
ORB-SLAM2:基於可識別特徵的自主導航與地圖構建
ORB-SLAM2 :基於可識別特徵的自主導航與地圖構建
ORB-SLAM: Tracking and Mapping Recognizable Features翻譯:2016年2月24日 Taylor Guo
寫在前面的話:由於上個月開始翻譯的時候,沒有校譯,部分關鍵詞翻譯可能不是很恰當,先將就看吧。後面會再更新一版。2016/03/02
摘要:視覺SLAM可以很好地構建地圖,追蹤相機。但這些地圖不能用於本地化,不同的相機,甚至是同一個相機,但可以從不同的視角觀察。這些侷限源自於缺乏可以識別的地圖容量。我們將介紹一種基於關鍵幀的SLAM系統,可以讓地圖複用,用可識別的特徵點構建地圖。我們的系統在一個不變的視角下實時執行本地化操作和閉環控制。我們也加入了消減機制減少地圖中冗餘的關鍵幀。這個系統有足夠的能力複用地圖,並可以用於識別系統。
1. 簡介
相機的位姿估計和真實世界的幾何重構的主要問題是觀測問題,這在mono-SLAM中總所周知。單一相機的問題比較麻煩,因為深度圖無法獲得,而又需要多維幾何來解決問題。立體相機和RGB-D相機在某種程度可以提供深度圖,但單目技術仍然需要。
單目SLAM技術已經發展了較長時間,從最初的濾波方法到最近的基於關鍵幀的SLAM系統。最新的研究表明,基於關鍵幀的技術比濾波方法更精確。最具代表性的是PTAM,被認為是單目的標誌。儘管方案成熟、PTAM演算法效能優良,單目SLAM應用也並不廣泛。地圖很少用來計算相機的位姿,沒有用來定位相機的不同視角,也沒有用來定位不同的相機。場景不是靜止狀態的情況下可能更糟糕。我們認為地圖識別的作用非常關鍵,我們發現在類似PTAM的應用中這一塊做的不夠好。
在我們之前的工作中,我們在PTAM中集成了一個非常有效的識別系統用於導航和閉環控制。這個識別系統基於ORB特徵的二進位制資料包,讓位於在視角不變情況下實時定位系統的效能。我們實驗演示了系統在不同相機和軌跡下的系統複用地圖的效能。我們需要提取特別的特徵(ORB)用來獲取識別的效能。我們用這個方法構建了新的SLAM系統,我們將為ROS釋出開源原始碼。
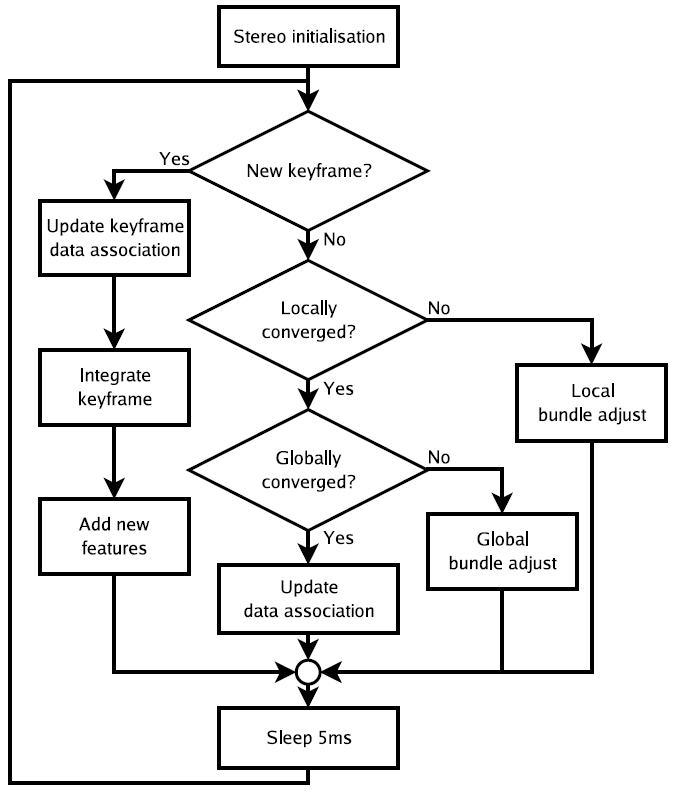
我們的系統使用了大量的視覺資訊,在優化位置識別效能中需要較多關鍵幀資訊與加入削減演算法減少地圖中冗餘關鍵幀上做了大量工作,證明方法富有效率。該系統有3個主要任務:自主導航/追蹤、地圖構建、閉環控制,在多核系統中並行處理。圖 1顯示了系統框圖。
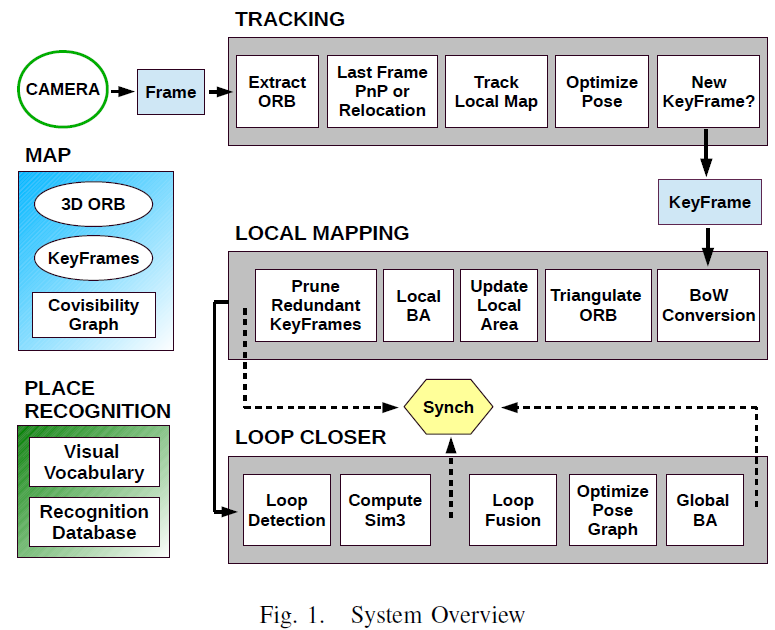
2. 地圖
這一章主要介紹地圖的儲存。
A. 地圖特徵點或3D ORB
地圖特徵點構成真實世界的3D架構。每個特徵點都經過不同視角抽象,然後用Bundle Adjustment優化。這裡影象中的點是ORB特徵點,用角點檢測的FAST演算法獲取。圖塊的大小和方向取決於FAST演算法獲取的規模和關鍵點的方向。每個地圖上的特徵點和一個圖塊n關聯。單個特徵點可能和具有ORB特徵的多個關鍵幀有關,同時有幾個特徵描述器。如果特徵描述器出現特徵不匹配的狀況,它需要處理不同視角的不同地圖特徵點。為了加速資料關聯,每個地圖特徵點的描述器為D,它的與其他所有描述器關聯。另外,每個地圖特徵點儲存了觀察到的最大dmax和最小dmin距離。
B. 關鍵幀
關鍵幀是真實世界的視覺資訊的快照。每個關鍵幀包括了幀內的ORB特徵和相機的位姿。在我們的設計中,關鍵幀並非不可以一幀不少,相反如果一個影象區域能被其它幀完全表示,它就可以被刪除。這將在後面詳細介紹。C. 視覺化影象
互動視覺化資訊在幾個任務中都非常有用,它決定了本地地圖,位置識別的效能。視覺化資訊以間接權重影象的方式儲存在系統中,那裡每個節點是一個關鍵幀和關鍵幀之間的邊緣,邊緣的定義是兩個關鍵幀之間相同的特徵點至少是 θ。如果θ越低,相互關聯度就越高,影象遍歷的代價就越高。Strasdat建議典型的θ值在15到30之間。邊緣的權重就是地圖相同特徵點的數量。
3. 位置識別
系統裡面加入了位置識別偵測閉環和重定位。識別器是基於我們之前的工作,基於效率較高的二進位制字典位置識別器DBoW2。與之前的工作相比有2個方面的改進:首先,在位置識別中,如果資料庫裡有不清楚的匹配,識別器能返回不同的假設條件。其次,我們用視覺化資訊取代了所有的暫存資訊。我們介紹一下之前的工作:
A. 影象識別資料庫
資料庫包含了一個反向序數,它指向字典裡的每個檢視關鍵字,字典裡有關鍵幀,有關鍵幀的權重。用檢索檢視關鍵字來檢索整個資料庫,極大地提高了檢索的效率。新的關鍵幀將在閉環任務執行緒中插入資料庫中,當本地的地圖構建完成後執行這個操作。
重定位或者資料庫閉環檢索後,得到一個相近的分數,在檢索影象後,它計算了所有關鍵幀之間的相同檢視關鍵字。關鍵幀之間有檢視重疊,所以並沒有唯一的高分值的關鍵幀,可能高分值的關鍵幀有好多個。在這個專案中,我們做了檢視集合包含了所有關鍵幀的分數值,這些關鍵幀直接與影象關聯,關鍵幀匹配後就有一個高分值。影象會被緊密及時地分組,同一個位置的檢視關鍵幀分值不會被記錄,但在不同時間下的同一檢視會被插入資料庫。我們不僅僅是得到最優的匹配,所有的匹配分數要在最高分數的90%以上。
B. 高效,優化的ORB匹配
在重定位和閉環控制中,檢索完資料庫後,我們可以分別算出相機位姿和相似變換,可以用於幾何圖形驗證。首先,我們需要計算2個影象的ORB特徵的相似度。如果強制匹配,在某種程度上可能會加速,如果我們只比較字典樹的第二層的同一節點的ORB特徵,匹配的效能沒有明顯減少。初始匹配可以通過方向一致性檢測來優化。C. 視覺一致性
閉環控制的健壯性非常重要,錯誤的閉環控制將毀壞地圖構建。有論文提到短期一致性測試,這樣系統就可以等待獲取一系列貫序暫時一致性匹配,用於最後形成閉環控制。這裡我們建議採用視覺一致性測試,這樣如果可檢視像存在邊緣,就可以採用貫序關鍵幀匹配。4. 自主導航/追蹤
