
大資料學習--使用Hadoop2.6.0遇到的相關問題
學習和使用Hadoop Yarn已有半年多,其中遇到了一些常見問題,在網上搜索基本可以找到答案,出處已找不到,我只是對自己遇到的問題做個總結,也感謝解決這些問題的大神們,原諒我已經忘記到底從哪裡獲得的答案o(╯□╰)o。我目前使用的Hadoop版本是2.6.0。下面是我遇到的問題,以後會不定期更新:
- 配置了HDFS的federation,eclipse外掛配置連線Hadoop2.6.0後無法檢視遠端檔案目錄結構
- 使用Maven開發MapReduce時,無法下載Hadoop2.6.0相關包
- MapReduce工程報錯Missing artifact jdk.tools:jdk.tools:jar:1.7
- Container … is running beyond virtual memory limits
- Container … is running beyond physical memory limits
- java.lang.OutOfMemoryError: Java heap space
- 不關閉防火牆的情況下提交作業失敗
- containner日誌報錯找不到類方法
- 提交作業指定-D、-libjars等常規選項失敗
配置了HDFS的federation,eclipse外掛配置連線Hadoop2.6.0後無法檢視遠端檔案目錄結構
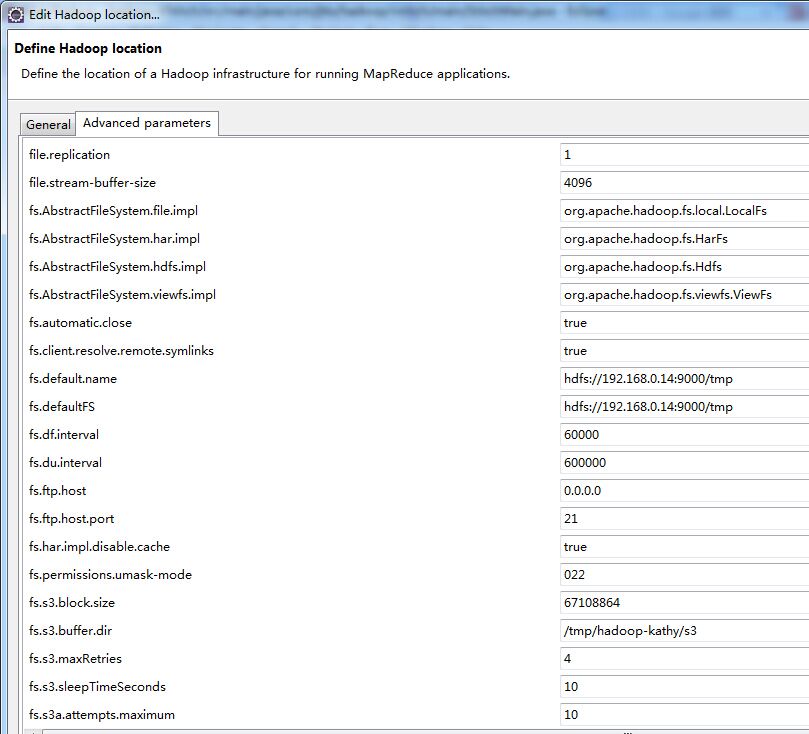
如圖所示,在Edit Hadoop location中,切換到Advanced parameters標籤,修改fs.defaultFS為hdfs://192.168.0.14:9000/tmp。其中/tmp就是我在配置檔案中配置的其中一個HDFS相對路徑。
使用Maven開發MapReduce時,無法下載Hadoop2.6.0相關包
在pom.xml中增加如下配置:
<repositories>
<repository>
<id>maven.oschina.net</id>
<url>http://maven.oschina.net/content/groups/public/</url>
</repository>
</repositories>MapReduce工程報錯Missing artifact jdk.tools:jdk.tools:jar:1.7
在pom.xml檔案中增加如下配置:
<dependency>
<groupId>jdk.tools</groupId>
<artifactId>jdk.tools</artifactId>
<version>1.7</version>
<scope>system</scope>
<systemPath>${JAVA_HOME}/lib/tools.jar</systemPath>
</dependency>Container … is running beyond virtual memory limits
具體報錯如下:
Container … is running beyond virtual memory limits. Current usage:498.0MB od 1GB physical memory used;2.7GB of 2.1GB virtual memory used.Killing container.
