
資料結構與演算法23-查詢
查詢概念
查詢表(Search Table)是由同一型別的資料元素(或記錄)構成的集合。
關鍵字(Key)是資料元素中某個資料的值。又稱為鍵值。可以標識一個記錄的某個資料項(欄位),我們稱為關鍵碼。
若此關鍵字可以唯一地標識一個記錄,則稱此關鍵字為主關鍵字(Primary Key)。這說明對不同的記錄,其主關鍵字均不相同。主關鍵字所在的資料項稱為主關鍵碼。
對於那些可能識別多個數據元素(或記錄)的關鍵字,我們稱為次關鍵字(Sceondary Key)。
查詢就是根據給定的某個值,在查詢表中確定一個其關鍵字等於給定值的資料元素(或記錄)
靜態查詢表(Static Search Table):只作查詢操作的查詢表。
1. 查詢某個“特定的”資料元素是否在查詢表中
2. 檢索某個“特定的”資料元素和各種屬性。
就是在在已經有的資料中找到我們需要的。但是往往有的時候我們是想在查詢結果後去對結果進行一些操作。
動態查詢表(Dynamic Search Table):在查詢過程中同時插入查詢表中不存在的資料元素,或者從查詢表中刪除已經存在的某個資料元素。顯然動態查詢表的操作就兩個:
1. 查詢時插入資料元素
2. 查詢時刪除資料元素
為了提高查詢的效率,我們需要專門為查詢操作設定資料結構,這種面向查詢操作的資料結構稱為查詢結構。
從邏輯上來說,查詢所基於的資料結構是集合,集合中的記錄之間沒有本質關係。可是要想獲得較高的查詢效能,我們就不能不改變資料元素之間的關係,在儲存時(記憶體裡)可以將查詢集合組織成表、樹等結構。
順序表查詢
比如對散落的一堆書進行查詢,散落的圖書可以理解為一個集合,而將它們排列整齊,就如同是將此集合構造成一個線性表。我們要針對這一線性表進行查詢操作,因此它就是靜態查詢表
順序查詢(Sequential Search)又叫線性查詢,是最基本的查詢技術,它的查詢過程是:從表中第一個(或最後一個)記錄開始,逐個進行記錄的關鍵字和給定值比較,若某個記錄的關鍵字和給定的值相等,則查詢成功,找到所查的燒錄;如果直至最後一個(或第一個)燒錄,其關鍵字和給定值都不等時,則表中沒有所查的記錄查詢不成功。
順序表查詢演算法
/*順序查詢,a為陣列,n為要查詢的陣列長度,key為要查詢的關鍵字*/
int Sequential_Search(int *a,int n,int key)
{
int i;
for(i=1;i<=n;i++)
{
if(a[i]==key)
return i;
}
return 0;
}順序表查詢優化
int Sequential_Search2(int *a,int n,int key)
{
int i;
a[0]=key; //設定a[0]為關鍵字值,我們稱之為“哨兵”
i=n; //迴圈從陣列尾部開始
while(a[i]!=key)
{
i--;
}
return i; //返回0則說明查詢失敗。
}如果有key則返回i值,否則一定在最終a[0]處等於key,返回0。說明a[1]~a[n]中沒有關鍵字key,查詢失敗。
這種在查詢方向的盡頭放置“哨兵”免去了在查詢過程中每一次比較後都要判斷查詢位置是否越界的小技巧,看假與原先差別不大,但在總資料較多時,效率提高很大,是非常好的編碼技巧。
有序表查詢
對於一個線性表有序時,對於查詢總是很有幫助
折半查詢
折半查詢(Binary Search)技術,又稱為二分查詢。它的前提是線性表中的記錄必須是關鍵碼有序(通常從小到大有序),線性表必須採用順序儲存。取中間記錄作為比較物件,若給定值與中間記錄的關鍵字相等,查詢成功,若小於中間記錄的關鍵字,則在中間記錄的左半區繼續查詢;若給定值大於中間記錄的關鍵字,則在中間記錄的右半區繼續查詢。不斷重複上述過程,直至查詢成功,或所有查詢區域無記錄,查詢失敗為止。
{0,1,16,24,35,47,59,62,73,88,99},除0下標外共10個數字
對它進行查詢是否存在62這個數。我們來看折半查詢的演算法是如何工作的
int Binary_Search(in *a,int n,int key)
{
int low,high,mid;
low=1;
hight=n;
while(low<=high)
{
mid=(low+high)/2
if(key<a[mid])
high=mid-1;
else if(key>a[mid])
low=mid+1;
else
return mid;
}
return 0;
}
插值查詢
我們將折半查詢的計算略微變成一下如下:

