
歸一化方法總結

1、線性函式歸一化(Min-Max scaling),線性函式將原始資料線性化的方法轉換到[0 1]的範圍,歸一化公式如下:

該方法實現對原始資料的等比例縮放,其中Xnorm為歸一化後的資料,X為原始資料,Xmax、Xmin分別為原始資料集的最大值和最小值。
2、0均值標準化(Z-score standardization),0均值歸一化方法將原始資料集歸一化為均值為0、方差1的資料集,歸一化公式如下:

其中,μ、σ分別為原始資料集的均值和方法。該種歸一化方式要求原始資料的分佈可以近似為高斯分佈,否則歸一化的效果會變得很糟糕。
以上為兩種比較普通但是常用的歸一化技術,那這兩種歸一化的應用場景是怎麼樣的呢?什麼時候第一種方法比較好、什麼時候第二種方法比較好呢?下面做一個簡要的分析概括:
1、在分類、聚類演算法中,需要使用距離來度量相似性的時候、或者使用PCA技術進行降維的時候,第二種方法(Z-score standardization)表現更好。
2、在不涉及距離度量、協方差計算、資料不符合正太分佈的時候,可以使用第一種方法或其他歸一化方法。比如影象處理中,將RGB影象轉換為灰度影象後將其值限定在[0 255]的範圍。
///////////////////////////////////////////////////////////////////////////////////////////////////
關於神經網路歸一化方法的整理
由於採集的各資料單位不一致,因而須對資料進行[-1,1]歸一化處理,歸一化方法主要有如下幾種,供大家參考:(by james)
1、線性函式轉換,表示式如下:
y=(x-MinValue)/(MaxValue-MinValue)
說明:x、y分別為轉換前、後的值,MaxValue、MinValue分別為樣本的最大值和最小值。
2、對數函式轉換,表示式如下:
y=log10(x)
說明:以10為底的對數函式轉換。
3、反餘切函式轉換,表示式如下:
y=atan(x)*2/PI
歸一化是為了加快訓練網路的收斂性,可以不進行歸一化處理
歸一化的具體作用是歸納統一樣本的統計分佈性。歸一化在0-1之間是統計的概率分佈,歸一化在-1–+1之間是統計的座標分佈。歸一化有同一、 統一和合一的意思。無論是為了建模還是為了計算,首先基本度量單位要同一,神經網路是以樣本在事件中的統計分別機率來進行訓練(概率計算)和預測的,歸一 化是同一在0-1之間的統計概率分佈;
當所有樣本的輸入訊號都為正值時,與第一隱含層神經元相連的權值只能同時增加或減小,從而導致學習速度很慢。為了避免出現這種情況,加快網路學習速度,可以對輸入訊號進行歸一化,使得所有樣本的輸入訊號其均值接近於0或與其均方差相比很小。
歸一化是因為sigmoid函式的取值是0到1之間的,網路最後一個節點的輸出也是如此,所以經常要對樣本的輸出歸一化處理。所以這樣做分類的問題時用[0.9 0.1 0.1]就要比用[1 0 0]要好。
但是歸一化處理並不總是合適的,根據輸出值的分佈情況,標準化等其它統計變換方法有時可能更好。
關於用premnmx語句進行歸一化:
premnmx語句的語法格式是:[Pn,minp,maxp,Tn,mint,maxt]=premnmx(P,T)
其中P,T分別為原始輸入和輸出資料,minp和maxp分別為P中的最小值和最大值。mint和maxt分別為T的最小值和最大值。
premnmx函式用於將網路的輸入資料或輸出資料進行歸一化,歸一化後的資料將分佈在[-1,1]區間內。
我們在訓練網路時如果所用的是經過歸一化的樣本資料,那麼以後使用網路時所用的新資料也應該和樣本資料接受相同的預處理,這就要用到tramnmx。
下面介紹tramnmx函式:
[Pn]=tramnmx(P,minp,maxp)
其中P和Pn分別為變換前、後的輸入資料,maxp和minp分別為premnmx函式找到的最大值和最小值。
(by terry2008)
matlab中的歸一化處理有三種方法
1. premnmx、postmnmx、tramnmx
2. restd、poststd、trastd
3. 自己程式設計
具體用那種方法就和你的具體問題有關了
(by happy)
pm=max(abs(p(i,:))); p(i,:)=p(i,:)/pm;
和
for i=1:27
p(i,:)=(p(i,:)-min(p(i,:)))/(max(p(i,:))-min(p(i,:)));
end 可以歸一到0 1 之間
0.1+(x-min)/(max-min)*(0.9-0.1)其中max和min分別表示樣本最大值和最小值。
這個可以歸一到0.1-0.9
=============
資料型別相互轉換
這種轉換可能發生在算術表示式、賦值表示式和輸出時。轉換的方式有兩種:自動轉換和強制轉換。
========
自動轉換
自動轉換由編譯系統自動完成,可以將一種資料型別的資料轉換為另外一種資料型別的資料。
1)算術運算中的資料轉換
