
Caffe學習5-用C++自定義層以及視覺化結果
用C++自定義 層以及視覺化結果
上一週,我們學校開始了實訓,我參與的專案是深度學習相關的,於是第一週我們專注與學習Caffe的使用,包括對Caffe的原始碼的理解。接著,我們被要求定義一個自己的資料輸入層,以完成特定的任務。
用C++自定義層
對於剛開始接觸Caffe的人來說,如果想要自定義一個屬於自己的層,那麼最好的工具就是:谷歌!
跟著上面了連結的指示一步步弄其實就可以了,小編這裡做一個總結,其實需要修改的就三處地方。
三處地方
第一處
如果要新增一個層,比如my_data_layer,那麼首先需要有一個.cpp檔案,很簡單的,我們可以直接進入到src/caffe/layers/裡面,找一個已有資料層拷貝為my_data_layer.cpp,然後根據我們的需要,修改下里面的程式碼(不知道怎麼修改?小編建議讀者最好就稍微的能夠看一下程式碼,其實註釋都寫得很清楚了…)。第二處
如果添加了一個.cpp,那下一步很自然的就是新增一個.hpp標頭檔案啦,過程也很簡單,進到include/caffe/layers/裡面,同樣複製一個已有的.hpp檔案(小編這裡建議讀者最好就複製跟.cpp對應的那個標頭檔案,這樣出錯的可能性就會小很多),複製完之後就修改一些type的返回值,改成“MyData”,這個對應後面在寫net.prototxt的時候的type。當然還有一些小修改,這個根據大家的要求做調整就好啦。第三處
第三處是src/caffe/proto/caffe.proto檔案,這個檔案聲明瞭大量的引數,因此,如果在編寫自己的層的時候使用了新的引數,那就需要到這裡來,新增一下對這些引數的一些宣告,具體怎麼新增,相信讀者進到這個檔案之後就知道怎麼添加了,這裡不多贅述。
注意:
如果在caffe.proto裡宣告的是my_data_param,那麼在.cpp 裡面也要把原本的(比如data_param,DataParam之類的)全部作出相應的修改(比如my_data_param, MyDataParam等)。否則在後面呼叫的時候,layer讀不了你宣告的引數,導致出錯。
重新編譯並測試
以上三步做好之後,我們需要重新編譯一下caffe。這裡如果我們修改過caffe.proto檔案,那麼在重新編譯的時候,會需要全部重新編譯過,所以一般就建議讀者caffe.proto檔案最好就只寫一次,不要多次修改。如果只是修改的layer.cpp或.hpp,那編譯的時候只需要重新編譯這個檔案,所以速度很快。在編譯結束後就可以自己寫個net.prototxt來黑皮一下啦~(然而這之後讀者可能會遇到一些列稀奇古怪的問題,不過一般看控制塔的輸出資訊就大概可以知道是什麼錯誤啦,再不行就谷歌咯~)
視覺化結果
視覺化loss
小編在做實驗的時候其實比較頭疼的一點是,訓練的loss一直在不斷的變化,一上一下的,看不出是否收斂或大致在收斂。這裡教讀者一個視覺化的方法,就是利用caffe的log檔案。
這個log檔案存放在/tmp/目錄下,一般命名方式是
caffe.[主機名].[使用者名稱].[log型別].[日期].[時間]
讀者可以根據自己執行的情況找到對應的log,訓練的輸出的log型別是INFO,因此我們可以對INFO型別的log寫個python指令碼,然後就可以看到收斂情況啦~這裡小編給出我編寫的一個指令碼的程式碼。
fhandle = open(filename) # filename是log檔案的路徑
lines = fhandle.readlines()
train_iter = []
train_loss = []
test_iter = []
test_loss = []
it = 0
for line in lines:
"""這部分程式碼用於提取train和test的loss資訊並存放到info字典下"""
linesp = line.split()
if 'Iteration' in linesp and 'lr' not in linesp:
it = int(linesp[5][:-1])
elif len(linesp) < 13:
continue
else:
if linesp[4] in ['Test', 'Train'] and linesp[8] == 'loss':
if linesp[4] == 'Train':
train_loss.append(float(linesp[10]))
train_iter.append(it)
else:
test_loss.append(float(linesp[10]))
test_iter.append(it)
info[connectfile] = [train_iter, train_loss, test_iter, test_loss]
f = 0 # f 代表想要檢視的iter的起始下標
e = -1 # e 代表想要檢視的iter的終止下標
smooth = 50 # smooth 用於調整曲線的平滑程度,原理是對周圍的smooth個loss做均值運算
for key in info:
"""這部分程式碼是把train的loss視覺化,如果需要視覺化test的結果,可以複製這部分程式碼並修改下下標即可"""
tmp1 = []
for i in range(f,len(info[key][1][f:e])+f):
start = i-smooth
end = i+smooth
start = 0 if start < 0 else start
end = len(info[key][1]) if end > len(info[key][1]) else end
tmp1.append(sum(info[key][1][start: end])/float(end-start))
plt.plot(info[key][0][f:e], np.array(tmp1))
plt.legend(info.keys())呼叫上面指令碼的結果如下
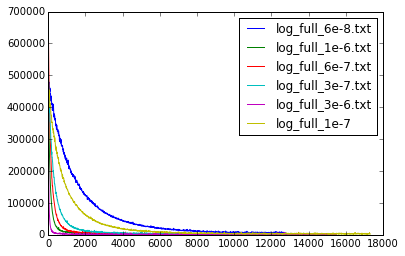
視覺化blobs
修改caffe.cpp
在訓練過程中,比較頭疼的是我們看不到caffe的中間結果。如果想要檢視caffe的中間結果,比如blob或layer,那麼我們可以到/tools/caffe.cpp裡面做一些稍微的修改。
比如我們希望在test的過程中,把loss層的輸入輸出到某個檔案,我們可以在test()函式裡面在迴圈裡面新增我們自己的程式碼,在每次forward之後,caffe的每個blob都進行了更新,這時我們可以用cpu_data或gpu_data的方法檢視每個blob的資料,然後有了資料,想怎麼處理就怎麼處理啦。
新增視覺化層
這個方法就是自己編寫一個新的層,然後把bottom裡的資料做處理,這種方法會很方便,推薦使用~
後記
這周的實訓還是能學到不少東西的,希望之後的內容也能夠越來越精彩,小編也會陸續更新部落格,把學到的分享出來,讀者者閱讀的過程中遇到什麼問題都可以在下方回覆哦~