
python大規模資料處理技巧之一:資料常用操作
阿新 • • 發佈:2019-01-01
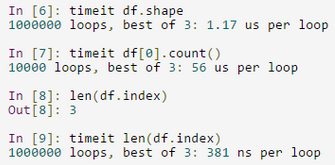
面對讀取上G的資料,python不能像做簡單程式碼驗證那樣隨意,必須考慮到相應的程式碼的實現形式將對效率的影響。如下所示,對pandas物件的行計數實現方式不同,執行的效率差別非常大。雖然時間看起來都微不足道,但一旦執行次數達到百萬級別時,其執行時間就根本不可能忽略不計了:
故接下來的幾個文章將會整理下渣渣在關於在大規模資料實踐上遇到的一些問題,文章中總結的技巧基本是基於pandas,有錯誤之處望指正。
1、外部csv檔案讀寫
大資料量csv讀入到記憶體
- 分析思路:資料量非常大時,比如一份銀行一個月的流水賬單,可能有高達幾千萬的record。對於一般效能的計算機,有或者是讀入到特殊的資料結構中,記憶體的儲存可能就非常吃力了。考慮到我們使用資料的實際情況,並不需要將所有的資料提取出記憶體。當然讀入資料庫是件比較明智的做法。若不用資料庫呢?可將大檔案拆分成小塊按塊讀入後,這樣可減少記憶體的儲存與計算資源
- 注意事項:open(file.csv)與pandas包的pd.read_csv(file.csv ): python32位的話會限制記憶體,提示太大的資料導致記憶體錯誤。解決方法是裝python64位。如果嫌python各種包安裝過程麻煩,可以直接安裝Anaconda2 64位版本
- 簡易使用方法:
chunker = pd.read_csv(PATH_LOAD, chunksize = CHUNK_SIZE)- 讀取需要的列:
columns = ("date_time", "user_id")
chunks_train = pd.read chunker物件指向了多個分塊物件,但並沒有將實際資料先讀入,而是在提取資料時才將資料提取進來。資料的處理和清洗經常使用分塊的方式處理,這能大大降低記憶體的使用量,但相比會更耗時一些
- 分塊讀取chunk中的每一行:
for rawPiece in chunker_rawData:
current_chunk_size = len(rawPiece.index) #rawPiece 是dataframe
for i in range(current_chunk_size ):
timeFlag = timeShape(rawPiece.ix[i]) #獲取第i行的資料 將資料存到硬碟
- 直接寫出到磁碟:
data.to_csv(path_save, index = False, mode = 'w')`- 分塊寫出到磁碟:
- 對於第一個分塊使用pandas包的儲存IO:
- 保留header資訊,‘w’模式寫入
data.to_csv(path_save, index = False, mode = 'w')- 接下的分塊寫入
- 去除header資訊,‘a’模式寫入,即不刪除原文件,接著原文件後繼續寫
data.to_csv(path_save, index = False, header = False, mode = a')
- 少量的資料寫出:
少量的資料用pickle(cPickle更快)輸出和讀取,非常方便 ,下面分別是寫出和讀入
寫出:
import cPickle as pickle
def save_trainingSet(fileLoc, X, y):
pack = [X, y]
with open(fileLoc, 'w') as f:
pickle.dump(pack, f)讀入:
import cPickle as pickle
def read_trainingSet(fileLoc):
with open(fileLoc, 'r') as f:
pack = pickle.load(f)
return pack[0], pack[1]高效讀取外部csv到python內部的list資料結構
- 效率低下的方法:使用pd讀入需要從pd轉換到python本身的資料結構,多此一舉
userList = []
content = pd.read_csv(filename)
for i in range(len(content)):
line = content.ix[i]['id']
userList.append(line)- 效率高的方法:直接將外部資料讀入進來
userList = []
f = open(filename)
content = f.readlines()
for line in content:
line = line.replace('\n', '').split(',')
userList.append(line)2、資料分析時常用資料結構之間的轉化
資料集的橫向與縱向合併
- 簡單地橫向合併資料集:
- 問題分析:
- 縱向的合併使用list並不好,因為需要去拆解list的每一個行元素,並用extend去拓展每一行的縱向元素
- 最好使用dataframe中的concat函式:c = pd.concat([a, b], axis = 1),當axis=0時表示合併行(以行為軸)
inx1 = DataFrame(np.random.randn(nSample_neg), columns = ['randVal'])
inx2 = DataFrame(range(nSample_neg), columns = ['inxVal'])
inx = pd.concat([inx1, inx2], axis = 1)- 類似資料庫的表合併:join(待完整)
ret = ret.join(dest_small, on="srch_destination_id", how='left', rsuffix="dest")- 簡單縱向合併資料集:
- 縱向合併資料集可以考慮一下幾種方法:
- 讀取資料為list格式,使用append函式逐行讀取
- 將資料集轉換為pandas中的dataframe格式,使用dataframe的merge與concat方法
- 方法:
- 方法一:使用dataframe讀入,使用concat把每行並起來
- 方法二:先使用list讀入並起來,最後轉換成dataframe
- 方法三:先使用list讀入並起來大塊的list,每塊list轉換成dataframe後用concat合併起來
- 比較:方法一由於concat的靜態性,每次要重新分配資源,故跑起來很慢; 方法二與三:會快很多,但具體沒有測試,以下是使用方法三的程式碼:
data = []
cleanedPiece = []
for i in range(CHUNK_SIZE):
line = rawPiece.ix[i]
uid = [line['user_id'], line['item_id'],
line['behavior_type'], timeFlag]
cleanedPiece.append(uid)
cleanedPiece = DataFrame(cleanedPiece, columns = columns)
data = pd.concat([data, cleanedPiece], axis = 0)
<未完待續>