地圖的初始化是執行一個自動過程,從兩幀之間找到單應平面變換或矩陣。初始化完成後,追蹤功能就根據每個新進來的影象幀估計相機位姿。我們將詳細描述追蹤功能的具體步驟。A. ORB特徵獲取
第一步獲取影象幀裡的ORB特徵點。開始時,計算影象金字塔,偵測每層的FAST演算法關鍵特徵點。但只提取這些關鍵點的一個子集。考慮以下主要引數:影象 金字塔的層數,不同層之間的比例因子,要獲取的ORB特徵點的數量(關鍵點描述),偵測的閾值,最重要的是保留和描述關鍵點的子集的規則。這些引數直接影響特徵的規模的不變性,任務的計算成本(字典包,資料關聯,等),影象上的關鍵點分佈。我們提取了基於比例因子1.2的8層1000個ORB特徵點。為了最大程度地分散影象上的關鍵點,我們將影象分成網格,使每個網格里的關鍵點數量一樣。如果有網格里沒有足夠的關鍵點,剩下的網格就要獲取更多的關鍵點。
B. 追蹤之前的影象幀
如果上一幀影象追蹤成功,我們可以從上一幀中估計第一個的相機位姿。上一幀影象中的每個ORB,與地圖上的點關聯,都會搜尋並匹配上一位置發生變動的區域性區域。如果沒有發現足夠的匹配,比如相機快速移動,匹配過程就會在更大的範圍內再搜尋一遍。方向一致性測試將對最初的匹配優化。此時,我們就有了一組3D到2D的一一對應關係,我們就可以計算相機位姿、解決RANSAC迭代中的PnP問題。C. 重定位:從劃除幀中再追蹤
如果追蹤失效的話,我們將幀轉換成關鍵字的包,然後檢索關鍵幀資料庫用於重定位。如果幾個地方的影象對於當前幀相似,將會有幾個候選幀用於重定位。對於每個候選關鍵幀都要計算ORB特徵匹配一致性,即當然幀和ORB特徵點關聯的地圖點的關鍵幀,如第3節B小節裡解釋的。這樣我們就有了每個候選關鍵幀的一組2D到3D的一一對應關係。現在對每個候選幀執行RANSAC迭代演算法,計算出相機的位姿解決每次迭代的PnP問題。如果我們獲得了相機位姿,我們就可以繼續執行追蹤功能。D. 追蹤本地地圖
現在有了真實環境中的相機的位姿,我們就可以將地圖投影到影象幀上並搜尋更多地圖點進行對應。我們並不像PTAM那樣對映所有的地圖點,我們使用與Strasdat的論文裡相同的方法,投射本地地圖。這個本地地圖包含一組關鍵幀K1,形成當前幀的地圖點;K2是鄰近的關鍵幀組。在緊密關聯的地圖中,像K2這樣的集合可能非常多,我們限制它們的數量。本地地圖也有一個參考關鍵幀Kref,屬於K1,它包含了當前幀的大部分地圖點。所有的地圖點都在關鍵幀K中,K=K1∪K2,從這些幀裡面按照如下方法搜尋本地地圖:1. 計算當前幀的地圖雲點對映x。去掉影象外面的雲點。
2. 計算角度:視線v和地圖點n的法線的夾角。去掉v.n<cos(45度)的雲點。(ORB裡每個地圖點有法線這一說,如果視線角和它的法線相差太大,它的外觀通常會有變化)
3. 計算地圖雲點和相機中心的距離d。去掉地圖雲點相同尺寸區域以外的點,即d不屬於[dmin, dmax]之間的點。
4. 計算幀內的比值d/dmin。
5. 比較地圖雲點描述器D和影象幀內ORB特徵點,其大小是否接近x。
6. 關聯地圖雲點獲取最優匹配。
E. 最終的位姿優化
追蹤的最後一步是優化相機位姿,具體是使用4.B或4.C裡面描述的方法估計初始位姿,用幀裡的ORB特徵點與本地地圖裡的雲點一一匹配。這樣優化儘可能避免了對映錯誤,保持了地圖雲點的位置。我們使用g2o 列文伯格-馬夸爾特非線性最小二乘演算法和Huber估計器。F. 新的關鍵幀的取捨
如果追蹤成功,我們就要決定是否插入新的關鍵幀。插入新的關鍵幀需要滿足如下條件:1. 在最近一次重定位中,超過20個幀被略過。
2. 當前幀追蹤了至少50個雲點。
3. 當前幀追蹤的地圖雲點少於Kref的90%。
4. 本地地圖構建處理完上一關鍵幀後,至少10幀從上一關鍵幀插入動作後被略過。或者本地地圖構建完成了本地偏差調整後,至少20個幀被略過。
我們沒有像PTAM那樣採用與其他幀距離上的條件限制,這裡標準更合理,如視角變換(條件3),儘可能快地插入幀(條件4)。第1個條件確保獲得一個較好地重定位。條件2 確保一個良好的追蹤。
5. 本地地圖構建
本地地圖構建執行緒處理新的幀,更新優化它們的本地鄰近的幀。追蹤任務插入的新的關鍵幀儲存在一個佇列裡,包含了最近一次插入的關鍵幀。 當本地地圖構建從佇列中取出最後一個關鍵幀時,要執行以下步驟:A. 字典
第一步是將關鍵幀轉換成關鍵字包表示。這會返回一個關鍵字向量,用於後面的閉環控制,也用於將ORB特徵點與字典樹裡的第二個節點關聯,這個字典樹用於下一步的資料關聯。
B. 確定新的地圖雲點
通過三角化不同關鍵幀的ORB特徵點可以構建新的地圖雲點。PTAM用最鄰近的關鍵幀三角化這些點,這些幀的視差非常小;我們用相鄰的N個關鍵幀來三角化這些點,這些幀具有很多相同的影象點。我們需要約束關鍵幀的數量,由於地圖間高度關聯,計算代價會很大。我們搜尋當前關鍵幀裡的ORB與其他關鍵幀中的進行匹配,只是比較描述器。我們比較字典第二層下相同節點裡的ORB,去掉不能滿足極化約束條件的匹配。一旦ORB匹配成功,它們就被三角化了。如果地圖點視差小於1度,也要被去掉。開始時,地圖點只能在前兩個關鍵幀裡看到,但其他關鍵幀裡也有,所以地圖點投射到其他關鍵幀裡供追蹤演算法使用,如第4節D小節所示。C. 更新區域性區域
在後面的3個關鍵幀建立後,要確認地圖點雲是否出錯,需要滿足如下2個條件:
1.)追蹤功能要能找到那些地圖點,這些點在超過25%的幀裡;
2.)如果在地圖點建立後丟掉一個關鍵幀,這個關鍵幀必須在3個關鍵幀中出現過;
關鍵幀裡的地圖點有新的觀測方法,關鍵幀裡的關聯影象的邊緣需要重新計算。另外,每個地圖點的描述器D也要重新計算。
D. 區域性偏差調整
