature_wide_table.sql):使用者-商品與使用者瀏覽/點選/關注/加購/下單/取消關注佔比,使用者-品牌與使用者瀏覽/點選/關注/加購/下單/取消關注佔比etc.
樣本選擇及特徵預處理
4-1 將觀察天未來5天有購買行為的使用者-商品對標記為正樣本,觀察天過去30天至未來5天有互動行為但未購買的使用者-商品對標記為負樣本。
Eg.(將2016-04-06~2016-04-10有下單的使用者-商品標記為正樣本,將2016-03-06~2016-04-10有互動但未下單的使用者-商品標記為負樣本)。
4-2 由於正負樣本比例極不平衡,正負樣本比例約為1500:2400000,採用了對正樣本進行重取樣及負樣本進行下采樣的方式來平衡正負樣本比例。
具體取樣方式為:將正樣本複製10份,同時將負樣本通過隨機取樣為200000
4-3 特徵預處理:對於型別型特徵:通過Spark VectorIndexer進行one-hot編碼。對於連續型特徵,通過Spark Normalizer進行歸一化。
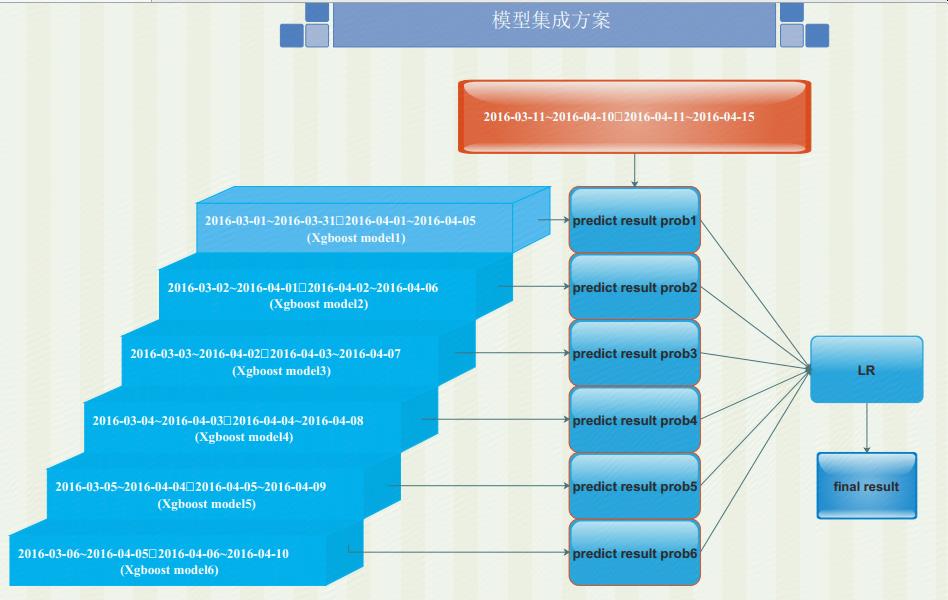
模型整合方案
利用spark-xgboost進行滑窗模型訓練,最後利用LR對各個預測結果進行加權。取每個使用者最高預測概率對應的user-sku對,取top 12000作為最終輸出結果。
單模型準確率xgboost>gbdt>rf,因此只選擇了xgboost以滑窗方式進行模型訓練,未採用多模型融合stacking,融合過程也只用了lr加權融合,其它方式待嘗試。
程式碼執行說明
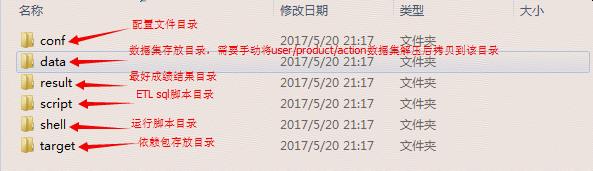
工程程式碼目錄:JData-Spark
使用maven進行原始碼編譯,成功編譯後會生成jdata-spark-1.0-SNAPSHOT-assembly.zip
jdata-spark-1.0-SNAPSHOT-assembly.zip目錄結構如下:
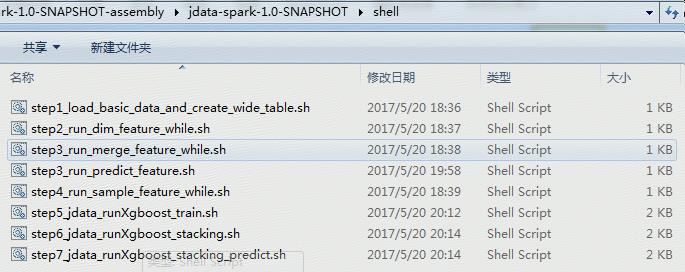
指令碼執行
進入到shell子目錄,目錄下各步驟指令碼如下:
各個步驟執行說明,各個步驟間有依賴,每個步驟執行完再執行下一個步驟【首先需要將比賽資料集解壓後手動放到data目錄下】:
6-2-1 step1_load_basic_data_and_create_wide_table.sh:載入資料集到hive表,並將user/product/action彙總加工成為一張基礎資料寬表。
執行命令:nohup sh step1_load_basic_data_and_create_wide_table.sh > tmp.log &
6-2-2 step2_run_dim_feature_while.sh:加工user/sku/brand/user_sku/user_brand各維度特徵,由於後續使用了滑窗整合,所以需要執行多份(part1-part12)。
執行命令:nohup sh step2_run_dim_feature_while.sh > tmp.log &
6-2-3 step3_run_merge_feature_while.sh:將各個維度的特徵彙總為一張寬表,便於後續進行抽樣及模型訓練。由於後續使用了滑窗整合,所以需要執行多份(part1-part12)。
