
Lucene&&Solr中的域(Filed)總結
引言
Field類是文件索引期間很重要的類,控制著被索引的域值,下面先來看幾種常用的域型別:
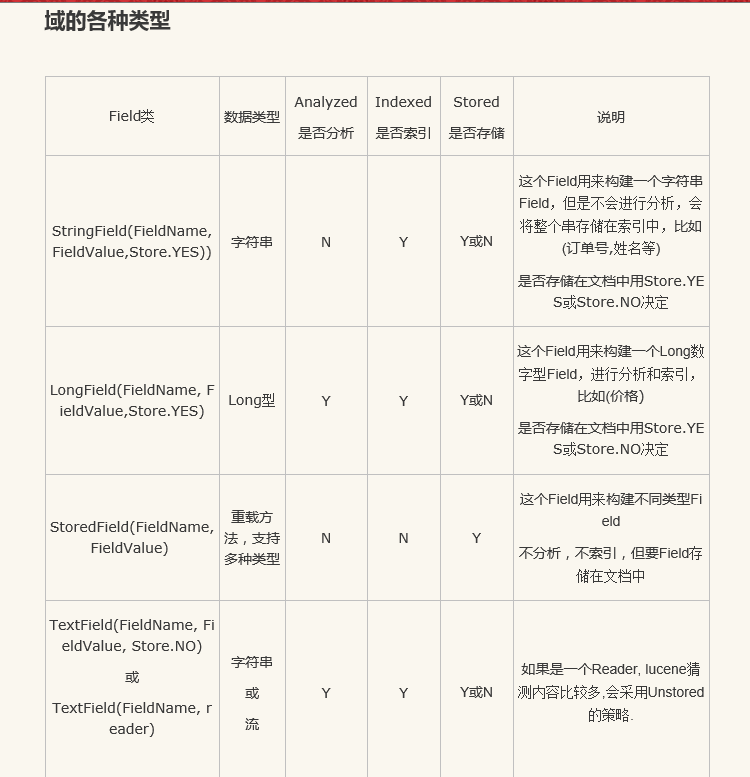
下面對上面幾個屬相進行介紹
是否分詞:
分詞的作用是為了索引
需要分詞: 檔名稱, 檔案內容
不需要分詞: 不需要索引的域不需要分詞,還有就是分詞後無意義的域不需要分詞 比如: id, 身份證號
是否索引:
索引的的目的是為了搜尋.
需要搜尋的域就一定要建立索引,只有建立了索引才能被搜尋出來
不需要搜尋的域可以不建立索引
需要索引: 檔名稱, 檔案內容, id, 身份證號等
不需要索引: 比如圖片地址不需要建立索引, e:\\xxx.jpg,因為根據圖片地址搜尋無意義
是否儲存:
儲存的目的是為了顯示.
是否儲存看個人需要,儲存就是將內容放入Document文件物件中儲存出來,會額外佔用磁碟空間, 如果搜尋的時候需要馬上顯示出來可以放入document中也就是要儲存,這樣查詢顯示速度快, 如果不是馬上立刻需要顯示出來,則不需要儲存,因為額外佔用磁碟空間不划算.
在lucene中使用域
File[] listFiles = f.listFiles(); for (File file : listFiles) { // 第三步建立document物件 Document document = new Document(); String file_name = file.getName(); // 建立域 Field fileNameField = new TextField("fileName", file_name, Store.YES);long file_size = FileUtils.sizeOf(file); Field fileSizeField = new LongField("fileSize", file_size, Store.YES); // 檔案路徑 String file_path = file.getPath(); Field filePathField = new StoredField("filePath", file_path); // 檔案內容 String file_content = FileUtils.readFileToString(file); Field fileContentField = new TextField("fileContent", file_content, Store.NO); document.add(fileNameField); document.add(fileSizeField); document.add(filePathField); document.add(fileContentField); // 第四步 使用 indexwriter物件將docum物件寫人索引庫,此過程進行索引建立。並將索引和document物件寫入索引庫 indexWriter.addDocument(document); }
Solr中域的介紹
域的使用
我們在新增索引的時候,使用域必須是在配置檔案中配置的,如果我們使用的索引在配置檔案中不存在,將會報錯,索引新增失敗,此時如果我們的需求要求我們必須使用這個域名,則我們需要自己在配置檔案新增這個域的定義,在對應的collection下面的schema.xml檔案中新增:
<field name="item_title" type="text_ik" indexed="true" stored="true"/>
<field name="item_sell_point" type="text_ik" indexed="true" stored="true"/>
<field name="item_price" type="float" indexed="true" stored="true"/>
<field name="item_num" type="int" indexed="true" stored="true"/>
<field name="item_image" type="string" indexed="false" stored="true"/>動態域
為了更好的滿足我們在專案中的需求,在原有的配置檔案中,還有一些域採取了萬用字元的模式定義,這些域被稱為動態域,只要滿足這些域的模式,即可使用
<dynamicField name="*_i" type="int" indexed="true" stored="true"/>
<dynamicField name="*_is" type="int" indexed="true" stored="true" multiValued="true"/>
<dynamicField name="*_s" type="string" indexed="true" stored="true" />
<dynamicField name="*_ss" type="string" indexed="true" stored="true" multiValued="true"/>
<dynamicField name="*_l" type="long" indexed="true" stored="true"/>
<dynamicField name="*_ls" type="long" indexed="true" stored="true" multiValued="true"/>
<dynamicField name="*_t" type="text_general" indexed="true" stored="true"/>
<dynamicField name="*_txt" type="text_general" indexed="true" stored="true" multiValued="true"/>
<dynamicField name="*_en" type="text_en" indexed="true" stored="true" multiValued="true"/>
<dynamicField name="*_b" type="boolean" indexed="true" stored="true"/>
<dynamicField name="*_bs" type="boolean" indexed="true" stored="true" multiValued="true"/>複製域
複製域的目的是將多個域合併為一個域,這樣我們按照多個條件查詢的時候,可以值傳送一個get請求就可以完成,如果我們定義了複製域,在我們儲存資料的時候,我們只負責儲存兩個域,但是實際上在索引庫中儲存了三個域,複製域就是solr內部自動合併的,定格式如下:
<field name="item_keywords" type="text_ik" indexed="true" stored="false" multiValued="true"/>
<copyField source="item_title" dest="item_keywords"/>
<copyField source="item_sell_point" dest="item_keywords"/>自定義域型別
<!-- IKAnalyzer -->
<fieldType name="text_ik" class="solr.TextField">
<analyzer class="org.wltea.analyzer.lucene.IKAnalyzer"/>
</fieldType>小結
域是全文搜尋的一個基礎,所以我們需要好好掌握這個概念,因為lucene是solr的基礎,所以在這小編將他們兩個放在一起介紹了,後面部落格中會繼續講解solr的相關知識