
K-近鄰法(KNN演算法)
1、kNN演算法(K 最近鄰(k-Nearest Neighbors))描述
簡單地說,k-近鄰演算法採用測量不同特徵值之間的距離方法進行分類。
k-近鄰演算法是一種基本分類與迴歸方法;它是是監督學習中分類方法的一種,屬於懶散學習法(惰性學習方法)。
給定一個訓練集D和一個測試物件z,該測試物件是一個由屬性值和一個未知的類別標籤組成的向量,該演算法需要計算z和每個訓練物件之間的距離(或相似度),這樣就可以確定最近鄰的列表。然後將最近鄰中例項數量佔優的類別賦給z。(主要思想是如果一個樣本在特徵空間中的k個最近的樣本中的大多數都屬於某個類別,則該樣本屬於這個類別,並具有這個類別上的特性 )。
註釋: (1)所謂監督學習與非監督學習,是指訓練資料是否有標柱類別,若有則為監督學習,否則為非監督學習。 監督學習是指根據訓練資料學習一個模型,然後能對後來的輸入做預測。在監督學習中,輸入變數和輸出變數可以是連續的,也可以是離散的。若輸入變數和輸出變數均為連續變數,則稱為迴歸;輸出變數為有限個離散變數,則稱為分類。
(2)懶散學習法在訓練過程中不需要做許多處理。只有當新的未被分類的資料輸入時,這類演算法才會去做分類。積極學習法則會在訓練中建立一個分類模型,當新的未分類資料輸入時,這類學習器會把新資料也提供給這個分類模型。
2.KNN演算法的工作原理:
存在一個樣本資料集合,也稱作為訓練樣本集,並且樣本集中每個資料都存在標籤,即我們知道樣本集中每一個數據與所屬分類的對應關係。輸入沒有標籤的新資料後,將新的資料的每個特徵與樣本集中資料對應的特徵進行比較,然後演算法提取樣本最相似資料(最近鄰)的分類標籤。一般來說,我們只選擇樣本資料集中前k個最相似的資料,這就是k-近鄰演算法中k的出處,通常k是不大於20的整數。最後,選擇k個最相似資料中出現次數最多的分類,作為新資料的分類。
3、KNN演算法的一般流程
(1)收集資料:可以使用任何方法。
(2)準備資料:距離計算所需要的數值,最好是結構化的資料格式。
(3)分析資料:可以使用任何方法。
(4)訓練演算法:此步驟不適用於k-近鄰演算法。
(5)測試演算法:計算錯誤率。
(6)使用演算法:首先需要輸入樣本資料和結構化的輸出結果,然後執行KNN演算法判定輸入資料分別屬於哪個分類,最後應用對計算出的分類執行後續處理
註釋:距離度量公式有:歐幾里得距離,明可夫斯基距離,曼哈頓距離,切比雪夫距離,馬氏距離等;相似度的度量公式有:餘弦相似度,皮爾森相關係數,Jaccard相似係數。 補充:歐幾里得距離度量會受特徵不同單位刻度的影響,所以一般需要先進行標準化處理。
類別的判斷方法:(1)投票決定:少數服從多數,近鄰中哪個類別的點最多就分為該類。
(2)加權投票法:根據距離的遠近,對近鄰的投票進行加權,距離越近則權重越大。 knn還可用於迴歸,目標樣本的屬性值是k個鄰居屬性值的平均值。
4、KNN演算法的優點和缺點
優點:
簡單,易於理解,易於實現,無需估計引數,無需訓練(不需要花費任何時間做模型的構造), 特別適合多分類問題,適合對稀有事件進行分類,精度高,對異常值不敏感,無資料輸入假定。
缺點:
消極學習法, 需要大量的儲存空間(需要儲存全部資料集), 耗時(需計算目標樣本與訓練集中每個樣本的值),可解釋性差;即該演算法的儲存複雜度是O(n),其中n為訓練物件的數量,時間複雜度也是O(n)(計算複雜度高,空間複雜度高)
註釋:
積極學習法:先根據訓練集構造出分類模型,根據分類模型對測試集分類。
消極學習法(基於例項的學習法):推遲建模,當給定訓練元組時,簡單地儲存訓練資料,一直等到給定一個測試樣本。
適用資料範圍:數值型和標稱型。(標稱型:一般在有限的資料中取,而且只存在‘是’和‘否’兩種不同的結果(一般用於分類);數值型:可以在無限的資料中取,而且數值比較具體化,例如4.02,6.23這種值(一般用於迴歸分析))
5、應用KNN的常見問題
(1)k值設定為多大?
k太小,分類結果易受噪聲的影響;k太大,近鄰中又可能包含太多的其它類別的點。(對距離加權,可以降低k值設定的影響)。
k值通常是採用交叉檢驗來確定(以k=1為基準)。
經驗規則:k一般低於訓練樣本數的平方根
(2)類別如何判定最合適?
