
基於深度學習的目標檢測技術演進:從目標檢測到人臉檢測
本篇部落格主要轉載兩篇寫得好的分別介紹基於深度學習的目標檢測和人臉檢測的文章,最近在調研基於深度學習的人臉檢測相關的文章,在網上查相關資料時,有幸看到。文末附帶基於深度學習的目標檢測和人臉檢測相關經典文獻及下載地址。
object detection我的理解,就是在給定的圖片中精確找到物體所在位置,並標註出物體的類別。object detection要解決的問題就是物體在哪裡,是什麼這整個流程的問題。然而,這個問題可不是那麼容易解決的,物體的尺寸變化範圍很大,擺放物體的角度,姿態不定,而且可以出現在圖片的任何地方,更何況物體還可以是多個類別。
object detection技術的演進:
RCNN->SppNET->Fast-RCNN->Faster-RCNN
從影象識別的任務說起
這裡有一個影象任務:
既要把圖中的物體識別出來,又要用方框框出它的位置。
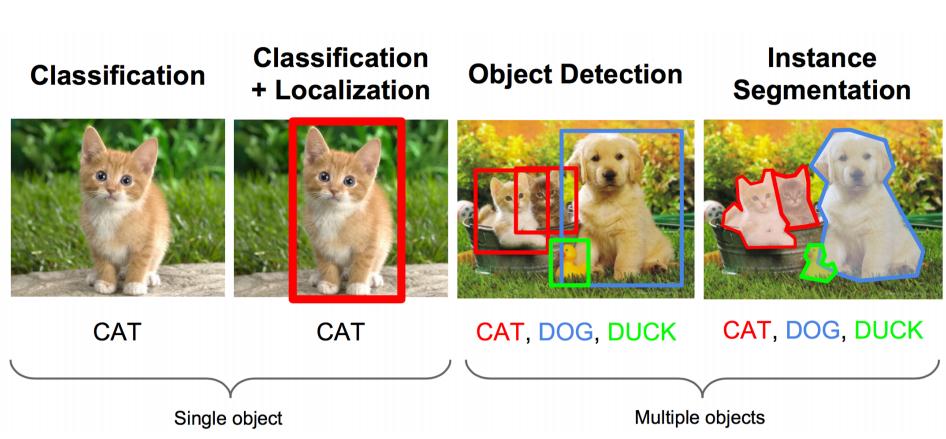
上面的任務用專業的說法就是:影象識別+定位
影象識別(classification):
輸入:圖片
輸出:物體的類別
評估方法:準確率

定位(localization):
輸入:圖片
輸出:方框在圖片中的位置(x,y,w,h)
評估方法:檢測評價函式 intersection-over-union ( IOU )
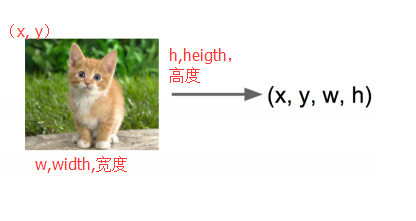
卷積神經網路CNN已經幫我們完成了影象識別(判定是貓還是狗)的任務了,我們只需要新增一些額外的功能來完成定位任務即可。
定位的問題的解決思路有哪些?
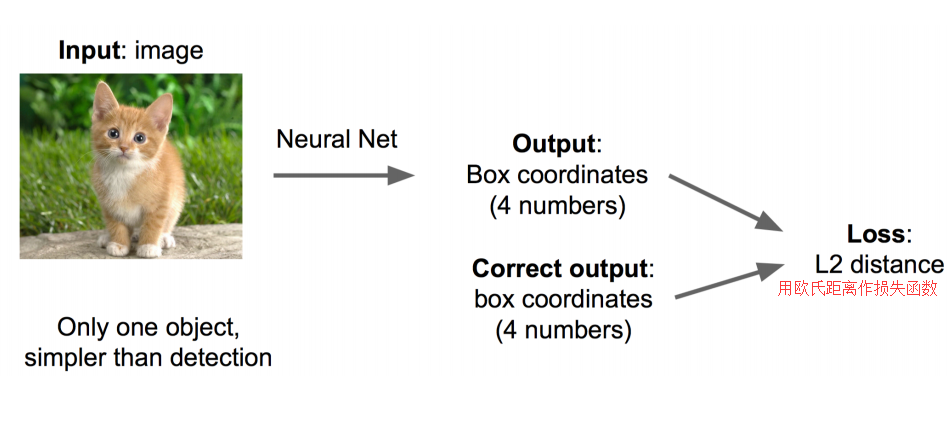
思路一:看做迴歸問題
看做迴歸問題,我們需要預測出(x,y,w,h)四個引數的值,從而得出方框的位置。
步驟1:
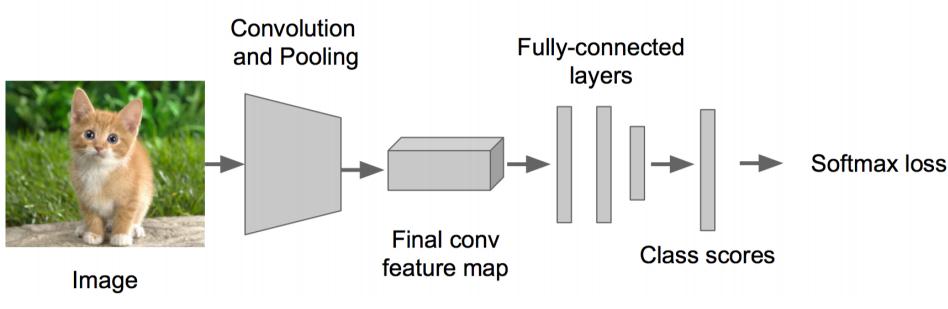
• 先解決簡單問題, 搭一個識別影象的神經網路
• 在AlexNet VGG GoogleLenet上fine-tuning一下
步驟2:
• 在上述神經網路的尾部展開(也就說CNN前面保持不變,我們對CNN的結尾處作出改進:加了兩個頭:“分類頭”和“迴歸頭”)
• 成為classification + regression模式
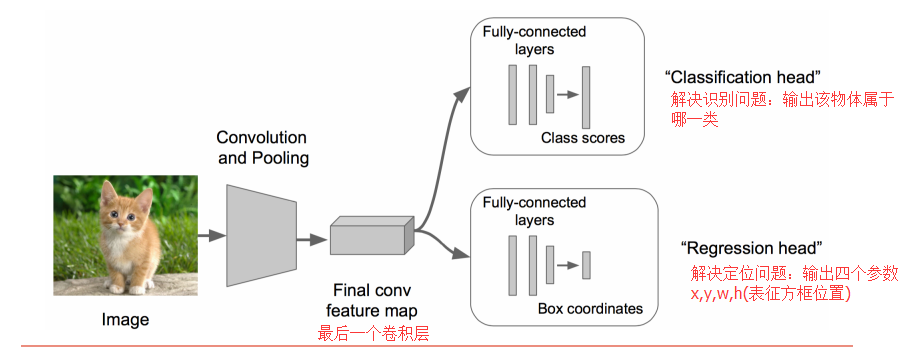
步驟3:
• Regression那個部分用歐氏距離損失
• 使用SGD訓練
步驟4:
• 預測階段把2個頭部拼上
• 完成不同的功能
這裡需要進行兩次fine-tuning
第一次在ALexNet上做,第二次將頭部改成regression head,前面不變,做一次fine-tuning
Regression的部分加在哪?
有兩種處理方法:
• 加在最後一個卷積層後面(如VGG)
• 加在最後一個全連線層後面(如R-CNN)
regression太難做了,應想方設法轉換為classification問題。
regression的訓練引數收斂的時間要長得多,所以上面的網路採取了用classification的網路來計算出網路共同部分的連線權值。
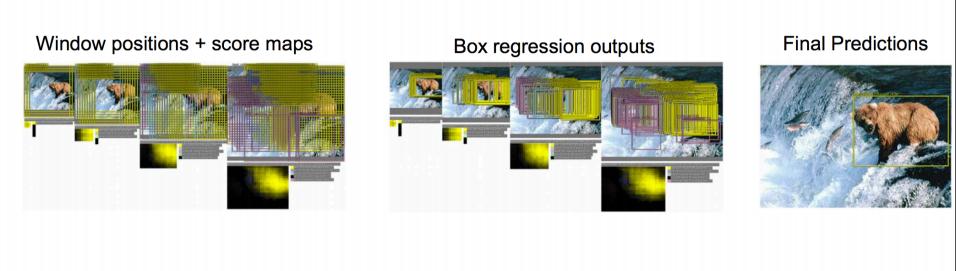
思路二:取影象視窗
• 還是剛才的classification + regression思路
• 咱們取不同的大小的“框”
• 讓框出現在不同的位置,得出這個框的判定得分
• 取得分最高的那個框
左上角的黑框:得分0.5

右上角的黑框:得分0.75

左下角的黑框:得分0.6

右下角的黑框:得分0.8

根據得分的高低,我們選擇了右下角的黑框作為目標位置的預測。
注:有的時候也會選擇得分最高的兩個框,然後取兩框的交集作為最終的位置預測。
疑惑:框要取多大?
取不同的框,依次從左上角掃到右下角。非常粗暴啊。
總結一下思路:
對一張圖片,用各種大小的框(遍歷整張圖片)將圖片截取出來,輸入到CNN,然後CNN會輸出這個框的得分(classification)以及這個框圖片對應的x,y,h,w(regression)。
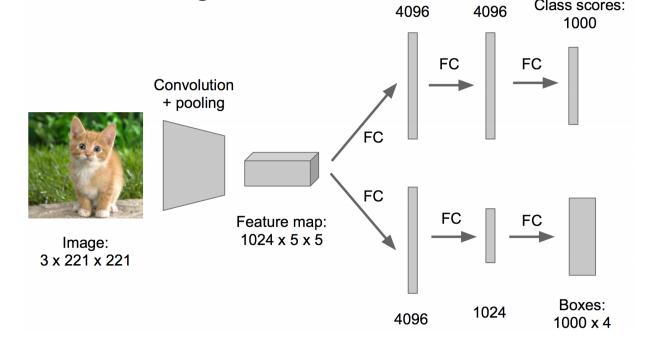
這方法實在太耗時間了,做個優化。
原來網路是這樣的:
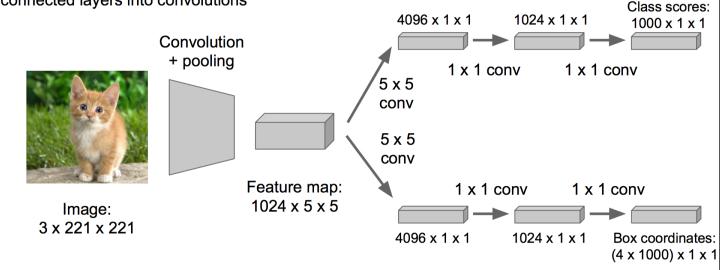
優化成這樣:把全連線層改為卷積層,這樣可以提提速。
物體檢測(Object Detection)
當影象有很多物體怎麼辦的?難度可是一下暴增啊。
那任務就變成了:多物體識別+定位多個物體
那把這個任務看做分類問題?

看成分類問題有何不妥?
• 你需要找很多位置, 給很多個不同大小的框
• 你還需要對框內的影象分類
• 當然, 如果你的GPU很強大, 恩, 那加油做吧…
看做classification, 有沒有辦法優化下?我可不想試那麼多框那麼多位置啊!
有人想到一個好方法:
找出可能含有物體的框(也就是候選框,比如選1000個候選框),這些框之間是可以互相重疊互相包含的,這樣我們就可以避免暴力列舉的所有框了。

大牛們發明好多選定候選框的方法,比如EdgeBoxes和Selective Search。
以下是各種選定候選框的方法的效能對比。
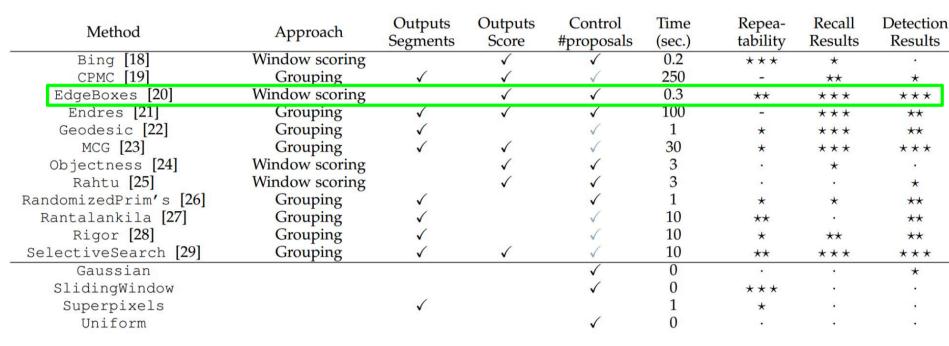
有一個很大的疑惑,提取候選框用到的演算法“選擇性搜尋”到底怎麼選出這些候選框的呢?那個就得好好看看它的論文了,這裡就不介紹了。
R-CNN橫空出世
基於以上的思路,RCNN出現了。

步驟一:訓練(或者下載)一個分類模型(比如AlexNet)

步驟二:對該模型做fine-tuning
• 將分類數從1000改為20
• 去掉最後一個全連線層

步驟三:特徵提取
• 提取影象的所有候選框(選擇性搜尋)
• 對於每一個區域:修正區域大小以適合CNN的輸入,做一次前向運算,將第五個池化層的輸出(就是對候選框提取到的特徵)存到硬碟

步驟四:訓練一個SVM分類器(二分類)來判斷這個候選框裡物體的類別
每個類別對應一個SVM,判斷是不是屬於這個類別,是就是positive,反之nagative
比如下圖,就是狗分類的SVM

步驟五:使用迴歸器精細修正候選框位置:對於每一個類,訓練一個線性迴歸模型去判定這個框是否框得完美。

RCNN的進化中SPP Net的思想對其貢獻很大,這裡也簡單介紹一下SPP Net。
SPP Net
SPP:Spatial Pyramid Pooling(空間金字塔池化)
它的特點有兩個:
1.結合空間金字塔方法實現CNNs的對尺度輸入。
一般CNN後接全連線層或者分類器,他們都需要固定的輸入尺寸,因此不得不對輸入資料進行crop或者warp,這些預處理會造成資料的丟失或幾何的失真。SPP Net的第一個貢獻就是將金字塔思想加入到CNN,實現了資料的多尺度輸入。
如下圖所示,在卷積層和全連線層之間加入了SPP layer。此時網路的輸入可以是任意尺度的,在SPP layer中每一個pooling的filter會根據輸入調整大小,而SPP的輸出尺度始終是固定的。

2.只對原圖提取一次卷積特徵
在R-CNN中,每個候選框先resize到統一大小,然後分別作為CNN的輸入,這樣是很低效的。
所以SPP Net根據這個缺點做了優化:只對原圖進行一次卷積得到整張圖的feature map,然後找到每個候選框在feature map上的對映patch,將此patch作為每個候選框的卷積特徵輸入到SPP layer和之後的層。節省了大量的計算時間,比R-CNN有一百倍左右的提速。

Fast R-CNN
SPP Net真是個好方法,R-CNN的進階版Fast R-CNN就是在RCNN的基礎上採納了SPP Net方法,對RCNN作了改進,使得效能進一步提高。
R-CNN與Fast RCNN的區別有哪些呢?
先說RCNN的缺點:即使使用了selective search等預處理步驟來提取潛在的bounding box作為輸入,但是RCNN仍會有嚴重的速度瓶頸,原因也很明顯,就是計算機對所有region進行特徵提取時會有重複計算,Fast-RCNN正是為了解決這個問題誕生的。

大牛提出了一個可以看做單層sppnet的網路層,叫做ROI Pooling,這個網路層可以把不同大小的輸入對映到一個固定尺度的特徵向量,而我們知道,conv、pooling、relu等操作都不需要固定size的輸入,因此,在原始圖片上執行這些操作後,雖然輸入圖片size不同導致得到的feature map尺寸也不同,不能直接接到一個全連線層進行分類,但是可以加入這個神奇的ROI Pooling層,對每個region都提取一個固定維度的特徵表示,再通過正常的softmax進行型別識別。另外,之前RCNN的處理流程是先提proposal,然後CNN提取特徵,之後用SVM分類器,最後再做bbox regression,而在Fast-RCNN中,作者巧妙的把bbox regression放進了神經網路內部,與region分類和併成為了一個multi-task模型,實際實驗也證明,這兩個任務能夠共享卷積特徵,並相互促進。Fast-RCNN很重要的一個貢獻是成功的讓人們看到了Region Proposal+CNN這一框架實時檢測的希望,原來多類檢測真的可以在保證準確率的同時提升處理速度,也為後來的Faster-RCNN做下了鋪墊。
畫一畫重點:
R-CNN有一些相當大的缺點(把這些缺點都改掉了,就成了Fast R-CNN)。
大缺點:由於每一個候選框都要獨自經過CNN,這使得花費的時間非常多。
解決:共享卷積層,現在不是每一個候選框都當做輸入進入CNN了,而是輸入一張完整的圖片,在第五個卷積層再得到每個候選框的特徵
原來的方法:許多候選框(比如兩千個)–>CNN–>得到每個候選框的特徵–>分類+迴歸
現在的方法:一張完整圖片–>CNN–>得到每張候選框的特徵–>分類+迴歸
所以容易看見,Fast RCNN相對於RCNN的提速原因就在於:不過不像RCNN把每個候選區域給深度網路提特徵,而是整張圖提一次特徵,再把候選框對映到conv5上,而SPP只需要計算一次特徵,剩下的只需要在conv5層上操作就可以了。
在效能上提升也是相當明顯的:

Faster R-CNN
Fast R-CNN存在的問題:存在瓶頸:選擇性搜尋,找出所有的候選框,這個也非常耗時。那我們能不能找出一個更加高效的方法來求出這些候選框呢?
解決:加入一個提取邊緣的神經網路,也就說找到候選框的工作也交給神經網路來做了。
做這樣的任務的神經網路叫做Region Proposal Network(RPN)。
具體做法:
• 將RPN放在最後一個卷積層的後面
• RPN直接訓練得到候選區域

RPN簡介:
• 在feature map上滑動視窗
• 建一個神經網路用於物體分類+框位置的迴歸
• 滑動視窗的位置提供了物體的大體位置資訊
• 框的迴歸提供了框更精確的位置

一種網路,四個損失函式;
• RPN calssification(anchor good.bad)
• RPN regression(anchor->propoasal)
• Fast R-CNN classification(over classes)
• Fast R-CNN regression(proposal ->box)

速度對比

Faster R-CNN的主要貢獻是設計了提取候選區域的網路RPN,代替了費時的選擇性搜尋,使得檢測速度大幅提高。
最後總結一下各大演算法的步驟:
RCNN
1. 在影象中確定約1000-2000個候選框 (使用選擇性搜尋)
2. 每個候選框內影象塊縮放至相同大小,並輸入到CNN內進行特徵提取
3. 對候選框中提取出的特徵,使用分類器判別是否屬於一個特定類
4. 對於屬於某一特徵的候選框,用迴歸器進一步調整其位置
Fast RCNN
1. 在影象中確定約1000-2000個候選框 (使用選擇性搜尋)
2. 對整張圖片輸進CNN,得到feature map
3. 找到每個候選框在feature map上的對映patch,將此patch作為每個候選框的卷積特徵輸入到SPP layer和之後的層
4. 對候選框中提取出的特徵,使用分類器判別是否屬於一個特定類
5. 對於屬於某一特徵的候選框,用迴歸器進一步調整其位置
Faster RCNN
1. 對整張圖片輸進CNN,得到feature map
2. 卷積特徵輸入到RPN,得到候選框的特徵資訊
3. 對候選框中提取出的特徵,使用分類器判別是否屬於一個特定類
4. 對於屬於某一特徵的候選框,用迴歸器進一步調整其位置
總的來說,從R-CNN, SPP-NET, Fast R-CNN, Faster R-CNN一路走來,基於深度學習目標檢測的流程變得越來越精簡,精度越來越高,速度也越來越快。可以說基於region proposal的R-CNN系列目標檢測方法是當前目標檢測技術領域最主要的一個分支。
深度學習在計算機視覺的應用中已經十分廣泛,其效果相比於傳統方法也有很大的提高。本文就人臉檢測這個領域,介紹深度學習在人臉檢測領域的發展。
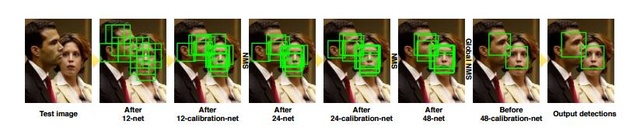
深度學習人臉檢測最早的代表作之一是2015年CVPR的一篇論文《A Convolutional Neural Network Cascade for FaceDetection》,下文簡稱CascadeCNN。這篇文章保留了傳統人臉檢測方法中Cascade的概念,使用3個輸入大小分別為12、24、48的淺層網路,在每個分類網路之後接一個矯正網路用於迴歸人臉框的位置。對比CascadeCNN和傳統人臉檢測方法,本文總結其相同點和不同點。相同點如下:1. 使用了Cascade級聯結構,使用前面的stage快速過濾簡單樣本,後面的stage得到更為準確的分類結果;2. 影象金字塔結構,對於不同scale的人臉大小,通過縮放影象得到影象金字塔再進行處理;3. 滑動視窗加步長的處理模式;4. 最後處理結果根據IOU(intersection over union)大小使用NMS(Non-maximum suppression)方法進行視窗合併。不同點如下:1. 每個stage中CNN的分類器代替了傳統的分類器;2. 每個分類stage之後應用了一個矯正網路使得人臉框的位置更為精確。該論文是當時基於CNN的人臉檢測方法中速度最快的。
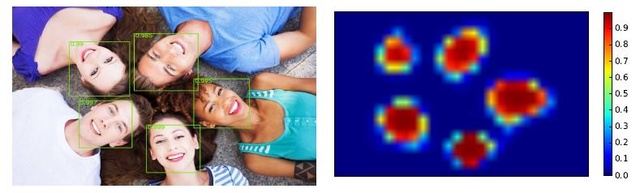
15年另一篇文章關於深度學習人臉檢測比較有代表性的文章是《Multi-view Face Detection Using Deep Convolutional Neural Networks》。這篇文章使用的網路是AlexNet,由於網路的分類能力相對較強,該文沒有采用Cascade結構。是影象金字塔依舊採用,每一層金字塔用AlexNet處理一遍。這篇文章的一個亮點是使用了全卷積網路,將全連線層修改引數排列方式變成卷積層,對輸入影象的大小沒有了限制。金字塔的每一層由AlexNet處理後出來的是一個HeatMap,HeatMap的每個點對應原圖中一個區域。
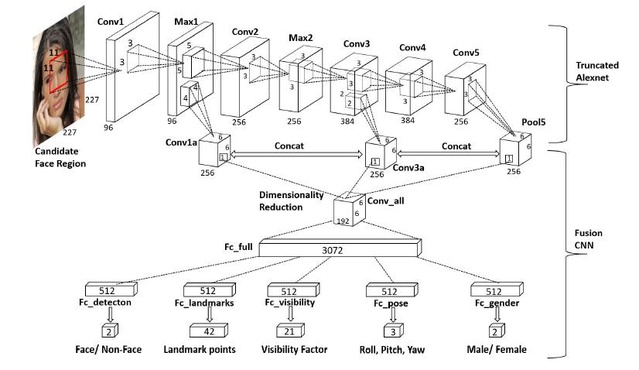
2016年深度學習人臉檢測相關的文章都流行起來multi-task的概念,將人臉檢測(分類)和人臉框位置矯正(迴歸)以及人臉關鍵點定位、姿態、姿態等屬性的檢測相結合(筆者在實驗中發現,除了人臉框位置迴歸,其他的task對人臉檢測的精度沒有任何提高)。相關文章有:《HyperFace: A Deep Multi-task Learning Framework for Face Detection, Landmark Localization, Pose Estimation, and Gender Recognition》、《Joint Training of Cascaded CNN for Face Detection》(後文簡稱JTCCNN)、《Joint Face Detection and Alignment using Multi-task Cascaded Convolutional Networks》(後文簡稱MTCNN)。HyperFace的網路結構也是基於Alexnet的變形,其特點對每個task有一個512大小的fc層,在對應到不同的任務,具體網路結果參見附圖。
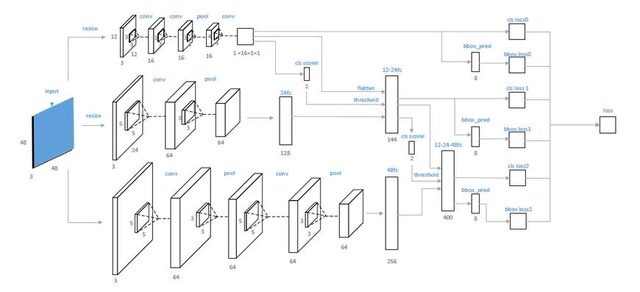
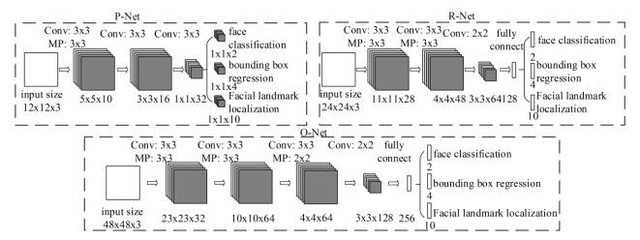
JTCCNN和MTCNN兩篇文章在思路和網路結構上有很多相同之處。這兩個方法都是基於15年CascadeCNN這篇文章的思路進行延伸的。最大的不同點在於,JTCCNN將低層的特徵連線到了高層,12net的特徵會拼接到24net上,12和24拼接得到的特徵又會進一步拼接到48net上,級聯的概率體現在了網路內部,12net、24net、48net對應有自己的閾值,沒有通過閾值的樣本被判斷為負樣本。MTCNN則保持每個Cascade之間的net互不干涉,它在CascadeCNN的基礎上,改進了網路結構,12net應用了全卷積的網路,應用到了multi-task引用人臉框迴歸和關鍵點,進一步調高了人臉檢測的速度和精度。
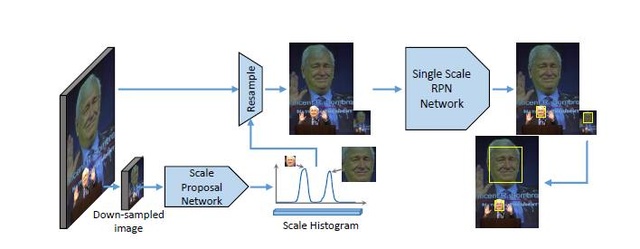
今年人臉檢測相關的文章更多關注到了人臉的scale,能否不需要這麼多層的影象金字塔就能檢測出不同尺度的人臉呢?《Finding tiny face》給出的答案是減少金字塔的層數,同時增加模板尺度這兩種方式相結合,該文章同時實驗驗證,對於小人臉(影象中人臉大小小於20個畫素),加入人臉周圍的context上下文資訊能極大的提高該人臉的檢測率。《Scale-Aware Face Detection》這篇文章的思路比較奇特,先有一個Scale Proposal Network (SPN)得到影象上所有人臉的尺度大小資訊,然後根據此對影象進行resize(在resize的影象上,所有的人臉大小在同一尺度),然後只需要對該sacle的一個尺度的網路便可檢測出所有人臉。《Face Detection through Scale-Friendly Deep Convolutional Networks》Scale-friendly在提供propose方法的時候從影象中提取各種尺度的anchor,力求覆蓋到各種尺度大小。
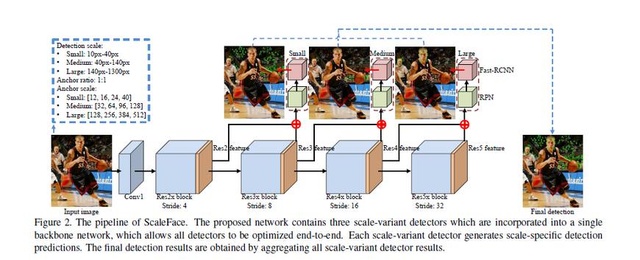
到此很多讀者可能會疑惑,為啥沒有提到RCNN、fastRCNN、fasterRCNN、sppnet、YOLO、SSD、DenseBox等相關物體檢測的文章,也有很多工作是將這些方法應用到人臉檢測的,考慮到其通用性,這裡沒有一一介紹,後續筆者會就物體檢測系列的文章進行詳細描述。
總結來說,全卷積網路代替滑動視窗加步長的方式,利用到時卷積層共享計算的特性;Cascade結構其實和目標檢測的proposal是同一思想,都是想通過一個快速的方法獲取人臉候選位置,排除掉大量的負樣本;影象金字塔、特徵級別金字塔、不同尺度的anchor、不同尺度的模型大小都是為了解決人臉sacle的問題,例如同一個檢測器很難同時檢測出來20*20大小和200*200大小,加入了人臉框迴歸可一定程度的提高尺度的魯棒性。
最後說一下,人臉檢測速度的問題。提到人臉檢測速度,不說影象大小和最小檢測尺度都是耍流氓的行為。最小檢測尺度翻一倍,速度可能要提升不止一倍。上述所有的方法中,結合速度和檢測率,表現最優秀的是MTCNN的方法(但凡涉及到VGG16、Resnet34這種大的網路結構的檢測演算法很難實用起來),後續筆者會詳盡介紹MTCNN的訓練測試流程。
參考:
目標檢測經典文獻:
人臉檢測經典深度學習文獻: