
推薦系統綜述:初識推薦系統
目錄
1. 引言
隨著資訊科技和網際網路技術的發展,人們從資訊匱乏時代步入了資訊過載時代,在這種時代背景下,人們越來越難從大量的資訊中找到自身感興趣的資訊,資訊也越來越難展示給可能對它感興趣的使用者,而推薦系統的任務就是連線使用者和資訊,創造價值。
設想使用者想買一本《Recommender Systems An Introduction》,使用者只需要走進一家書店,尋找這本書即可。通過網際網路,使用者可以開啟噹噹,在搜尋框中輸入書名,然後就可以找到使用者想要購買的書籍,這兩種方式都需要使用者有明確的目的,如購買《Recommender Systems An Introduction》或某一類別的書籍。
但是,當用戶沒有明確目標時,比如尋找感興趣的音樂,使用者只能通過一些預先設定的類別或標籤去尋找他可能感興趣的音樂,但面對如此之多音樂,使用者很難在短時間內找出真正感興趣的音樂。這時就需要一個自動化的工具,來分析使用者曾經收聽的音樂,進而尋找出使用者可能感興趣的音樂推薦給使用者,這就是個性化推薦系統的工作。
作為一種資訊過濾系統,推薦系統具有以下兩個最顯著的特性:
(1)主動化。從使用者角度考慮,入口網站和搜尋引擎都是解決資訊過載的有效方式,但它們都需要使用者提供明確需求,當用戶無法準確描述自己的需求時,這兩種方式就無法為使用者提供精確的服務了。而推薦系統不需要使用者提供明確的需求,而是通過分析使用者和物品的資料,對使用者和物品進行建模,從而主動為使用者推薦他們感興趣的資訊。
(2)個性化。推薦系統能夠更好的發掘長尾資訊,即將冷門物品推薦給使用者。熱門物品通常代表絕大多數使用者的興趣,而冷門物品往往代表一小部分使用者的個性化需求,在電商平臺火熱的時代,由冷門物品帶來的營業額甚至超過熱門物品,發掘長尾資訊是推薦系統的重要研究方向。
目前,推薦系統已廣泛應用於諸多領域,其中最典型的便是電子商務領域。同時,伴隨著機器學習、深度學習的發展,工業界和學術界對推薦系統的研究熱情更加高漲,形成了一門獨立的學科。
2. 發展歷史
推薦系統是網際網路時代的一種資訊檢索工具,自上世紀90年代起,人們便認識到了推薦系統的價值,經過了二十多年的積累和沉澱,推薦系統逐漸成為一門獨立的學科在學術研究和業界應用中都取得了很多成果。
1994 年明尼蘇達大學GroupLens研究組推出第一個自動化推薦系統 GroupLens[1]。提出了將協同過濾作為推薦系統的重要技術,這也是最早的自動化協同過濾推薦系統之一。
1997 年 Resnick 等人[2]首次提出推薦系統(recommendersystem,RS)一詞,自此,推薦系統一詞被廣泛引用,並且推薦系統開始成為一個重要的研究領域。
1998年亞馬遜(Amazon.com)上線了基於物品的協同過濾演算法,將推薦系統推向服務千萬級使用者和處理百萬級商品的規模,並能產生質量良好的推薦。
2003年亞馬遜的Linden等人發表論文,公佈了基於物品的協同過濾演算法[3],據統計推薦系統的貢獻率在20%~30%之間[4]。
2005年Adomavicius 等人的綜述論文[5] 將推薦系統分為3個主要類別,即基於內容的推薦、基於協同過濾的推薦和混合推薦的方法,並提出了未來可能的主要研究方向。
2006 年10月,北美線上視訊服務提供商 Netflix 宣佈了一項競賽,任何人只要能夠將它現有電影推薦演算法 Cinematch 的預測準確度提高10%,就能獲得100萬美元的獎金。該比賽在學術界和工業界引起了較大的關注,參賽者提出了若干推薦演算法,提高推薦準確度,極大地推動了推薦系統的發展。
2007年第一屆ACM 推薦系統大會在美國舉行,到2017年已經是第11屆。這是推薦系統領域的頂級會議,提供了一個重要的國際論壇來展示推薦系統在不同領域的最近研究成果、系統和方法。
2016年,YouTube發表論文[6],將深度神經網路應用推薦系統中,實現了從大規模可選的推薦內容中找到最有可能的推薦結果。
近年來,推薦系統被廣泛的應用於電子商務推薦、個性化廣告推薦、新聞推薦等諸多領域,如人們經常使用的淘寶、今日頭條、豆瓣影評等產品。
3. 研究現狀
經過二十多年的積累和沉澱,推薦系統成功應用到了諸多領域,RecSys會議上最常提及的應用落地場景為:線上視訊、社交網路、線上音樂、電子商務、網際網路廣告等,這些領域是推薦系統大展身手的舞臺,也是近年來業界研究和應用推薦系統的重要實驗場景。
伴隨著推薦系統的發展,人們不僅僅滿足於分析使用者的歷史行為對使用者進行建模,轉而研究混合推薦模型,致力於通過不同的推薦方法來解決冷啟動、資料極度稀疏等問題,國內知名新聞客戶端今日頭條採用了內容分析、使用者標籤、評估分析等方法打造了擁有上億使用者的推薦引擎。
移動網際網路的崛起為推薦系統提供了更多的資料,如移動電商資料[6]、移動社交資料、地理資料[7]等,成為了社交推薦的新的嘗試。
隨著推薦系統的成功應用,人們越來越多的關注推薦系統的效果評估和演算法的健壯性、安全性等問題。2015年,Alan Said 等人在RecSys會議上發表論[8],闡述了一種清晰明瞭的推薦結果評價方式,同年,FrankHopfgartner等人發表論文[9],討論了基於流式資料的離線評價方式和對照試驗,掀起了推薦演算法評估的研究熱潮。
近年來,機器學習和深度學習等領域的發展,為推薦系統提供了方法指導。RecSys會議自2016年起開始舉辦定期的推薦系統深度學習研討會,旨在促進研究和鼓勵基於深度學習的推薦系統的應用。
2017年AlexandrosKaratzoglou等人在論文[10]中介紹了深度學習在推薦系統中的應用,描述了基於深度學習的內容推薦和協同過濾推薦方法,深度學習成為當前推薦系統研究的熱點。
4. 推薦方式和效果評估
推薦系統在為使用者推薦物品時通常有兩種方式:
4.1 評分預測
此方法一般通過學習使用者對物品的歷史評分,預測使用者可能會為他沒有進行評分的物品打多少分,通常用於線上視訊、音樂等服務的推薦。
評分預測的效果評估一般通過均方根誤差(RMSE)和平均絕對誤差(MAE)計算。對於測試集T中的一個使用者u和物品i,令rui是使用者u對物品i的實際評分,而ȓui是推薦系統給出的預測評分,則RMSE定義為:
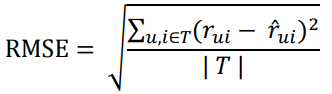
MAE定義為:

4.2 TopN推薦
此方法一般不考慮評分,而是為使用者提供一個個性化推薦列表,通過預測使用者對物品的興趣度對列表進行排序,選取其中前N個物品推薦給使用者,通常用於電子商務、社交網路、網際網路廣告推薦。
TopN推薦一般通過準確率(precision)、召回率(recall)和F1值(平衡分數)度量。令R(u)是為使用者推薦的物品列表,T(u)是使用者在測試集上的行為列表。
召回率定義為:

準確率定義為:

F1值定義為:

5. 推薦演算法
根據推薦系統使用資料的不同,推薦演算法可分為基於使用者行為推薦、基於內容推薦、基於社交網路推薦等。
主流的推薦系統演算法可以分為協同過濾推薦(Collaborative Filtering Recommendation)、基於內容推薦(Content-basedRecommendation)和混合推薦三種。
5.1 基於使用者行為推薦
使用者行為蘊藏著很多模式,著名的“啤酒和尿布”的故事就是使用者行為模式的良好體現。基於使用者行為推薦的主要思想是利用已有使用者的歷史行為資料(顯式反饋或隱式反饋),預測當前使用者可能感興趣的物品,其中顯式反饋主要為使用者評分,隱式反饋主要包括瀏覽、搜尋等。
基於使用者行為的推薦演算法也稱為協同過濾演算法(Collaborative Filtering Recommendation),是推薦領域應用最廣泛的演算法,該演算法不需要預先獲得使用者或物品的特徵資料,僅依賴於使用者的歷史行為資料對使用者進行建模,從而為使用者進行推薦。協同過濾演算法主要包括基於使用者的協同過濾(User-Based CF)、基於物品的協同過濾(Item-Based CF)、隱語義模型(Latent Factor Model)等。其中基於使用者和物品的協同過濾是通過統計學方法對資料進行分析的,因此也稱為基於記憶體的協同過濾或基於鄰域的協同過濾;隱語義模型是採用機器學習等演算法,通過學習資料得出模型,然後根據模型進行預測和推薦,是基於模型的協同過濾。
5.1.1 基於使用者的協同過濾(User-Based CF)
基於使用者的協同過濾(下文簡稱UserCF)的基本思想為:給使用者推薦和他興趣相似的使用者感興趣的物品。當需要為一個使用者A(下文稱A)進行推薦時,首先,找到和A興趣相似的使用者集合(用U表示),然後,把集合U中使用者感興趣而A沒有聽說過(未進行過操作)的物品推薦給A。演算法分為兩個步驟:首先,計算使用者之間的相似度,選取最相似的N個使用者,然後,根據相似度計算使用者評分。
(1)使用者相似度
使用者相似度計算基於使用者的協同過濾演算法的重要內容,主要可以通過餘弦相似度、傑卡德係數等方式進行計算。
假設:給定使用者u和v,令N(u)表示使用者u有過正反饋的物品集合,令N(v)為使用者v有過正反饋的物品集合,則使用者u和v之間的相似度可以通過如下方式計算:
餘弦相似度:

傑卡德係數:

(2)使用者評分
得到使用者相似度後,可以根據如下公式計算使用者評分:

其中r(u, i)代表使用者u對物品i的評分,S(u)為與使用者u最相似的N個使用者,N(i)為對物品i進行過操作的使用者集合, 為使用者u與使用者v的相似度, 為使用者v對物品i的評分。
UserCF的推薦結果反映了使用者所在的一個興趣群體中的熱門物品,更加社會化但缺乏個性化, 能夠滿足物品的時效性,在新聞推薦領域能夠發揮很大的作用。使用者的興趣在一段時間內是相對固定的,因此使用者相似度矩陣不會實時進行更新,存在新使用者的冷啟動問題。
5.1.2 基於使用者的協同過濾(User-Based CF)
基於物品的協同過濾(下文簡稱ItemCF)是目前應用最為廣泛的演算法,該演算法的基本思想為:給使用者推薦和他們以前喜歡的物品相似的物品,這裡所說的相似並非從物品的內容角度出發,而是基於一種假設:喜歡物品A的使用者大多也喜歡物品B代表著物品A和物品B相似。基於物品的協同過濾演算法能夠為推薦結果做出合理的解釋,比如電子商務網站中的“購買該物品的使用者還購買了…”。ItemCF的計算步驟和UserCF大致相同:首先,計算物品相似度,選出最相似的N個物品,然後根據相似度計算使用者評分。
(1)物品相似度
假設:N(i)為喜歡物品i的使用者結合,N(j)為喜歡物品j的使用者集合,則物品相似度計算公式可以定義為:

上述公式將物品i和物品j的相似度定義為:同時喜歡物品i、j的使用者數佔只喜歡物品i使用者數的比例,但如果物品j十分熱門,大部分使用者都很喜歡,那麼就會造成所有物品都和j有較高的相似度,因此可以對計算公式進行如下改進:

改進後的相似度計算公式懲罰了物品j的熱門度,在一定程度上減少了熱門物品為相似度帶來的影響。
(2)使用者評分
得到物品相似度後,可以根據如下公式計算使用者評分:

其中r(u, i)代表使用者u對物品i的評分,S(i)代表和物品i最相似的N個物品,N(u)為使用者u曾經感興趣的物品集合, 為物品i和物品j的相似度, 為使用者u對物品i的評分。
ItemCF的推薦結果更加個性化,反映了使用者的個人興趣,對挖掘長尾物品有很大幫助,被廣泛應用於電子商務系統。在物品數較多時,物品相似度計算效率較差,因此通常以一定的時間間隔離線進行計算,然後將物品相似度資料快取在記憶體中,這樣一來,便可以根據使用者的新行為實時向用戶做出推薦。ItemCF同樣存在新使用者冷啟動問題。
5.1.3 隱語義模型(Latent Factor Model)
隱語義模型方法是目前應用最為廣泛的協同過濾演算法之一,在顯式反饋(如評分)推薦系統中,能夠達到很好的精度。它的基本思想是通過機器學習方法從使用者-物品評分矩陣中分解為兩個低階矩陣,表示對使用者興趣和物品的隱含分類特徵,通過隱含特徵預測使用者評分。訓練過程中通常採用隨機梯度下降(SGD)演算法最小化損失函式,最後通過模型預測使用者評分。矩陣分解(Matrix Factorization)是隱語義模型最成功的一種實現,假設訓練資料為M個使用者對N個物品的評分矩陣Rm,n,早期矩陣分解演算法BasicSvd步驟如下:
(1)給定假設函式