執行命令:nohup sh step3_run_merge_feature_while.sh > tmp.log &
step3_run_predict_feature.sh:預測指標加工
執行命令:nohup sh step3_run_predict_feature.sh > tmp.log &
6-2-4 step4_run_sample_feature_while.sh:對加工的特徵寬表進行取樣
執行命令:nohup sh step4_run_sample_feature_while.sh > tmp.log &
由於模型訓練是在風控集市跑的spark任務,因此若要讓指令碼在其它集市可用,需要手動修改指令碼及配置檔案【影響步驟3.2.5,3.2.6,3.2.7】
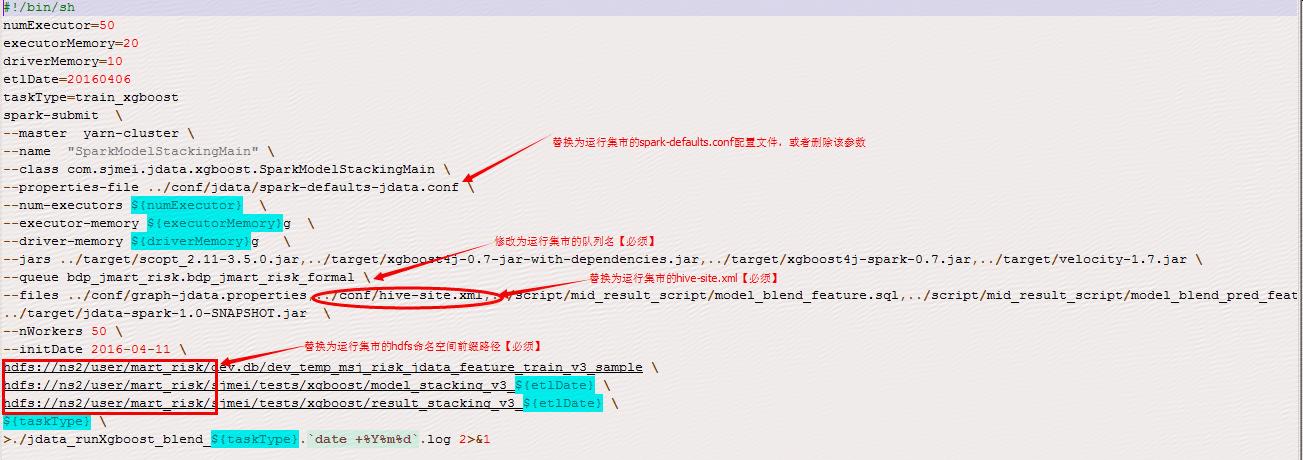
6-2-5 step5_jdata_runXgboost_train.sh:利用spark-xgboost進行模型訓練
執行命令:nohup sh step5_jdata_runXgboost_train.sh > tmp.log &
6-2-6 step6_jdata_runXgboost_stacking.sh:將spark-xgboost訓練好的6個子模型,進行stacking LR融合
執行命令:nohup sh step6_jdata_runXgboost_stacking.sh > tmp.log &
6-2-7 step7_jdata_runXgboost_stacking_predict.sh:利用3.2.6訓練好的融合模型,預測使用者在4.16-4.20會購買的user_sku對
執行命令:nohup sh step7_jdata_runXgboost_stacking_predict.sh > tmp.log &
6-2-8 待3.2.7步驟執行完後,需要手動將生成txt格式結果從hdfs目錄down下來,並按比賽要求的格式整理輸出
hadoop fs –get hdfs://ns2/user/mart_risk/sjmei/tests/xgboost/result_stacking_v3_20160406
總結
第一次參加資料探勘類比賽,作為一名新手,通過本次比賽,學習了資料探勘的整個流程,同時也進一步熟悉了spark ml框架的使用。其次,更多的是在實踐過程中體會到了自身的不足,要想打好比賽,必須源於對業務的深入理解及資料的細緻分析,而這一點恰恰是做的最不好的。比賽中沒有花很多時間對資料進行深入理解與細緻分析。在特徵處理,調參方面也做的很糙。 solo比賽很累,思維也很受限,只知道堆特徵+xgboost+lr融合的方案,看到排行榜上其他同學的成績都在噌噌地往上漲,而自己又不知道該如何優化漲分,成績也一直停滯不前,以後要多向大牛學習以及多和別的同學一起交流學習。
作為一名CS專業畢業的人,對於使用各種資料探勘工具進行技術實現不是什麼問題,但其實對於資料探勘來說,更重要的還是分析建模能力,對業務的感知能力,自己這方面還很欠缺,今後需要多多加強。
感謝公司舉辦的此次大賽,讓我獲益良多!