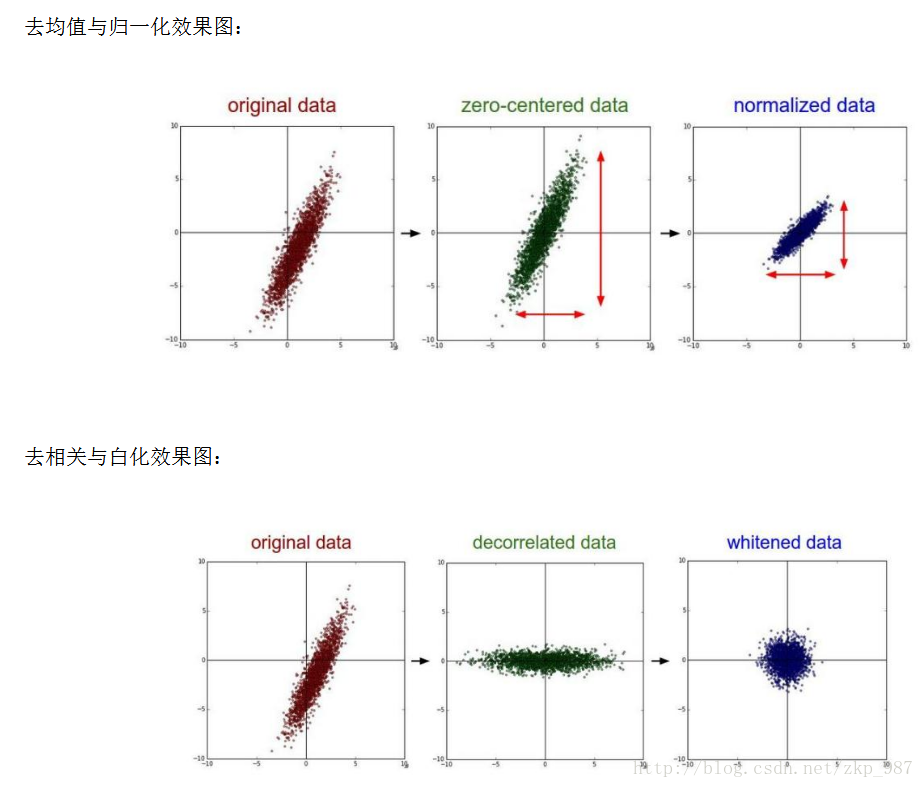
資料預處理的幾個方法:白化、去均值、歸一化、PCA
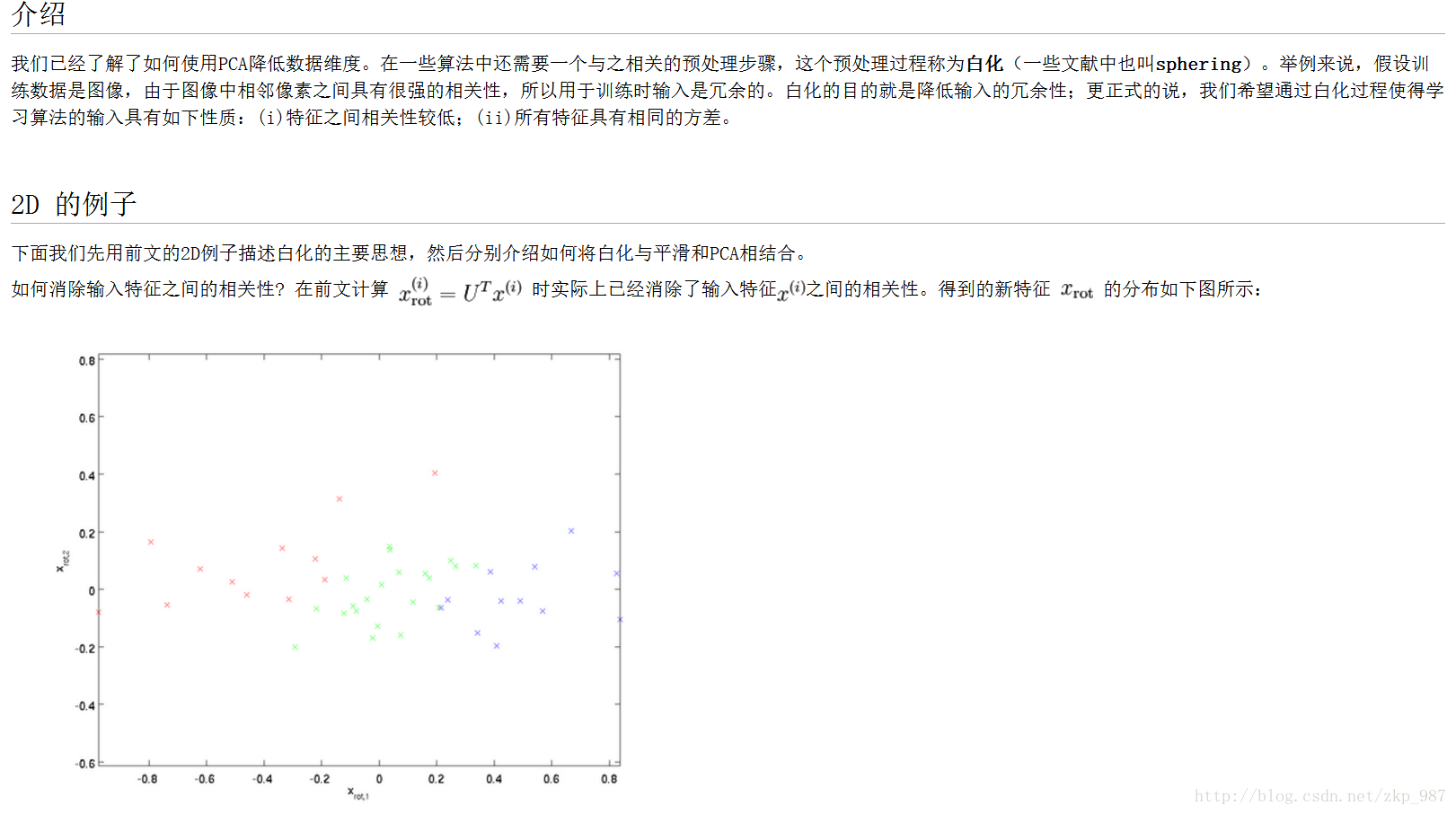


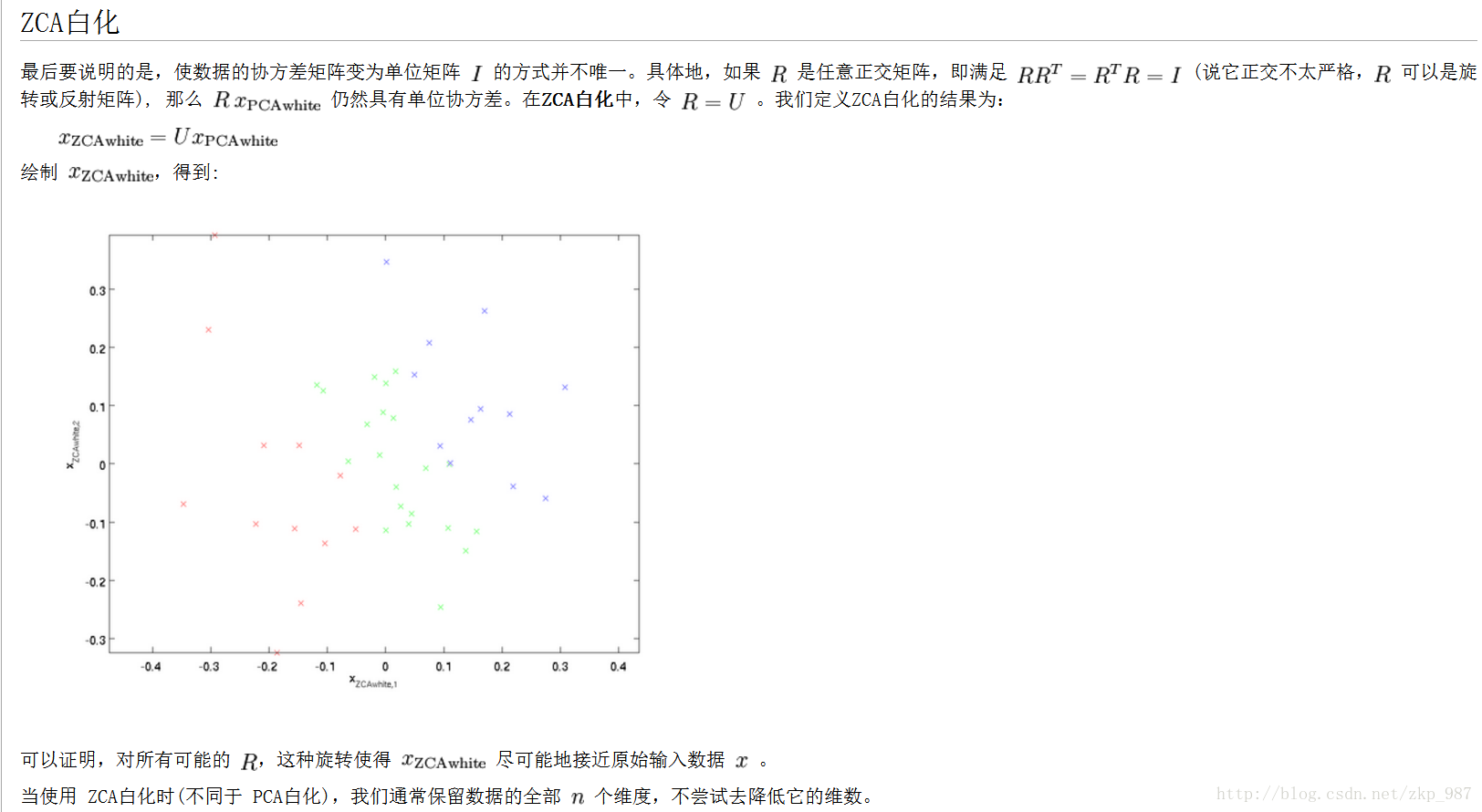
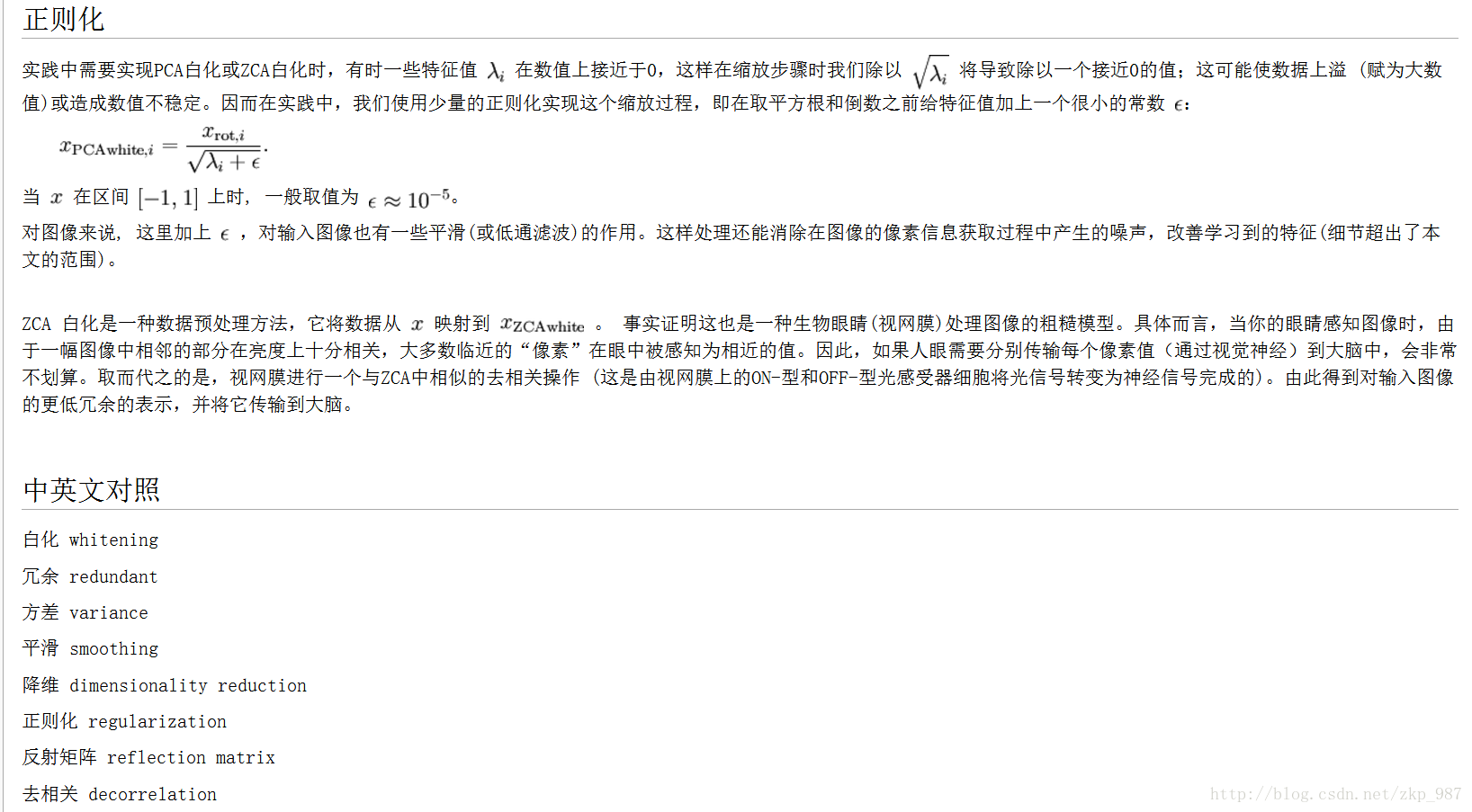
以上轉載自:http://ufldl.stanford.edu/wiki/index.php/%E7%99%BD%E5%8C%96
假定資料表示成矩陣為X,其中我們假定X是[N*D]維矩陣(N是樣本資料量,D為單張圖片的資料向量長度)。
去均值,這是最常見的圖片資料預處理,簡單說來,它做的事情就是,對待訓練的每一張圖片的特徵,都減去全部訓練集圖片的特徵均值,這麼做的直觀意義就是,我們把輸入資料各個維度的資料都中心化到0了。這麼做的目的是減小計算量,把資料從原先的標準座標系下的一個個向量組成的矩陣,變成以這些向量的均值為原點建立的座標系,使用python的numpy工具包,這一步可以用X -= np.mean(X, axis = 0)輕鬆實現。