其中k表示矩陣分解的隱含特徵數,p和q是兩個矩陣,作為模型的引數,分別表示使用者、物品與k個隱含特徵之間的關係。
(2)最小化損失函式

其中u為使用者,i為物品,R為訓練資料評分矩陣,H為預測評分矩陣,通過隨機梯度下降最小化cost函式,得到矩陣p和q。在最小化的過程中,還需要新增正則項防止過度擬合。
(3)通過使用者、物品和隱含特徵的關係矩陣p、q預測使用者評分。
在演算法的演進過程中,還出現了FunkSVD[11]、SVD++等矩陣分解演算法,它們在隱含特徵的基礎上考慮了使用者評分習慣、歷史訪問等多種因素,在一些場景中取得了更為精確的結果。
矩陣分解演算法採用機器學習的最優化方法訓練模型,計算的空間複雜度較小,在評分預測推薦中的精度較高,能夠自動挖掘使用者和物品的特徵,有非常好的擴充套件性,可以靈活地考慮額外因素。矩陣分解的訓練過程需要掃描整個評分矩陣,在使用者量和物品數很大的情況下比較費時,但可以離線進行訓練,線上進行評分預測,達到推薦的實時性。
5.2 基於內容推薦
基於內容推薦的基本思想是為使用者推薦與他感興趣的內容相似的物品,比如使用者喜歡勵志類電影,那麼系統會直接為他推薦《阿甘正傳》這部電影,這個過程綜合考慮了使用者興趣和電影內容,因此不需要提供使用者的歷史行為資料,這能夠很好地解決新使用者的冷啟動問題。基於內容推薦的關鍵問題是對使用者興趣特徵和物品特徵進行建模,主要方法由向量空間模型、線性分類、線性迴歸等。
基於內容推薦需要預先提供使用者和物品的特徵資料,比如電影推薦系統,需要提供使用者感興趣的電影類別、演員、導演等資料作為使用者特徵,還需要提供電影的內容屬性、演員、導演、時長等資料作為電影的特徵,這些需要進行預處理的資料在實際應用中往往有很大的困難,尤其是多媒體資料(視訊、音訊、影象等),在預處理過程中很難對物品的內容進行準確的分類和描述,且在資料量很大的情況下,預處理效率會很低下。針對以上不足,[25]提出了基於標籤的推薦方法,可以由專家或使用者為物品打標籤,實現對物品的分類。
基於內容產生的推薦往往和使用者已經處理的物品具有很大的相似度,不利於使用者在推薦系統中獲得驚喜,這也是推薦系統的一個重要研究方向。
5.3 混合推薦
推薦演算法雖然都可以為使用者進行推薦,但每一種演算法在應用中都有不同的效果。UserCF的推薦結果能夠很好的在廣泛的興趣範圍中推薦出熱門的物品,但卻缺少個性化;ItemCF能夠在使用者個人的興趣領域發掘出長尾物品,但卻缺乏多樣性;基於內容推薦依賴於使用者特徵和物品特徵,但能夠很好的解決使用者行為資料稀疏和新使用者的冷啟動問題;矩陣分解能夠自動挖掘使用者特徵和物品特徵,但卻缺乏對推薦結果的解釋,因此,每種推薦方法都各有利弊,相輔相成。
實際應用的推薦系統通常都會使用多種推薦演算法,比如使用基於內容或標籤的推薦演算法來解決新使用者的冷啟動問題和行為資料稀疏問題,在擁有了一定的使用者行為資料後,根據業務場景的需要綜合使用UserCF、ItemCF、矩陣分解或其他推薦演算法進行離線計算和模型訓練,通過採集使用者的社交網路資料、時間相關資料、地理資料等綜合考慮進行推薦,保證推薦引擎的個性化,提高推薦引擎的健壯性、實時性、多樣性和新穎性。讓推薦系統更好地為使用者服務。
6. 總結和展望
本文首先回顧了推薦系統發展的歷史,並分析了當前推薦系統的研究現狀,其次闡述了主要的推薦方式和推薦結果的評估指標,最後分析了主流的推薦演算法以及它們各自的優缺點。
推薦系統的發展一方面精確的匹配了使用者與資訊,降低了人們在資訊過載時代獲取資訊的成本,但由推薦系統主導的內容分發,如新聞推薦等,也為使用者帶來了消極影響。2017年9月19日,人民日報點名批評國內知名內容分發平臺今日頭條,強調別以技術之名糊弄網民和群眾,可見推薦系統的發展不僅需要滿足使用者多元化、個性化的需求,而且需要對資訊進行嚴格的監管和過濾,提高推薦系統的健壯性。近年來,RecSys會議上越來越多地收錄了關於使用者隱私、推薦引擎健壯性、資訊過濾等方面的論文,這是未來推薦系統發展的一個重要研究方向。
目前,深度神經網路發展迅速,為推薦系統提供了新的特徵提取、排序方法,越來越多的推薦引擎將深度神經網路與傳統的推薦演算法進行了結合,用於解決資料稀疏、推薦排序等問題,深度神經網路和推薦系統的結合將是推薦系統未來的主要研究方向。