改進為下面的計算方案:

將1/2改成了

實際上就是將查詢程式碼中的第8行改為

插值查詢(Interpolation Search),是根據要查詢的關鍵字key與查詢表中最大最小記錄的關鍵字比較後的查詢方法,其核心就在於插值的計算公式
斐波那契查詢
它是用黃金分割原理來實現的。為了能夠介紹清楚這個查詢演算法,我們先需要有一個斐婆那契數列的陣列。如圖

我們來看一下程式碼如下:
int Fibonacci_Search(int *a ,int n,int key)
{
int low,higth,mid,i,k;
low=1;
high=n;
k=0;
while(n>F[k]-1) //計算n位於斐波那契數列的位置
k++;
for(i=n;i<F[k]-1;i++) //將不滿的數值補全
a[i]=a[n];
while(low<=high)
{
mid = low+F[k-1]-1; //計算當前分隔的下標
if(key<a[mid]) //若查詢記錄小於當前分隔記錄
{
high = mid-1; //最高下標調整到分隔下標的mid-1處
k =k-1;//斐婆那契數列下標減一位。
}
else if(key>a[mid]) //查詢記錄大於分隔記錄
{
low=mid+1;
k=k-2;
}
else
{
if(mid<=n)
return mid; //若相等則說明mid即為查詢到的位置
else
return n; //mid>n說明是補全數值,返回n
}
}
}模擬一下
1. 程式開始執行,引數a={0,1,16,24,35,47,59,62,73,88,99} n=10,要查詢的關鍵字key=59。注意此時我們已經有了事先計算好的全域性變數陣列F的具體資料,它是斐波那契數列F={0,1,1,2,3,5,8,13,21,…}
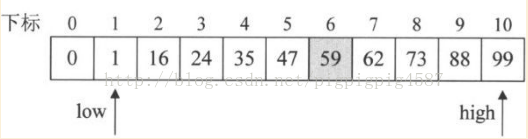
2. 第6~8行是計算當前的n處於斐波那契數列的位置。現在n=10,F[6]<n<F[7],所以計算得出k=7
3. 第9~10行,由於k=7,計算時,是以F[7]=13為基礎,而a中最大的僅是a[10],後面的a[11],a[12]均未賦值,這不能構成有序數列,因此將它們賦值為最大陣列值,所以此時,a[11]=a[12]=a[10]=99
4. 11~31行查詢正式開始
5. 第13行,mid=1+F[7-1]-1=8,也就是說,我們第一個要對比的數值是從下標為8開始的。
6. 由於此時key=59而a[8]=73,因此執行第16~17行,得到high=7,k=6
7. 再次迴圈,mid=1+F[6-1]-1=5,此時a[5]=47<key,因此執行21~22行,得到low=6,k=6-2=4。注意此時k下調2個單位。
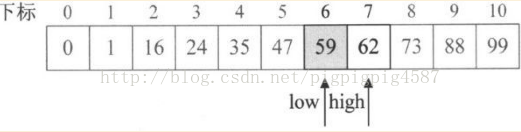
8. 再次迴圈,mid=6+F[4-1]-1=7。此時a[7]=62>key,因此執行16~17行,得到high=6,k=4-1=3;

9. 再次迴圈,mid=6+F[3-1]-1=6。此時a[6]=59=key。因此執行執行第26~27行,得到返回值6。程式執行結構。
如果key=99,此時查詢迴圈第一次時,mid=8與上例是相同的,第二次迴圈時,mid=11,如果a[11]沒有值就會使得與key的比較失敗,為了避免這樣的情況出現,第9~10行的程式碼就起到這樣的作用。
斐波那契查詢演算法的核心在於:
1. 當key=a[mid]時,查詢就成功
2. 當key<a[mid]時,新範圍是第low個到第mid-1個,此時範圍個數為F[k-1]-1個
3. 當key>a[mid]時,新範圍是第mid+1個到第hight個,此時範圍個數為F[k-2]-1個
折半查詢是進行的加法與除法運算(mid=(low+high)/2),插值查詢進行的是複雜的四則運算(mid=low+(high-low)*(key-a[low])/(a[high]-a[low])),而斐波那契查詢只是最簡單的加減法運算。對於海量資料會有效率上的影響
本質上有序表的查詢本質上是分隔點選擇不同,各有優劣。