意思是虛擬記憶體不足,有幾種解決辦法,下面我說兩種:
1、修改yarn-site.xml配置檔案,可以增加yarn.nodemanager.vmem-pmem-ratio實體記憶體和虛擬記憶體的比例,但這種修改方法不好,需要重新啟動叢集才可以生效,而且出現需要更多虛擬記憶體的作業還需要修改配置,這樣的方式不靈活;
2、在作業啟動時動態配置mapreduce.map.memory.mb或 mapreduce.reduce.memory.mb的大小,Map和Reduce的虛擬記憶體大小是根據這兩個配置進行取值的。或者修改mapred-site.xml配置檔案中這兩個值,如果沒有增加即可。具體Hadoop2作業的相關記憶體引數要如何配置,可以參考:http://blog.chinaunix.net/uid-28311809-id-4383551.html 和http://dongxicheng.org/mapreduce-nextgen/hadoop-yarn-configurations-resourcemanager-nodemanager/。
Container … is running beyond physical memory limits
具體報錯如下:
Container … is running beyond physical memory limits. Current usage: 2.5 GB of 2.5 GB physical memory used; 3.1 GB of 12.5 GB virtual memory used. Killing container.
意思是實體記憶體不足,修改方法與上一個錯誤第2個解決方式類似,增加mapreduce.map.memory.mb或 mapreduce.reduce.memory.mb的大小。
java.lang.OutOfMemoryError: Java heap space
具體報錯如下:
org.apache.hadoop.mapred.YarnChild: Error running child : java.lang.OutOfMemoryError: Java heap space
這個錯誤可能是MapReduce的演算法不當,導致的OOM,首先先檢查演算法是否可以優化。如果無法優化,則根據具體情況修改配置或在提交作業時動態指定相應配置,有如下三種方法:
1、修改mapred-site.xml配置檔案,修改mapreduce.map.java.opts或mapreduce.reduce.java.opts,增加map或reduce的JVM最大可用記憶體;
2、在程式中設定
configuration.set("mapreduce.map.java.opts", "-Xmx1024m")這裡1024只是例子;
以上兩種方式不推薦,靈活性不好。
3、在提交作業時動態指定mapreduce.map.java.opts或mapreduce.reduce.java.opts的值。
推薦第三種解決方式。
不關閉防火牆的情況下提交作業失敗
由於Hadoop Yarn把資源管理功能和作業排程功能分離開了,例如MapReduce的作業排程由MRApplicationMaster進行管理,而MRApplicationMaster的啟動是在從機器上進行的,如果防火牆沒有關閉,MRApplicationMaster啟動就會失敗(通訊埠沒有開啟)。但MRApplicationMaster啟動的埠是隨機的,因此我目前的解決辦法是開啟一個範圍埠,如下所示:
-A INPUT -p tcp -m tcp –dport 10000:65535 -j ACCEPT
目前沒有找到太好的解決辦法,但總覺得比關閉防火牆好一些。如果有哪位大神解決了這個問題,希望能告知我,不甚感激。
containner日誌報錯找不到類方法
有些情況下, 我們編寫的MapReduce使用的jar包與Hadoop本身依賴的jar包版本不一致,導致使用某些方法時報錯找不到該方法。原因是MapReduce作業會直接使用Hadoop本身依賴的jar包。如果想使用自己的jar包,
在configuration中設定:
conf.setBoolean(MRJobConfig.MAPREDUCE_JOB_USER_CLASSPATH_FIRST, true); // 設定mapreduce優先使用使用者classpath提交作業指定-D、-libjars等常規選項失敗
我在提交MapReduce作業時,設定瞭如下配置 -D mapreduce.map.java.opts=-Xmx2560m,但在作業執行時讀取該配置確實Hadoop預設的配置,也就是說我設定失敗了。在網上查詢答案未果。於是對原始碼進行了Debug,發現需要滿足以下兩個條件,才能動態配置成功:
1、需要main函式所在的類繼承Configured類並實現Tool介面,或者使用如下程式碼獲取Configuration:
Configuration conf = new Configuration();
String[] otherArgs = new GenericOptionsParser(conf, args).getRemainingArgs();這條是我通過看官方文件和一個同學的部落格看到的(忘記出處了。。對不起)
2、需要將配置的常規選項放在全部引數的前面,例如:
hadoop jar hadoop-addCeilingFloor-1.0.0.jar -D mapreduce.map.java.opts=-Xmx2560m -D mapreduce.map.memory.mb=3072 -input …… -output ……
只有同時滿足上述兩個條件,才能動態配置成功。
以後如果有新的問題會再繼續更新。