
目標檢測技術演進:Fast R-CNN、Faster R-CNN
在上一篇目標檢測技術演進:R-CNN、Fast R-CNN、Faster R-CNN 之 RCNN中,我講了 RCNN 演算法,似乎它的表現不太好,所以這次我們講講它的進化版 —— Fast RCNN 和 Faster RCNN。
1. Fast RCNN
先看看 Fast RCNN,RCNN 的時間花費主要來自於計算量的巨大。Fast RCNN 在時間花費的提升,就是因為減少了很多的計算量。比較一下,在 RCNN 上,我們在 CNN 上對一張圖片跑 2000 次(因為一張圖片會用 Selective Search 生成 2000 個建議區域),但是在 Fast RCNN 上我們對每一張圖片只跑一次,然後就可以得到所有的區域,這些區域會在後面放到一個 對映(map)
RCNN 的作者 Ross Girshick 應用一種方法來讓 2000 個區域共享 CNN 中的計算。所以在 Fast RCNN 中把輸入圖片放到 CNN 中,它會生成卷積特徵對映。建議區域就會被提取到這個對映上面。然後使用一個 RoI 池化層(RoI pooling layer) 來把所有的建議區域轉換成適合的尺寸,這樣就可以輸進後面的 全連線層(fully connnected network) 了。
分步來看看會比較清晰,這一步我直接把每一步的圖片加上去,有助於理解:
-
首先是輸入圖片,這與之前的 RCNN 差不多:

-
圖片通過 卷積網路(ConvNet) 得到 RoI:

-
然後應用 RoI 池化層來改變所提取的感興趣區域的大小,也就是 RoI 的大小,來確保所有的區域都是相同的尺寸,這是為了後面可以輸入到全連線層上。所以這裡的 RoI Pooling 是 Fast RCNN 的另一份新方法:

-
最後這些區域就輸入到全連線層來對它們進行分類,同時會使用 softmax 和 線性迴歸層(linear regression layers) 來輸出 bounding boxes:
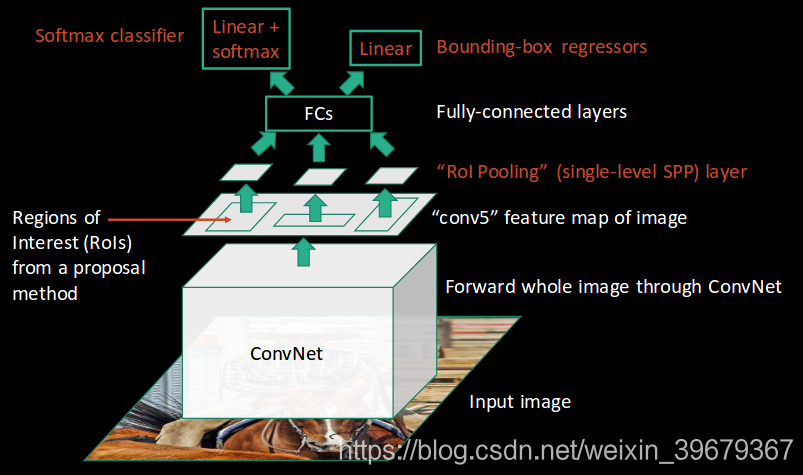
我們來看看兩個網路的差別。在 RCNN 上 2000 個區域都是獨立的,沒有生成對映,而在 Fast RCNN 上,生成的對映就相當於一個區域;在特徵提取、分類和生成選框上,前者使用了三個模型,而後者把三個模型集合到一個模型中,這樣一來就省下了很多的時間。
2. Fast RCNN 的不足
Fast RCNN 沒有解決的一個問題就是,它依然在使用選擇性搜尋來作為尋找 RoI 的區域建議方法,因為它依然很慢。每張圖片話費 2 秒的時間吧,雖然這和 RCNN 比起來好很多了。但是依然不能夠在大量資料上使用。
3. Faster RCNN 橫空出世
Faster RCNN 與 Fast RCNN 最大的不同就是:Faster RCNN(以下稱為 Faster)使用了一個全新的網路 —— Region Proposal Network,也就是「區域建議網路」,簡稱 RPN。RPN 把圖片特徵 map 作為輸入,生成一系列的帶目標分數的建議。也就是說,不再是單純地只輸出建議,而是把建議中是否有物體的分數也預測了。分數越高,代表區域包含物體的可能性越高。
還是來看看圖文步驟:
- 把圖片作為輸入放進卷積網路中去,返回的是一個特徵對映(feature map);
- RPN 處理這些 map,返回帶分數的物體建議;
- 接下來的 RoI pooling 把這些建議都 reshape 成相同的尺寸;
- 最後,放到含有 softmax 層和線性迴歸層的全連線層上,來分類和輸出 bounding boxes。
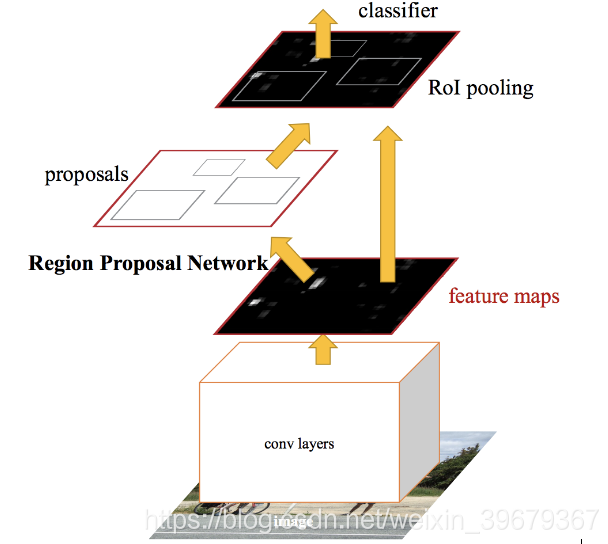
這裡 RPN 被整合在了網路裡面,等於從區域建議到最後的分類迴歸都在同一個網路,實現了端到端。即我們給這個網路輸入一張圖片,網路就會輸出 bounding boxes 和分數。RPN 是 Faster 的重點,來看看裡面怎麼運作的。
從上圖看到,Faster 從 CNN(圖中 conv layers)裡得到 feature map,然後輸入到 RPN 裡。在 RPN 在這個 map 上使用一個滑動視窗(sliding window),在每個視窗中都會生成 k 個不同形狀和大小的 Anchor boxes。在論文中他們使用的是 9 個 Anchor。
Anchor 就是在圖片中有不同形狀和大小的但具有固定尺寸的邊界框。什麼意思呢?就是每一個 Anchor 都是固定的大小,比如有 3*3、6*6、3*6、6*3 這些,他們和最後的 bounding boxes 不一樣,anchor 的尺寸都是固定的。就像上圖紅色的框,而旁邊的藍色的框代表了其不同形狀和大小的框。
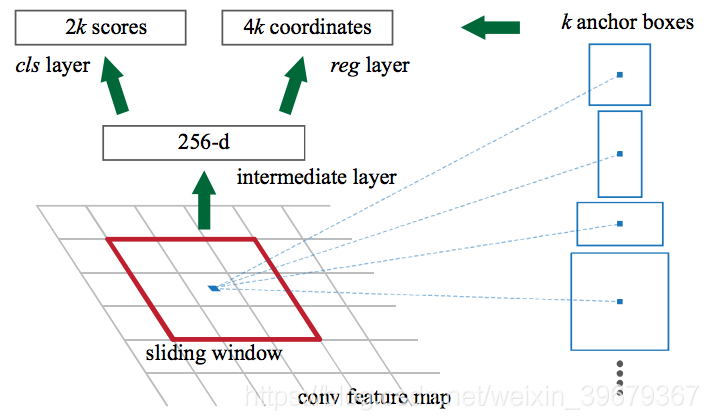
對於 anchor,RPN 會做兩件事:
- 第一件就是預測 anchor 框出的部分屬於物體的可能性;
- 第二就是這個 anchor 對於最後應該生成的 bounding box 的迴歸,或者說怎麼去調節這個 anchor 能使它更加好的框出物體。
在 RPN 之後我們會得到不同形狀大小的 bounding boxes,再輸入到 RoI 池化層中。在這一步,雖然知道 boxes 裡面是一個物體了,但其實是不知道它屬於哪個類別的。就好像是,它知道這個東西是個物體,但是不知道是貓是狗還是人。RoI 池化層的作用就是提取每個 anchor 的固定大小的 feature map:
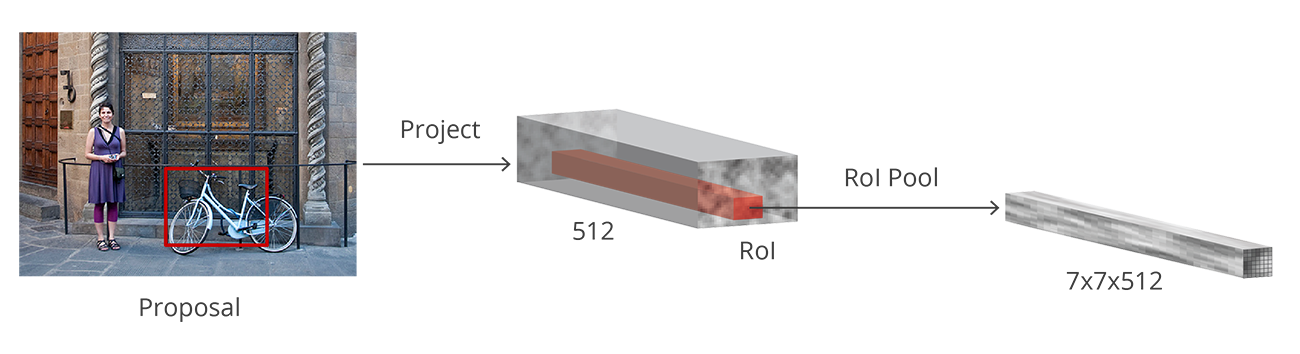
這些 feature map 最後就被送到全連線層裡去做 softmax 分類和線性迴歸。最後就會得到分類好的又有 bounding box 的物體了。
4. Faster RCNN 的不足
雖然是 Faster 了,但是其實還是存在不足的。但是在我看來,它表現得已經很好了,但是我們的目標總是想往著更好去的不是嗎?
從 RCNN 到 Faster 演算法,所有的這些都是使用區域建議來識別物體的。這些網路不是看一張圖片的整體的,而是集中關注它的某一部分,這樣就造成了兩個問題:
- 網路需要對一張圖片的每一部分都處理,以此來保證能夠檢測出所有的物體;
- 網路中的每一部分都接在上一部分的後面,所以後面系統的表現就依賴於前面系統了。
5. 各種演算法的比較:
| 演算法 | 特點 | 平均時間花費(秒) | 限制性 |
|---|---|---|---|
| CNN | 把圖片分為多個區域然後對各個區域進行分類 | — | 需要大量地區域才能使得預測變精確,但是這樣做會帶來很大的計算量 |
| RCNN | 使用選擇性搜尋生成區域,每張圖片抽取 2000 個區域。 | 45 - 50 | 由於每個區域都輸入到 CNN 上,而且使用了三個獨立的模型,計算時間很長 |
| Fast RCNN | 每張圖片由 CNN 抽取 feature maps,然後由選擇性搜尋來生成預測區域;把 RCNN 的三個模型整合為一個 | 2 | 因為選擇性搜尋本身就很慢,再加上計算量依舊沒減,時間花費還是挺高 |
| Faster RCNN | 用**區域建議網路(RPN)**來代替選擇性搜尋,使得演算法變得快了很多 | 0.2 | 因為不同的系統使用串聯的方式連線,目標建議依舊是時間花費的主要原因,而且每層系統的表現受到上層系統的制約 |
6. 結語
我們介紹了 RCNN 的歷史。但這僅僅是目標檢測演算法的開始,還有許許多多的演算法,我們會陸續為你介紹。目標檢測是一個很吸引人的領域。RCNN 算是其中的一個經典,但是還有其他表現得比它好的演算法,例如:YOLO、RetinaNet、Master RCNN 等。我們會繼續講解介紹這些網路,期待著吧!
如果你想了解更多關於人工智慧的資訊,歡迎掃碼關注微信公眾號以及知乎專欄 「譯智社」,我們為大家提供優質的人工智慧文章、國外優質部落格和論文等資訊喲!