歸一化,歸一化的直觀理解含義是,我們做一些工作去保證所有的維度上資料都在一個變化幅度上。通常我們有兩種方法來實現歸一化。一個是在資料都去均值之後,每個維度上的資料都除以這個維度上資料的標準差(X /= np.std(X, axis = 0))。 另外一種方式是我們除以資料絕對值最大值,以保證所有的資料歸一化後都在-1到1之間。多說一句,其實在任何你覺得各維度幅度變化非常大的資料集上,你都 可以考慮歸一化處理。不過對於影象而言,其實這一步反倒可做可不做,畫素的值變化區間都在[0,255]之間,所以其實影象輸入資料天生幅度就是一致的。
PCA和白化/whitening,這是另外一種形式的資料預處理。在經過去均值操作之後,我們可以計算資料的協方差矩陣,從而可以知道資料各個維度之間的相關性,簡單示例程式碼如下:
假定輸入資料矩陣X是[N*D]維的
X -= np.mean(X, axis = 0) # 去均值
cov = np.dot(X.T, X) / X.shape[0] # 計算協方差
得到的結果矩陣中元素(i,j)表示原始資料中,第i維和第j維的相關性。有意思的是,其實協方差矩陣的對角線包含了每個維度的變化幅度。另外,我們都知道協方差矩陣是對稱的,我們可以在其上做矩陣奇異值分解(SVD factorization):
U,S,V = np.linalg.svd(cov)
其中U為特徵向量,我們如果相對原始資料(去均值之後)去做相關操作,只需要進行如下運算:
Xrot = np.dot(X, U)
這麼理解一下可能更好,U是一組正交基向量。所以我們可以看做把原始資料X投射到這組維度保持不變的正交基底上,從而也就完成了對原始資料的去相關。如果去相關之後你再求一下Xrot的協方差矩陣,你會發現這時候的協方差矩陣是一個對角矩陣了。而numpy中的np.linalg.svd更好的一個特性是,它返回的U是對特徵值排序過的,這也就意味著,我們可以用它進行降維操作。我們可以只取top的一些特徵向量,然後做和原始資料做矩陣乘法,這個時候既降維減少了計算量,同時又儲存下了絕大多數的原始資料資訊,這就是所謂的主成分分析/PCA:
Xrot_reduced = np.dot(X, U[:,:100])
這個操作之後,我們把原始資料集矩陣從[N*D]降維到[N*100],儲存了前100個能包含絕大多數資料資訊的維度。實際應用中,你在PCA降維之後的資料集上,做各種機器學習的訓練,在節省空間和時間的前提下,依舊能有很好的訓練準確度。
最後再提一下whitening操作。所謂whitening,就是把各個特徵軸上的資料除以對應特徵值, 從而達到在每個特徵軸上都歸一化幅度的結果。whitening變換的幾何意義和理解是,如果輸入的資料是多變數高斯,那whitening之後的 資料是一個均值為0而不同方差的高斯矩陣。這一步簡單程式碼實現如下:
白化資料
Xwhite = Xrot / np.sqrt(S + 1e-5)
提個醒:whitening操作會有嚴重化噪聲的可能。注意到我們在上述程式碼中,分母的部分加入了一個很小的數1e-5,以防止出現除以0的情況。 但是資料中的噪聲部分可能會因whitening操作而變大,因為whitening操作的本質是把輸入的每個維度都拉到差不多的幅度,那麼本不相關的有微弱幅度變化的 噪聲維度,也被拉到了和其他維度同樣的幅度。當然,我們適當提高分母中的安全因子(1e-5)可以在一定程度上緩解這個問題。
下面給出圖示: