
損失函式 loss function 總結(轉)
目標函式,或稱損失函式,是網路中的效能函式,也是編譯一個模型必須的兩個引數之一。由於損失函式種類眾多,下面以keras官網手冊的為例。
在官方keras.io裡面,有如下資料:
-
mean_squared_error或mse
-
mean_absolute_error或mae
-
mean_absolute_percentage_error或mape
-
mean_squared_logarithmic_error或msle
-
squared_hinge
-
hinge
-
binary_crossentropy(亦稱作對數損失,logloss)
-
categorical_crossentropy:亦稱作多類的對數損失,注意使用該目標函式時,需要將標籤轉化為形如
(nb_samples, nb_classes)的二值序列 -
sparse_categorical_crossentrop:如上,但接受稀疏標籤。注意,使用該函式時仍然需要你的標籤與輸出值的維度相同,你可能需要在標籤資料上增加一個維度:
np.expand_dims(y,-1) -
kullback_leibler_divergence:從預測值概率分佈Q到真值概率分佈P的資訊增益,用以度量兩個分佈的差異.
-
cosine_proximity:即預測值與真實標籤的餘弦距離平均值的相反數
mean_squared_error
顧名思義,意為均方誤差,也稱標準差,縮寫為MSE,可以反映一個數據集的離散程度。
標準誤差定義為各測量值誤差的平方和的平均值的平方根,故又稱為均方誤差。
公式: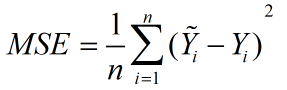
公式意義:可以理解為一個從n維空間的一個點到一條直線的距離的函式。(此為在圖形上的理解,關鍵看個人怎麼理解了)
mean_absolute_error
譯為平均絕對誤差,縮寫MAE。
平均絕對誤差是所有單個觀測值與算術平均值的偏差的絕對值的平均。
公式:(fi是預測值,yi是實際值,絕對誤差)
mean_absolute_percentage_error
譯為平均絕對百分比誤差 ,縮寫MAPE。
公式:(At表示實際值,Ft表示預測值)
mean_squared_logarithmic_error
譯為均方對數誤差,縮寫MSLE。
公式: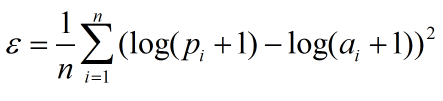 (n是整個資料集的觀測值,pi為預測值,ai為真實值)
(n是整個資料集的觀測值,pi為預測值,ai為真實值)
squared_hinge
公式為max(0,1-y_true*y_pred)^2.mean(axis=-1),取1減去預測值與實際值的乘積的結果與0比相對大的值的平方的累加均值。
hinge
公式為為max(0,1-y_true*y_pred).mean(axis=-1),取1減去預測值與實際值的乘積的結果與0比相對大的值的累加均值。
Hinge Loss 最常用在 SVM 中的最大化間隔分類中,
對可能的輸出 t = ±1 和分類器分數 y,預測值 y 的 hinge loss 定義如下:
L(y) = max(0,1-t*y)
看到 y 應當是分類器決策函式的“原始”輸出,而不是最終的類標。例如,線上性的 SVM 中
y = w*x+b
可以看出當 t 和 y 有相同的符號時(意味著 y 預測出正確的分類)
|y|>=1
此時的 hinge loss
L(y) = 0
但是如果它們的符號相反
L(y)則會根據 y 線性增加 one-sided error。(譯自wiki)
binary_crossentropy
即對數損失函式,log loss,與sigmoid相對應的損失函式。
公式:L(Y,P(Y|X)) = -logP(Y|X)
該函式主要用來做極大似然估計的,這樣做會方便計算。因為極大似然估計用來求導會非常的麻煩,一般是求對數然後求導再求極值點。
損失函式一般是每條資料的損失之和,恰好取了對數,就可以把每個損失相加起來。負號的意思是極大似然估計對應最小損失。
categorical_crossentropy
多分類的對數損失函式,與softmax分類器相對應的損失函式,理同上。
tip:此損失函式與上一類同屬對數損失函式,sigmoid和softmax的區別主要是,sigmoid用於二分類,softmax用於多分類(小編還在入門階段,,對於兩種對數損失函式的區別不甚清楚,推導也不大懂,歡迎大神補充,謝謝)。
sparse_categorical_crossentrop
在上面的多分類的對數損失函式的基礎上,增加了稀疏性(即資料中多包含一定0資料的資料集),如目錄所說,需要對資料標籤新增一個維度np.expand_dims(y,-1)。
kullback_leibler_divergence
(譯自WIKI)
對於離散隨機變數,其概率分佈P 和 Q的KL散度可按下式定義為
即按概率P求得的P和Q的對數差的平均值。KL散度僅當概率P和Q各自總和均為1,且對於任何i皆滿足
Q(i)>0及P(i)>0時,才有定義。式中出現0Ln0的情況,其值按0處理。
對於連續隨機變數,其概率分佈P和Q可按積分方式定義為
其中p和q分別表示分佈P和Q的密度。
更一般的,若P和Q為集合X的概率測度,且Q關於P絕對連續,則從P到Q的KL散度定義為
其中,假定右側的表達形式存在,則為Q關於P的R–N導數。
相應的,若P關於Q絕對連續,則
即為P關於Q的相對熵,用以度量兩個分佈的差異。
cosine_proximity
此方法用餘弦來判斷兩個向量的相似性。
設向量 A = (A1,A2,...,An),B = (B1,B2,...,Bn),則有
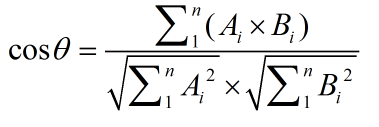
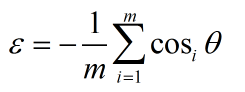
餘弦值的範圍在[-1,1]之間,值越趨近於1,代表兩個向量的方向越趨近於0,他們的方向更加一致。相應的相似度也越高。