綜上所述,推薦系統是一個龐大的資訊系統,它不僅僅只依賴於推薦引擎的工作,而且依賴於業務系統、日誌系統等諸多方面,並結合了網路安全、資料探勘等多個研究領域,能夠為企業和使用者帶來價值,是一個值得深入研究的領域。
參考文獻
[1] Resnick P,Iacovou N, Suchak M, et al. GroupLens: an open architecture for collaborativefiltering of netnews[C] Proceedings of the 1994 ACM Conference on ComputerSupported Cooperative Work, Oct 22-26, 1994. New York, NY, USA: ACM, 1994:175-186.
[2] Resnick P, Varian H R. Recommender systems[J].Communications of the ACM, 1997, 40(3): 56-58.
[3] G. Linden, B. Smith, and J. York, “Amazon.comRecommendations: Item-to-Item Collaborative Filtering,” IEEE InternetComputing, vol. 7, no. 1, 2003, pp. 76–80.
[4] Linden G, Smith B, York J. Amazon.comrecommendations: item-to-item collaborative filtering[J]. IEEE Internet Computing,2003, 7(1): 76-80.
[5] Adomavicius G, Tuzhilin A. Toward the nextgeneration of recommender systems: a survey of the state-of-the-art and possibleextensions[J]. IEEE Transactions on Knowledge and Data Engineering, 2005,17(6): 734-749.
[6] Cremonesi P, Tripodi A, Turrin R. Cross-DomainRecommender Systems.[C] IEEE, International Conference on Data MiningWorkshops. IEEE, 2012:496-503.
[7] Huiji Gao, Jiliang Tang, Huan Liu. Personalizedlocation recommendation on location-based social networks[J]. 2014:399-400.
[8] Said A. Replicable Evaluation of RecommenderSystems[C] ACM Conference on Recommender Systems. ACM, 2015:363-364.
[9] Hopfgartner F, Kille B, Heintz T, et al.Real-time Recommendation of Streamed Data[C] ACM Conference on RecommenderSystems. ACM, 2015:361-362.
[10] Karatzoglou A, Hidasi B. Deep Learning forRecommender Systems[C] the Eleventh ACM Conference. ACM, 2017:396-397.
[11] Simon Funk. Funk-SVD [EB/OL]. http://sifter.org/~simon/journal/20061211.html,2006-12-11
[12] 朱揚勇, 孫婧. 推薦系統研究進展[J]. 電腦科學與探索, 2015, 9(5):513-525.
[13] 楊陽, 向陽, 熊磊. 基於矩陣分解與使用者近鄰模型的協同過濾推薦演算法[J]. 計算機應用, 2012,32(2):395-398.
[14] 項亮. 推薦系統實踐[M]. 北京: 人民郵電出版社, 2012.