如果一個運算子有兩個不同型別的運算分量,C語言在計算該表示式時會自動轉換為同一種資料型別以便進行運算。先將較低型別的資料提升為較高的型別,從而使兩者的資料型別一致(但數值不變),然後再進行計算,其結果是較高型別的資料。 自動轉換遵循原則——“型別提升”:轉換按資料型別提升(由低向高)的方向進行,以保證不降低精度。 資料型別的高低是根據其型別所佔空間的大小來判定,佔用空間越大,型別越高。反之越低。 例如:算術運算x+y,如果x和y的型別都是int型變數,則x+y的結果自然是int型。如果x是short型而y是int型,則需要首先將x轉換為int型,然後再與y進行加法計算,表示式的結果為int型。
2)賦值運算的型別轉換
在執行賦值運算時,如果賦值運算子兩側的資料型別不同,賦值號右側表示式型別的資料將轉換為賦值號左側變數的型別。轉換原則是:當賦值運算子“=”右側表示式的值被計算出來後,不論是什麼型別都一律轉換為“=”左側的變數的型別,然後再賦值給左側的變數。
例如:float a;
a=10;? /*結果為a=10.0(資料填充)*/
int a;
a=15.5 /* 結果為a=15(資料擷取)*/
在賦值型別轉換時要注意數值的範圍不能溢位。既要在該資料型別允許的範圍內。如如果右側變數資料型別長度比左側的長時,將丟失一部分資料,從而造成資料精度的降低。
3)資料輸出時的型別轉換
在輸出時,資料將轉換為格式控制符所要求的型別。同樣可能發生資料丟失或溢位。型別轉換的實際情況是:字元型到整型是取字元的ASCII碼值;整型到字元型只是取其低8位;實型到整型要去掉小數部分;整型到實型數值不變,但以實數形式存放;雙精度到實型是四捨五入的。
========
強制轉換
一般情況下,資料型別的轉換通常是由編譯系統自動進行的,不需要程式設計師人工編寫程式干預,所以又被稱為隱式型別轉換。但如果程式要求一定將某一型別的資料從該種類型強制地轉換為另外一種型別,則需要人工程式設計進行強制型別轉換,也稱為顯式轉換。強制型別轉換的目地是使資料型別發生改變,從而使不同型別的資料之間的運算能夠進行下去。
語法格式如下:
(型別說明符)表示式
功能是強行地將表示式的型別轉換為括號內要求的型別。
例如:(int)4.2的結果是4;
又如:int x;
(float)x;x的值被強制轉換為實型,但是並不改變的x型別是整型。只是在參與運算處理時按照實型處理。
======
線性函式轉轉講一系列資料對映到相應區間,例如將所有資料對映到 1~100
可用下列函式
y=((x-min)/(max-min))*(100-1)+1
1-100 範圍內
min是資料集中最小值,max是最大值
///////////////////////////////////////////////////////////////////////////////////////////////////
為什麼在距離度量計算相似性、PCA中使用第二種方法(Z-score standardization)會更好呢?我們進行了以下的推導分析:
歸一化方法對方差、協方差的影響:假設資料為2個維度(X、Y),首先看0均值對方差、協方差的影響:
先使用第二種方法進行計算,我們先不做方差歸一化,只做0均值化,變換後資料為
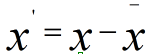
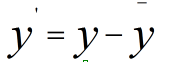
新資料的協方差為
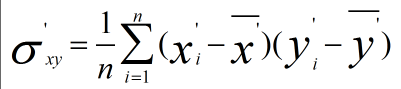
由於
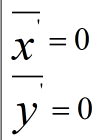
因此
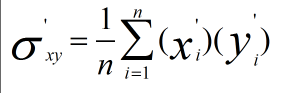
而原始資料協方差為
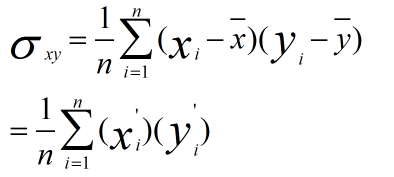
因此
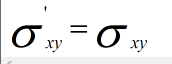
做方差歸一化後:
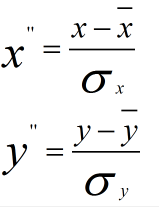
方差歸一化後的協方差為:

使用第一種方法進行計算,為方便分析,我們只對X維進行線性函式變換
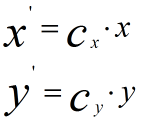
計算協方差
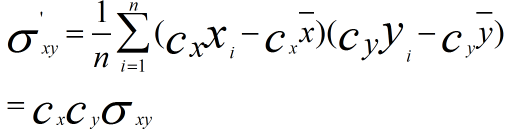
可以看到,使用第一種方法(線性變換後),其協方差產生了倍數值的縮放,因此這種方式無法消除量綱對方差、協方差的影響,對PCA分析影響巨大;同時,由於量綱的存在,使用不同的量綱、距離的計算結果會不同。
而在第二種歸一化方式中,新的資料由於對方差進行了歸一化,這時候每個維度的量綱其實已經等價了,每個維度都服從均值為0、方差1的正態分佈,在計算距離的時候,每個維度都是去量綱化的,避免了不同量綱的選取對距離計算產生的巨大影響。
總結來說,在演算法、後續計算中涉及距離度量(聚類分析)或者協方差分析(PCA、LDA等)的,同時資料分佈可以近似為狀態分佈,應當使用0均值的歸一化方法。其他應用中更具需要選用合適的歸一化方法。