
初識推薦系統
阿新 • • 發佈:2018-06-03
評論 lB 嘗試 背景 智能 sci dia 而且 叠代
本文摘錄了大量 機器學習算法原理與編程實踐_鄭捷著_電子工業出版社 的原文。
源碼:機器學習算法原理與編程實踐
wiki
推薦系統是一種信息過濾系統,用於預測用戶對物品的「評分」或「偏好」。
精彩推薦:
- 《推薦系統實戰》- 筆記與思考
- Surprise——Python的推薦系統庫(1)
存在問題(背景)
- 關鍵詞的信息量不足,基於關鍵詞的檢索在很多情況下不能精準和深刻地反映用戶的潛在需求;
- 通用的搜索引擎只有而且必須對用戶提供盡量豐富而無差別的信息,這樣才能應對不同種類的需求,以及需求的變換。
因此,如何平衡搜索的廣度與深度(精準程度)是推薦系統所要解決的主要問題。
推薦系統著眼於需求二字:
- 需求的定位;
- 需求的個性化;
- 需求的模糊性衍生。
推薦系統的應用
- 把包銷售:經常一起購買的產品;
- 協同過濾:購買了此產品的顧客同時也購買的產品;(除了促銷之外,也可以幫助用戶定位購買需求)
- 用戶的商品評論列表。
推薦系統通過研究用戶的興趣偏好,由智能算法進行個性化的計算,發現用戶的潛在興趣點,從而引導用戶發現需求。
推薦系統的架構
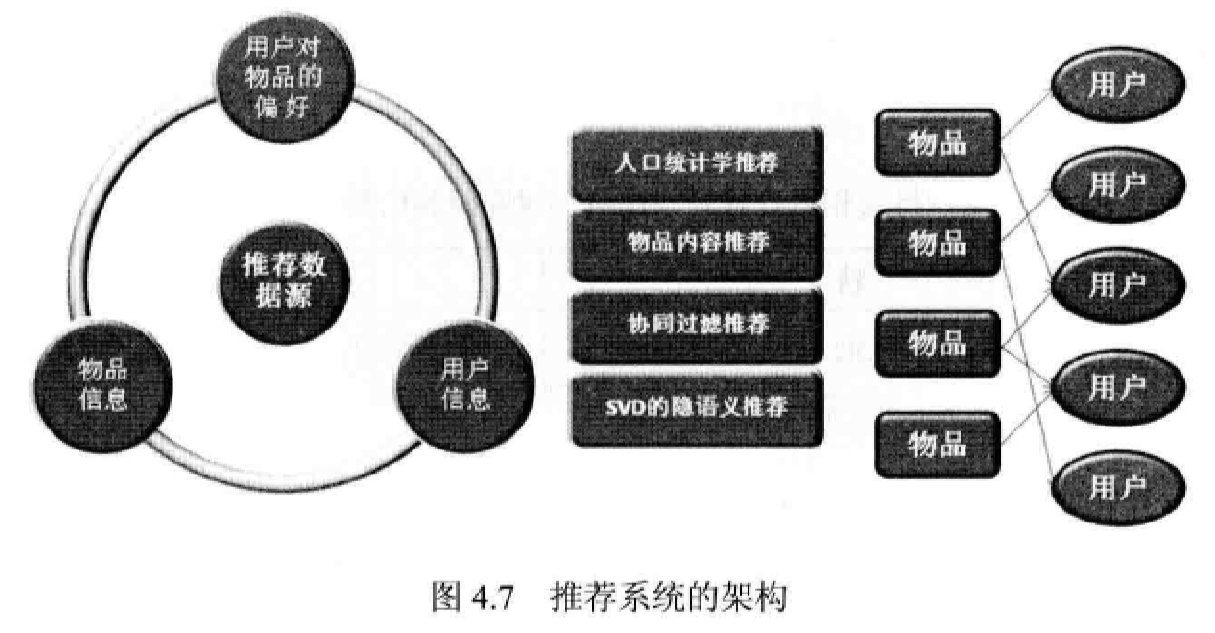


前兩種方法較為簡單,應用也不廣泛。
協同過濾(Collaborative Filtering,CF)
推薦模型:
- 基於用戶的推薦技術:找到具有相似品味的人所喜歡的物品——User CF;
- 基於物品的推薦技術:從一個人喜歡的物品中找出相似的物品——Item CF。
數據預處理
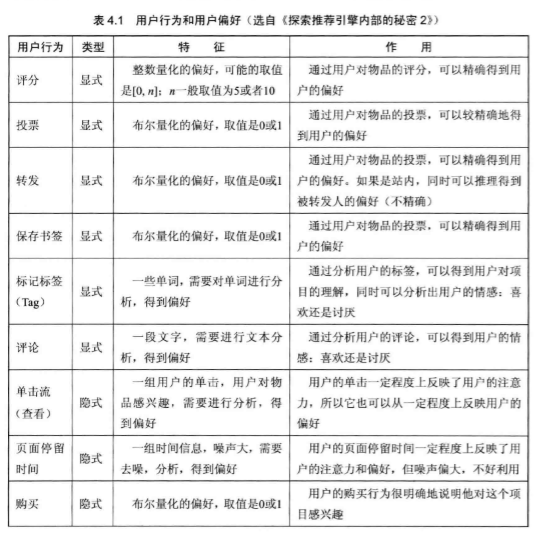
預處理策略:
- 減噪
- 歸一化
- 聚類(縮減計算量)
使用 Scikit-Learn 的 KMeans 聚類
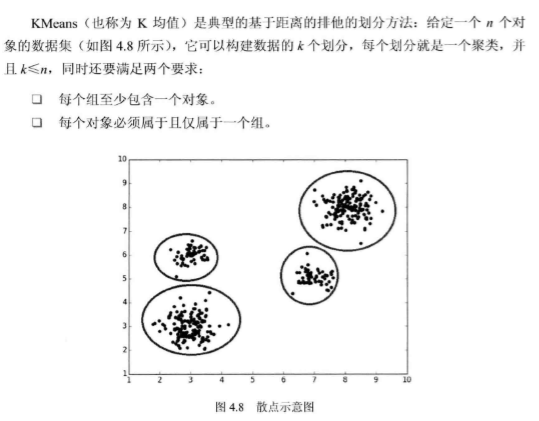
KMeans 的基本原理
給定要劃分的數目 \(k\):
- 首先創建一個初始劃分,隨機選擇 \(k\) 個對象,每個對象初始地代表了一個聚類中心。對於其他對象,根據其與各個聚類中心的距離,將它們賦給最近的簇。
- 然後采用一種叠代的重定位技術,嘗試通過對象在劃分的簇之間移動來改進劃分,直到聚類中心不發生變化為止。
- 重定位技術:就是當有新的對象加入到簇中或已有對象離開簇時,重新計算聚類的平均值(作為聚類中心),然後對對象進行重新分配。
初識推薦系統