投票法沒有考慮近鄰的距離的遠近,距離更近的近鄰也許更應該決定最終的分類,所以加權投票法更恰當一些。
(3)如何選擇合適的距離衡量?
高維度對距離衡量的影響:眾所周知當變數數越多,歐式距離的區分能力就越差。
變數值域對距離的影響:值域越大的變數常常會在距離計算中佔據主導作用,因此應先對變數進行標準化。
(4)訓練樣本是否要一視同仁?
在訓練集中,有些樣本可能是更值得依賴的。
可以給不同的樣本施加不同的權重,加強依賴樣本的權重,降低不可信賴樣本的影響。(如何判斷樣本可信不可信)
(5)能否大幅減少訓練樣本量,同時又保持分類精度?
濃縮技術(condensing)
編輯技術(editing)
6、KNN與推薦系統
利用KNN進行推薦的方法分為:
(1)user-based: 先利用KNN演算法找到與目標使用者興趣相似的k個使用者,再根據這些相似使用者的興趣為目標使用者進行推薦。
(2)item-based: 利用KNN計算與目標使用者喜歡的物品相似的k個物品,然後推薦給目標使用者
7、KNN演算法的應用領域
字元識別、文字分類、影象識別、改進約會網站、手寫識別系統、電影分類
KNN演算法簡單實戰:簡單的電影分類
需要模組:numpy(科學計算包),operator(運算子模組);
歐式距離公式:
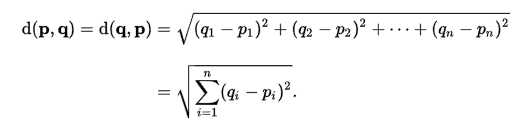
環境:python3.6 ,Pycharm
kNN.py
import numpy as np
import operator
'''
函式說明: 建立資料集
Returns:
group - 資料集
labels - 分類標籤
'''
def createDataSet():
group=np.array([[1,101],[5,89],[108,5],[115,8]]) #資料集,四組二維特徵
labels=['愛情片','愛情片','動作片','動作片'] #分類標籤,四組特徵的標籤
return group,labels
"""
函式說明:kNN演算法,分類器
Parameters:
inX - 用於分類的資料(測試集)
dataSet - 用於訓練的資料(訓練集)
labes - 分類標籤
k - kNN演算法引數,選擇距離最小的k個點
Returns:
sortedClassCount[0][0] - 分類結果
"""
def classify0(inX, dataSet, labels, k):
# numpy函式shape[0]返回dataSet的行數
dataSetSize = dataSet.shape[0]
# b = tile(a,(m,n)):即是把a數組裡面的元素複製n次放進一個數組c中,然後再把陣列c複製m次放進一個數組b中
diffMat = np.tile(inX, (dataSetSize, 1)) - dataSet
# 二維特徵相減後平方
sqDiffMat = diffMat ** 2
# sum()所有元素相加,sum(0)列相加,sum(1)行相加
sqDistances = sqDiffMat.sum(axis=1)
# 開方,計算出距離
distances = sqDistances ** 0.5
# 返回distances中元素從小到大排序後的索引值
sortedDistIndices = distances.argsort()
# 定一個記錄類別次數的字典
classCount = {}
for i in range(k):
# 取出前k個元素的類別
voteIlabel = labels[sortedDistIndices[i]]
# dict.get(key,default=None),字典的get()方法,返回指定鍵的值,如果值不在字典中返回預設值。
# 計算類別次數
classCount[voteIlabel] = classCount.get(voteIlabel, 0) + 1
# python3中用items()替換python2中的iteritems()
# key=operator.itemgetter(1)根據字典的值進行排序
# key=operator.itemgetter(0)根據字典的鍵進行排序
# reverse降序排序字典
sortedClassCount = sorted(classCount.items(), key=operator.itemgetter(1), reverse=True)
# 返回次數最多的類別,即所要分類的類別
return sortedClassCount[0][0]
if __name__ == '__main__':
# 建立資料集
group, labels = createDataSet()
# 測試集
test = [101, 20]
# kNN分類
test_class = classify0(test, group, labels, 3)
# 列印分類結果
print(test_class)結果為:

注意:numpy函式shape[0]、tile()的用法、sum(axis=1)、argsort()
參考資料:《機器學習實戰》