與PTAM類似,區域性偏差調整優化當前處理的關鍵幀,這些關鍵幀與影象關聯,這些關鍵幀能看到這些影象點。其他能看到這些點的關鍵幀,但不是當前的關鍵幀也要優化。為了解決非線性優化問題,我們使用g2o裡面的列文伯格-馬夸爾特非線性最小二乘演算法,Huber估計器。經過優化後,我們可以再次計算n, 尺度不變距離dnin,dmax。E. 祛除冗餘關鍵幀
為了去掉地圖中冗餘的關鍵幀,以防止關鍵幀的數量急速變大,我們去掉其他相同或更好的關鍵幀中90%的地圖點已經被觀測到過的關鍵幀。這個祛除的過程如圖2所示。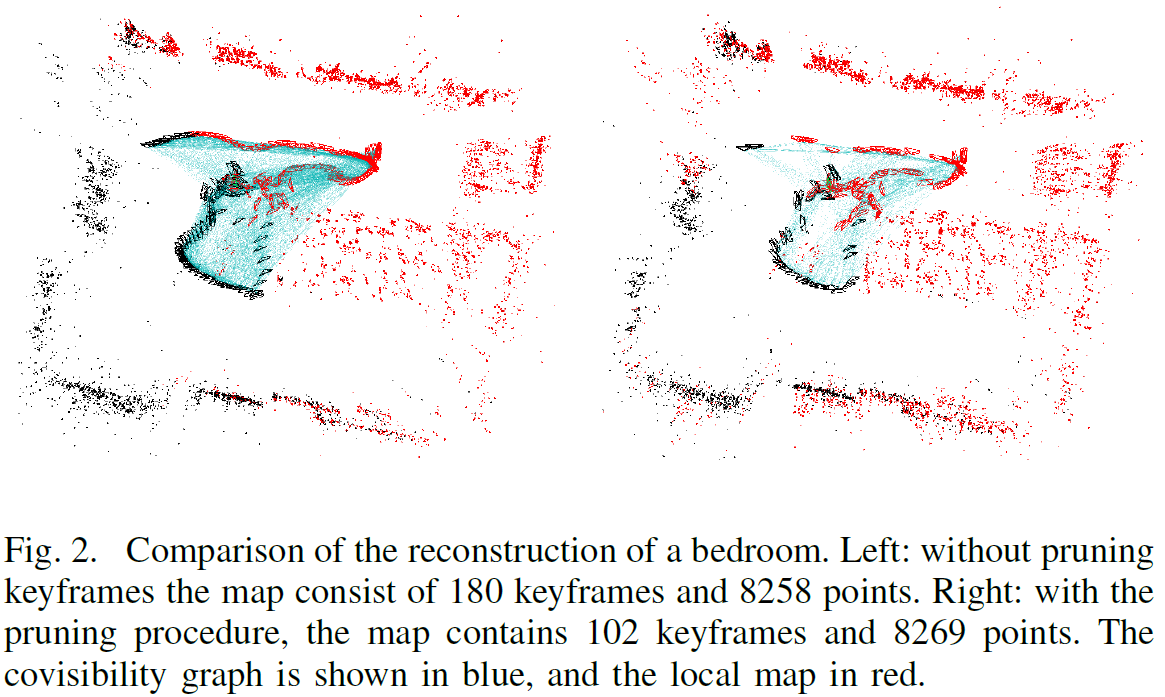
6. 閉環控制
閉環控制用來偵測地圖的閉環狀況,如果發現閉環,將執行閉環控制以保持全域性地圖的一致性。區域性地圖構建後,閉環控制獲取了最後一個處理的關鍵幀Ki,除此之外,閉環控制還執行了如下任務。A. 閉環偵測
我們先計算關鍵字包的關鍵字向量Ki與其鄰近的相關影象的相似性,留下最低分值Smin。然後,閉環控制檢索關鍵幀資料庫,去掉那些分值低於Smin的關鍵幀。另外,最後所有直接與Ki關聯的關鍵幀都去掉。為了增加控制器的魯棒性,我們必須偵測3個連續的閉環偵測器,它們的影象相互關聯保持一致,如第3節C裡面所示。當閉環偵測的關鍵幀通過了影象關聯一致性測試,下一步就要計算相似變換。
B. 計算相似變換
在單目SLAM中,有7個自由度,地圖可能偏移,3種改變,3種旋轉,1個尺寸因子。為了閉合迴路,我們需要計算從當前關鍵幀Ki到迴路關鍵幀Kl的相似變換,迴路中的關鍵幀Kl提供了迴路的累積誤差。這個相似變換也用來作為迴路的幾何驗證。在重定位的過程中,如果對於當前幀有幾個地方的場景相似,就可能有好幾個迴路。這樣,我們首先計算ORB特徵點的一致性,即與地圖點關聯的ORB的當前幀與迴路中的關鍵幀,按照第3節B中的過程執行。現在,對每個迴環,我們有了3D到3D的一一對應關係。我們對每個迴環執行RANSAC迭代,計算相似變換。如果相似度Sil有足夠的有效資料,第1個迴環就成功了。
C. 與區域性地圖構建執行緒同步
在修正迴路之前,當閉環控制完成當前操作後它就會停止執行,傳送一個訊號給本地地圖構建執行緒。一旦本地地圖構建執行緒停止,閉環控制就要修正迴路。這個過程非常必要,2個執行緒都可能會修改關鍵幀的位姿,地圖雲點(地圖點裡面可能造成混淆,導致地圖構建失敗)。
D. 迴路融合
迴路修正的第一步就是融合重複的地圖點,插入閉環控制的關聯視覺地圖。開始的時候,用相似變換Sil來修正Tiw關鍵幀的位姿,這種修正方法可以複製到Ki相鄰的關鍵幀上,然後串聯執行所有的相似變換,這樣迴環的兩端就可以有效對齊。迴路的關鍵幀可以看到所有的地圖點,與它鄰近的點都投影到Ki上,這些投影的點在一個狹小的區域性區域進行搜尋匹配。所有匹配的地圖點和Sil中的有效資料融合。融合過程中的所有有效的關鍵幀將更新關聯影象中的邊緣,產生的新的邊緣用於閉環控制。E. 關聯檢視位姿影象優化
為了閉合迴路,修正累積誤差,我們將執行一個全域性優化。當執行誤差調整時,有必要使用魯棒成本計算函式,我們需要先算出一個最初的方案供優化器收斂功能使用。這個方案由相互關聯影象的位姿優化後的結果組成,而閉環邊緣上的誤差分佈在整個影象中。影象位姿優化器通過相似變換修正尺度偏移。這個方法比我們之前的方法更通用,之前的方法中,影象的位姿只是連線關鍵幀形成一個圈,其他的都一樣,優化過程也一樣,這裡就不在講了。F. 全域性偏差調整
整個地圖最後會通過單點的影象位姿優化完成。優化過程和第5節D裡面所說的區域性偏差調整一樣,不過這裡所有的關鍵幀和地圖點都會被優化。優化後,區域性地圖構建會再次發出。7. 上機除錯
我們做了兩個實驗,用來演示系統的優勢 。第一個是手持相機在實驗室順序完成一個迴路,環境閉塞、相機劇烈移動。第二個是一段視訊在更大場景下測試這個系統。系統被整合到ROS裡面,我們用錄製的視訊模擬相機的運動,影象幀率都一樣。附錄1中的視訊是和PTAM系統的對比。A. 實驗室視訊
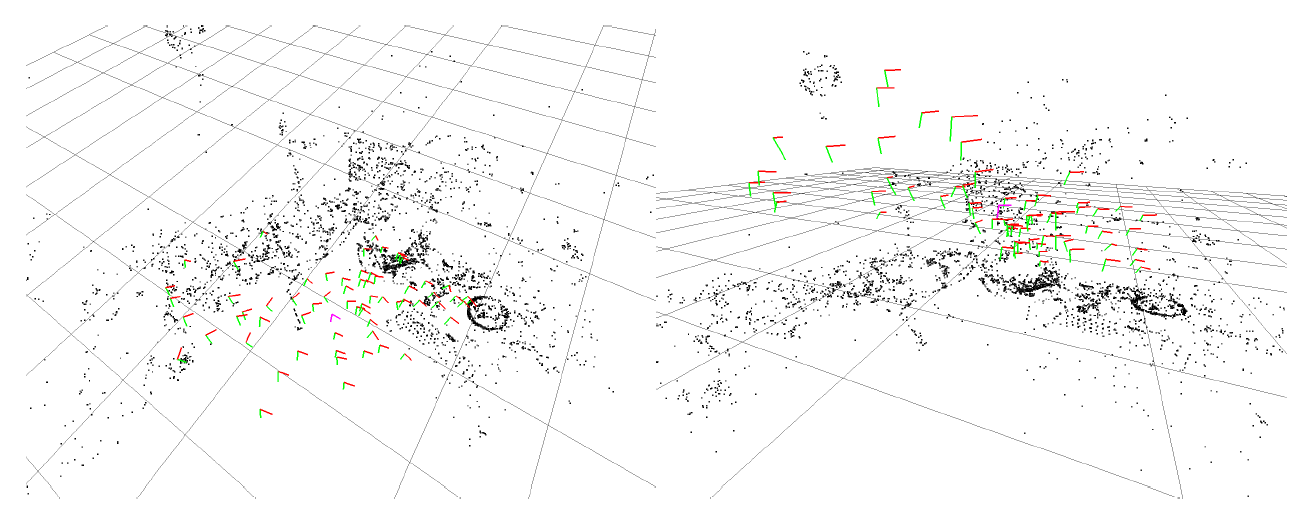
這個視訊是30fps,752x480解析度的。如圖3所示。重定位有一些難度,如圖4所示。所有的追蹤時間如圖5所示。90%的幀追蹤都少於40毫秒。在實際步驟中,追蹤時間會稍微增加,因為關聯影象之間的關聯程度更大,區域性地圖更大。閉環偵測花了5毫秒從關鍵幀資料庫中取回迴路,關鍵幀資料庫包含86個關鍵幀,計算相似度和融合迴路花了173毫秒,影象位姿優化花了187毫秒優化影象裡面的1692個邊緣。最後,全域性誤差調整花了518毫秒。


我們用同樣的步驟也比較了PTAM。開始時,嘗試了20多次來初始化。PTAM在後續好幾步都跟丟了,我們的系統沒有,在重定位中的失效是由於缺少不變的視角。
B. NewCollege
這個實驗室一個立體視訊,我們只處理左邊的影象,是20fps,512x384解析度下拍攝的。圖6顯示了不同時間的地圖重構,圖7顯示了最後的重構,包含690個關鍵幀,33000個點。圖5顯示了每幀所有的處理時間,90%的影象幀都少於50毫秒。圖6顯示了在中間部分機器人重新跑了大的迴路,區域性地圖大於探測到的地方,所以追蹤花了更多的時間。迴路檢測花了7毫秒在280關鍵幀的資料庫中檢測迴路。迴路融合花了333毫秒,位姿優化花了2.07秒優化10831個邊緣的影象。我們非常清楚地看到,在一個大的迴路中優化所有相互關聯的影象複雜度太大,所以並不需要優化所有的邊緣,這個方法我們將在後續工作中進行。
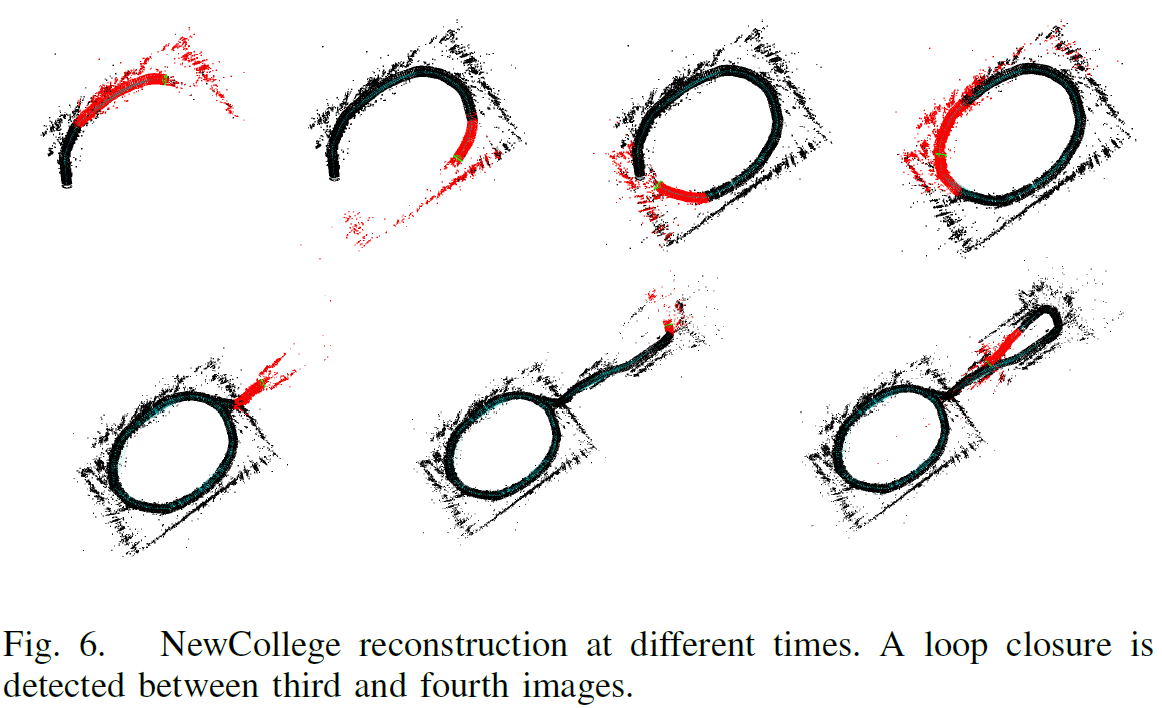

8. 結論
我們構建了一個新的視覺SLAM系統構建可識別的地圖。不需要對所有的特徵點採用SLAM演算法,只需要追蹤相機的當前位姿,我們對映地圖用於識別位置和物體。這有效地擴充套件了地圖的複用性。與PTAM在小型地圖的應用對比後,前段的複雜度大,在相機重定位上有巨大的改進。後端可以執行大尺度的地圖構建,包括有效可靠的閉環控制。我們目前在研究地圖的初始化,由於時間空間限制我們在這裡就忽略了,稀疏的影象位姿可以通過閉環控制優化。我們將會發布原始碼,大家就可以從中受益。感謝
本專案得到了西班牙xxx專案的支援,xxx獎學金支援。(抱歉,完全看不懂西班牙文,西班牙式英語的翻譯難度也是看得人醉了。)參考文獻
[1] D. G´alvez-L´opez and J. D. Tard´os. Bags of binary words for fast place recognition in image sequences. IEEE Transactions on Robotics, 28(5):1188–1197, 2012.
[2] G. Klein and D. Murray. Parallel tracking and mapping for small AR workspaces. In International Symposium on Mixed and Augmented Reality (ISMAR), 2007.
[3] R. Kuemmerle, G. Grisetti, H. Strasdat, K. Konolige, and W. Burgard. g2o: A general framework for graph optimization. In IEEE International Conference on Robotics and Automation (ICRA), 2011.
[4] V. Lepetit, F. Moreno-Noguer, and P. Fua. EPnP: An accurate O(n) solution to the PnP problem. International Journal of Computer Vision, 81(2):155–166, 2009.
[5] R. Mur-Artal and J. D. Tard´os. Fast relocalisation and loop closing in keyframe-based SLAM. In IEEE International Conference on Robotics and Automation (ICRA), 2014.
[6] E. Rublee, V. Rabaud, K. Konolige, and G. Bradski. ORB: an efficient alternative to SIFT or SURF. In IEEE International Conference on Computer Vision (ICCV),
2011.
[7] M. Smith, I. Baldwin, W. Churchill, R. Paul, and P. Newman. The new college vision and laser data set. The International Journal of Robotics Research, 28(5):595–
599, 2009.
[8] H. Strasdat, J. M. M. Montiel, and A. J. Davison. Scale drift-aware large scale monocular SLAM. In Robotics:Science and Systems (RSS), 2010.
[9] H. Strasdat, A. J. Davison, J. M. M. Montiel, and K. Konolige. Double window optimisation for constant time visual SLAM. In IEEE International Conference on Computer Vision (ICCV), 2011.
[10] H. Strasdat, J. M. M. Montiel, and A. J. Davison. Visual SLAM: Why filter? Image and Vision Computing, 30(2): 65–77, 2012.
翻譯過程中參考資料:
隨機抽樣一致 RANSAC(轉)
http://www.cnblogs.com/cfantaisie/archive/2011/06/09/2076864.html
Bundle Adjustment到底是什麼?
http://www.zhihu.com/question/29082659
--------2016年2月26日---翻譯初稿完成---17:50-------------------------------------------------------------------------------
--------感謝麒麒、敏敏這兩天的陪伴和容忍------------------------------------------------------------------------------------
詞袋模型在影象序列中快速位置識別的應用
Bags of Binary Words for Fast Place Recognition in Image Sequences
翻譯:2016年3月2日 Taylor Guo
關鍵詞:詞袋模型(Bag-of-Word) 特徵向量(descriptor)
閉環檢測目前多采用詞袋模型(Bag-of-Word),源自於計算機視覺理論。它實質上是一個檢測觀測資料相似性的問題。
詞袋模型中,提取每張影象中的特徵,把它們的特徵向量(descriptor)進行聚類,建立類別資料庫。
比如說,眼睛、鼻子、耳朵、嘴等等(實際應用中基本上是一些邊緣和角)。
假設有10000個類。然後,對於每一個影象,可以分析它含有資料庫中哪幾個類。以1表示有,以0表示沒有。那麼,這個影象就可用10000維的一個向量來表達。而不同的影象,只要比較它們的向量即可。
影象詞袋模型也是一種基於影象區域性特徵的標分類演算法,它只考慮目標的區域性區域的表面特徵,而忽略他們之間的空間關係,對目標的整體形狀不加限制,這樣建立的目標模型就有很大的靈活性,不會侷限於某一種形狀的特徵,可以處理類內目標的形狀變化。
影象與文字對比:
|
文字 |
文集 (Corpus) |
文件 (Document) |
單詞 (Word) |
字典 (Vocabulary) |
|
影象 |
影象集 (Image set) |
影象 (Image) |
視覺單詞 (Visual Word) |
視覺字典 (Visual Vocabulary) |
影象詞袋模型的基本結構:
所謂詞袋,就是包含一組資料的打包或封裝。在一個詞袋中往往包含了若干幅圖的基本特徵元素。在一個完整的詞袋中,一般有若干幅圖的區域性特徵,包括形狀、結構、顏色等具有魯棒性,不變性的特徵。由於詞袋具有一類或多類影象的全部特徵,故而當我們提取出詞袋中的元素時,就可以對相近類影象進行描述,同時也可以用作不同類別影象的分類。詞袋模型在影象描述中的應用是近年的研究熱點。
詞袋模型的原理非常簡單,詞袋模型是文字的簡化描述模型。在此模型中,文字被表達成無序的單詞組合,不去考慮語法與詞序。以文字為例,如果一個文字X表示一連串有順序的詞的排列,那麼機器對於X的識別其實就是計算出X在所有文字詞語中出現的可能,也就是概率多個詞語概率的相乘p(X)=p(X1)p(X2|X1)…p(Xn|Xn-1)其中P(x1)表示第一個詞出現的概率,p(X2|X1)表示在第一個詞出現的前提下第二個次出現的概率,而詞袋模型就是這種文字模型的特例,即Xk出現的概率與前面的X無關,故有p(X)=p(X1)p(X2)…p(Xn)成立。
主要利用詞袋模型的特點,根據已知的影象對未知的(機器未能識別的)影象進行描述,以達到對待描述影象的一個機器性認知,主要步驟分為三步:特徵提取、特徵碼本的聚類、資料分析及統計,條形圖顯示。Visual words的擷取大致上是將影象的SIFT features,在keypoint feature space上做K-means clustering的結果,以histogram來表示,是一種bag-of-features。除了可用於retrieval外,visual words也被用於image classification。
Visual words (簡稱VWs) 近年來在image retrieval領域被大量使用,其motivation其實是從text retrieval領域而來,是基於文字上的textual words,套用在影像上的模擬。如同於一篇文章是由許多文字(textual words) 組合而成,若我們也能將一張影像表示成由許多 “visual words”組合而成,就能將過去在text retrieval領域的技巧直接利用於imageretrieval;而以文字搜尋系統現今的效率,將影像的表示法「文字化」也有助於large-scale影像搜尋系統的效率。在文獻 [1] “Video Google: A Text Retrieval Approach to Object Matching in Videos,” Proc. IEEE International Conference on Computer Vision, 2003有提到motivation of visual words的細節。首先我們先回顧textretrieval的過程:1. 一篇文章被parse成許多文字,2. 每個文字是由它的「主幹(stem)」來表示的。例如以 ‘walk’ 這個字來說,‘walk’、‘walking’、‘walks’ 等variants同屬於 ‘walk’ 這個主幹,在text retrieval system裡被視為同一個字。3. 排除掉每篇文章都有的極端常見字,例如 ‘the’ 和 ‘an’。4. 一篇文章文章的表示法,即以每個字出現頻率的histogram vector來表示。5. 在此histogram中,對於每個字其實都有給一個某種形式weight,例如Google利用PageRank [2] 的方式來做weighting。6. 在執行文字搜尋時,回傳和此query vector最接近(以角度衡量)的文章。
步驟1:偵測影像中的SIFT keypoints,並計算keypoint descriptors。例如在原始SIFT文獻 [3] 使用Difference of Gaussians (DoG) 來偵測keypoints,而以一個128-D的向量作為descriptor。偵測keypoints的動作相當於上一節所說的1. 將文章parse成一個一個的文字。
步驟2:將所有訓練影像的所有keypoint descriptors,散佈於一個128-D的keypoint feature space中,再執行一個clustering algorithm,例如K-means或是這學期教過的EM。在image retrieval領域中,cluster數 K 常訂為104 ~ 106。同一個cluster裡的keypoints,相當於是同一個 “visual word stem” 的variants,在retrieval / classification系統中被視為同一個VW,因此K也被稱為系統裡的 “vocabulary size”。clustering後的結果相當於上一節所說的2. 同一個word stem下有許多的variants。
步驟3:最後,一張影像可看成由許多VW(原先是keypoints)組成。因為在retrieval領域,我們並不在意文字的排列順序,只在意文章中文字的出現頻率,同樣的道理,一張影像中我們只在乎每個VW stem的出現頻率。以這種概念構成的特徵被稱為 “Bag-of-features”,只在乎袋子裡有什麼物品,而不是物品的排列順序。因此影像特徵的表示法為根據VW出現頻率的 “visual word histogram”。這種概念與上一節4.的文字出現頻率histogram相同。
結論:Visual words可看作是將影像中local的keypoint descriptors,套上clustering algorithm後,變成整張影像的global feature。
Visual words 除了大量用於image retrieval外,也可以直接作為features用於image classification。本專題的目的就是將visual words作為影像特徵,並套用於multi-class image classification。
摘要:
我們採用視覺詞袋模型,通過FAST+BRIEF特徵提出一種位姿識別方法,通過構造詞彙樹生成二進位制特徵向量描述器空間,使用樹形結構加速幾何驗證和匹配。整個過程,包括特徵提取,共26300張影象序列,每幀22ms,比之前的方法要快很多。
一簡介
視覺SLAM的一個最重要要求是要具有良好魯棒性的位姿識別,在自主導航過程中,未觀測到的區域需要重新觀測時,一般的匹配演算法就會失效。如果觀測資料有效,閉環控制就可以提供正確的資料關聯,從而獲得完整的地圖。在機器人的應用中,由於視覺模糊、突然運動、移動阻塞或定位失效後,也可以採用這種方法。這種方法在一個小範圍的環境中,用影象構建地圖,效能優良;但在大範圍的環境中,從影象到影象的FAB-MAP構建地圖的方法更好。這種方法通過機器人線上獲取影象,構建資料庫,其新獲取的影象與之前的那副影象非常相似,相似的影象序列形成一個閉環迴路。最近幾年的影象匹配演算法都是基於詞袋模型中的數字向量比較的方法。詞袋模型產生了有效地、快速地影象匹配,但如果影象失真,對閉環迴路卻不是一個好方法。那麼,我們就需要驗證影象的視覺匹配,進行特徵匹配。閉環迴路控制演算法的瓶頸是特徵提取,這一步驟的演算法複雜度是其他步驟的10倍左右。這就要求SLAM演算法同時執行在兩個無耦合關係的執行緒上:一個執行SLAM功能;另一個用作閉環迴路控制,如文章5《CI-Graph SLAM for 3D Reconstruction of Large and ComplexEnvironments using a Multicamera System》所述。
在本文中將採用常用CPU和單目相機提出一種演算法用於閉環迴路偵測,實時構建雲點匹配。這個方法基於影象詞袋模型和幾何特徵驗證,提出優化演算法。主要通過基於FAST關鍵點的BRIEF特徵向量描述器提高速度,在第三節裡會具體解釋。BRIEF特徵向量描述器是一個二進位制向量,每一個位上的值是由關鍵點附近指定的兩個畫素的亮度比較得到的結果。儘管BRIEF特徵向量描述器在尺度和旋轉上不變,我們的實驗表明在運動機器人上針對相機平面運動閉環迴路魯棒性非常好,在運算時間和演算法特性上取得很好的平衡。
本文使用儲存於二進制空間上的詞袋模型,討論了順序索引和逆序索引,如第四章所述。據我們所知,這是第一次採用二進位制字典用於閉環迴路檢測。逆序方法用於提取與給定影象相似的影象。順序索引有效地獲取影象間的雲點匹配,加快回路確認中的幾何特徵檢驗。
第五節詳細講述了閉合迴路檢測演算法的細節。為了檢驗迴路是否閉合,我們驗證當前影象匹配的一致性。本文方法針對同一位姿的相似影象,避免資料庫檢索時重複計算。在處理影象匹配時,我們將表示同一位姿的相似影象進行分組來解決這一問題。
第六節對實驗進行了評估,分析了演算法不同部分的優點。對比了BRIEF和SURF特徵演算法的效率,提出了用於閉合迴路控制的特徵向量描述器。還分析了閉環迴路驗證中實時幾何特徵一致性測試程式的效能。最後提供了在5種公共資料集0.7-4米軌跡下的測試結果。完成了整個閉環迴路的檢測過程,包括特徵提取,26300張影象,其中最長處理時間52毫秒,平均處理時間22毫秒,明顯強於之前的方法。
這個工作的早期版本如《Real-timeloop detection with bags of binary words》所示,在本文中我們增強了順序檢索方法,加強了該實驗的評估方法,在最新的資料集上提供了實驗結果,與FAB-MAP2.0演算法進行了對比。
二 相關工作
由於其優良效能,基於影象的位姿識別在機器人領域備受重視。例如採用全向相機的閉環迴路檢測系統FAB-MAP。FAB-MAP採用詞袋模型表示影象,使用Chow-Liu樹獲取關鍵字的檢視相關概率。FAB-MAP已經成為閉環迴路檢測的標準方法,但當相機長時間提供的影象具有相似的內容結構時,其魯棒性會降低。在文章4《Fast and incremental method forloop-closure detection using bags of visual words》中,提出了用於建立增量式線上視覺字典,儲存影象和顏色。兩個詞袋模型用於貝葉斯濾波器的輸入,貝葉斯濾波器基於上一匹配的概率估計出兩幅影象的匹配概率。與概率方法不同的是,我們採用實時一致性檢驗增強檢測的可靠性。這種方法在之前的工作中《CI-Graph SLAM for 3D Reconstruction of Large and ComplexEnvironments using a Multicamera System》和《Robust PlaceRecognition With Stereo Sequences》證明是有效的。本文第一次採用了詞袋模型避免了匹配過程中相似影象間的重複運算,可以使系統在更高的頻率上工作。
為了確認閉合迴路,通常採用幾何特徵檢驗。我們採用極值約束獲取最優匹配,採用順序索引更快地計算相似點匹配。文章《View-basedmaps》使用立體相機視覺里程方法實時構建視覺地圖,採用詞袋模型檢驗閉合迴路。幾何特徵測試是計算用於影象匹配的空間變換。然而,他們並未考慮影象匹配的一致性問題,這需要採用幾何測試尋找閉合迴路。
大多數的閉環迴路工作,使用SIFT或SURF提取特徵,這種方法對於亮度、尺度和旋轉變換具有不變的特徵,在視角較小的變化情況下效能良好。但特徵提取往往需要計算100-700毫秒,如果不使用GPU,採用近似SIFT特徵向量描述器,或者減小尺度,來減小特徵提取的計算時間,文章《View-based maps》提出了一種壓縮隨機樹方法,該方法計算了一個影象區塊和其他已經離線訓練的區塊的相似度,連結這些相似度的值形成區塊特徵向量,使用隨機正射投影減小尺寸,這種方法提供了快速特徵向量的描述器,適合實時應用。我們的工作和這篇文章中類似,使用富有效率的特徵提取方法降低處理時間,BRIEF特徵向量描述器,或BRISK,或ORB(ORB: An Efficient Alternative to SIFTor SURF)都是採用二進位制,計算速度快。一個主要的優勢是資訊量精簡,使用了更少的記憶體,更快地進行比較,詞袋模型的運算速度也就更快。
區域性特徵提取(主要是關鍵點和它們的特徵描述向量)的計算代價巨大,在比較影象,實時場景計算中,這是一個瓶頸。為了解決這個問題,我們採用FAST關鍵點和最新的BRIEF特徵向量描述。FAST關鍵點採用Bresenham點畫圓演算法,比較半徑為3畫素以內的灰度值來檢測角點,只有很少的一部分畫素用來對比,角點的獲取速度非常快,適用於實時應用的系統中。
針對每個FAST關鍵點,我們在它們周圍都畫了一個方形區塊計算BRIEF特徵向量。每個影象區塊BRIEF特徵向量描述器是一個二進位制特徵向量。每個位是影象區塊中兩個畫素之間亮度比較的結果的值。這些區塊已經經過高斯核函式濾除噪聲進行過平滑處理。給定影象區塊尺寸Sb,待測畫素對是在離線狀態下隨機選擇的。除Sb外,我們還必須設定引數Lb:待測試的數量(比如特徵向量的長度)。對於影象中的點P,其BRIEF特徵向量B(P)表示為:
Bi(p)是特徵向量第i位;I(.)是平滑後像素點的亮度;ai和bi是2維平面上相對於測試點i的距離,值為。特徵向量不需要訓練,只是離線狀態下,隨機選擇的畫素點,幾乎不消耗時間。最初的BRIEF特徵向量描述器根據常態分佈選擇測試點ai,bi的座標。我們發現用相鄰的一對點的測試效果更好,通過取樣分佈和選擇配對的點的座標。關於特徵向量的長度和區塊的大小,我們選Lb=256,Sb=48,這在特徵描述和運算時間上取得較好的平衡。
BRIEF特徵向量描述器的優勢是運算和比較速度非常快(Lb=256個位時,每個關鍵點是17.3微秒)。這些描述器只是特徵向量的一個位,測量兩個向量之間的距離可以通過計算它們之間不同位的數量來解決,也就是用漢明距離計算兩個向量對應位置的不同字元的個數,(換句話說,它就是將一個字串變換成另外一個字串所需要替換的字元個數),通過執行xor異或操作就可以了。這種方法比SIFT或SURF更適合這個應用,在SIFT或SURF特徵向量描述中,計算歐氏距離使用的是浮點運算。
由具有層次結構的詞袋模型、順序索引和逆序索引組成影象資料庫,如圖1所示,這個影象資料庫用於偵測之前訪問過的地方。
詞袋模型是使用視覺字典將一副影象轉換成離散數字向量,用於管理影象的資料集。視覺字典通過將視覺單詞W用向量描述空間儲存,在離線狀態下建立而成。與SIFT或SURF特徵向量不同,我們採用二進位制向量描述空間,建立一個精簡的字典。在層級架構詞袋模型上,字典組織成一個樹狀結構。通過訓練影象提取具有豐富資料的一組特徵,這與那些稍後線上建立的獨立開來。採用K-medians聚類演算法(資料探勘,機器學習的重要分支)[k-means++: The advantages of carefulseeding]先將提取的特徵向量分成kw二進位制聚類。並將產生的非二進位制值直接轉換成0。這些聚類形成字典樹裡的第一層節點。其他層的節點通過同樣的方法計算出來,直到Lw層。最後,我們得到一個有W個葉子的樹,也就是W個單詞的字典。每個單詞根據其在訓練文集庫中的相關性分配權重,減小那些經常使用的單詞的權重,這樣他們的區別就不明顯。我們通過[Video Google: A text retrievalapproach to object matching in videos]文章中的方法,採用使用頻率反向分類(tf-idf: term frequency-inverse document frequency)方法進行處理。然後,將影象It,在時間t內,轉換成詞袋向量Vt∈Rw,特徵的二進位制描述器遍歷字典樹,選擇每層的中間節點使得漢明距離最小化。
為了檢驗兩個詞袋向量v1和v2的相似度,我們計算L1的值s(v1,v2),這個值的在0到1之間[0…1]:
(2)
影象詞袋由逆序指標指示。這個結構用於儲存視覺單詞wi,視覺單片語成視覺字典,視覺字典形成影象It。這樣當檢索影象,作比較操作時,就不會對比影象中那些一樣的視覺單詞,這對檢索資料庫非常有用。我們用逆序指標指向一對資料<It, vti>,可以快速獲取影象上的視覺單詞的權重。當新的影象It加入到資料庫中的時候,逆序指標就會更新,指標也方便在資料庫中查詢影象。搜尋影象時,詞袋模型中的兩種結構(詞袋和逆序指標)只有一種會經常用到。在常用的方法中,我們用順序指標可以方便地儲存每幅影象的特徵。我們通過以下方法將字典中的節點分層,假如樹一共有l層,從葉子開始為0層,即l=0,到根結束,l=Lw。對於每幅影象It,我們將l層的節點儲存在順序指標中,而l層是影象It的視覺單詞的父節點,區域性特徵ftj與節點關聯。我們用順序指標和詞袋模型樹估算BRIEF向量描述器中的最鄰近的節點。對於特徵相同的單詞或具有共同l層父節點的單詞,當我們計算特徵的相關性時,這些順序指標可以加快幾何驗證過程。當獲取一個將要匹配的候選特徵時,幾何驗證非常必要,新的影象加進資料庫,順序指標就會更新。
我們基於之前的工作《CI-Graph SLAM for 3D Reconstruction of Large and ComplexEnvironments using a Multicamera System》和《Robust PlaceRecognition With Stereo Sequences》,提出檢測閉合迴路的演算法。具體步驟如下面四步所示:
A. 資料庫查詢
我們用影象資料庫儲存和查詢任何一副給定的影象。當影象It被轉換成詞袋向量Vt時,在資料庫中查詢Vt,查詢到一系列的匹配的候選向量對<Vt, Vt1>,<Vt, Vt2>,… ,和與它們關聯的相似度值S(Vt, Vtj)。這個相似度的值與影象和影象上視覺單詞的分佈相關。我們將相似度值進行排列,希望向量Vt順序排列,通過文章《Robust place recognition with stereo sequences》中的工作規範化相似度值η:
我們通過s(Vt, Vt-Δt)計算Vt的值,Vt-Δt是前一幅影象的詞袋向量。s(Vt, Vt-Δt)很小時,比如機器人在轉彎的時候,會錯誤地造成高數值。這樣,我們就忽略沒有到達最小值的影象,或者指定特徵的數量。這個最小值會去掉一些影象,這些影象可能有被用於正確地偵測閉環迴路的相似度值η。那麼,我們就用一個比較小的值來防止有效的影象被丟棄。我們去掉那些影象,它們的η(Vt,Vtj)小於這個最小的閾值
Parallel Tracking and Mapping for Small AR Workspaces
作者: Geoge Klein, David Murray 2007年
小型增強現實工作空間的並行自主導航與地圖構建
翻譯:Taylor Guo 2016年2月24日
本文並不一字一句翻譯,而是根據實際專案需求和產品應用,略去次要部分,選取主要部分,以求快速掌握實際應用方案。
如需完整文件,請自行學術搜尋。
概要:本文主要講在未知場景中,對攝像頭位姿估計的方法。與機器人中採用SLAM類似,我們針對小型增強現實工作空間裡手持式相機進行自主導航和定位。
自主導航和地圖構建將分成兩個執行緒:追蹤相機的運動和從影象幀裡處理3D導航地圖的點特徵。這裡會涉及到優化技術和應用的實時性:本應用裡面的地圖在自主導航裡面使用上千個地標,是最新的精確的健壯的系統。
1. 應用簡介
增強現實使用給使用者提供更多資訊的環境。可以用於城市導航地圖、零件的CAD模型、甚至是一些離散的資訊。該應用可以使使用者和靜止的物體動態互動,如果模型或地圖對機器或程式來說易於理解,那麼增強現實應用的註冊資訊就可以直接執行,這其實也是基於相機的增強現實的主流方法。
不幸的是,機器程式易於理解的地圖並不存在,它需要物體被標記。因此,需要感測器來獲取這些特徵,而感測器又有使用範圍和質量的限制。資訊的註冊也就限制了追蹤效果。那麼,在增強現實應用中,就會使用擴充套件的追蹤方法,就是在未知的場景裡預先新增資訊來獲取最初需要的資訊,這樣就避免之前感測器檢測不到某些未知地圖的狀況。最開始地圖是一個比較小的點陣,後面的版本mono-SLAM演算法已經可以不需要預先提供初始資訊或地圖了。
本文討論使用校準過的相機在未知場景中構建環境地圖。建立環境場景後,將虛擬物體放入場景中,在這個過程中可以精確地與真實物體關聯。
我們並沒有預先加入足夠的資訊到使用者使用環境中,很多增強現實應用就不適用。我們的方法是通過遠端專家提供有意義的提示和註解,本應用中採用預先虛擬模擬的沙盤。
我們從地圖的雲點估計一個飛機的模型,這可以推廣到一般的物體的虛擬特徵。如圖所示。實際上,我們將平面物體(有紋理)轉換成互動的立體的虛擬影像,在這個階段,我們開發了簡單的遊戲。相機介面變成了同時觀察和使用者互動的工具。
為了能讓使用者更自由地與虛擬環境互動,我們需要快速、精確和健壯的相機追蹤演算法,當進入新場景時,能重構地圖,那麼這樣就有一些限制,場景要儘可能小,要靜止畫面不能扭曲。小,意味著使用者需要花更多的時間在同一個地方,如桌子、房間角落或單一建築物前。我們也考慮到應用的擴充套件,擴充套件到大型的增強現實工作空間,如城市。
2. SLAM方法
方法總結:
a. 自主導航和地圖構建分離,用兩個並行的執行緒;
b. 地圖構建基於關鍵幀,使用批處理方法(使用Bundle Adjustment 減小誤差)
c. 地圖的初始化採用立體匹配
d. 更新的點陣通過極值點獲取
e. 獲取大量的點用來構建地圖
這裡可以比較一下目前最新的方法。手持相機的同步導航和地圖構建,EKF-SLAM和FAST SLAM,導航和地圖構建緊密地關聯,相機的位姿和圖示的位置根據每幅影象幀同時更新。我們認為手持相機比移動的機器人更難追蹤:機器人獲取的資料可以測得距離;機器人可以以很慢的速度移動。相反,單目手持相機無法應用在這種場景中,資料融合產生錯誤,不可避免。而上面的兩種方法,可能會加大這種錯誤。即使通過JCBB和RANSAC演算法增強系統的健壯性,增強現實仍然無法使用。
這樣自主導航和地圖重構就要分開。兩個功能分開後,導航就沒有必要依賴於基於概率論的地圖構建,健壯的自主導航方法就可以加入。實際上,兩個功能之間並沒有資料關聯。由於計算機多執行緒處理能力,自主導航功能就貫穿於整個影象處理過程中,並增強效能。
當相機沒有移動的時候,影象幀裡包含足夠多的資訊,沒有必要每一幀都拿來做地圖構建。我們主要處理少量有用的關鍵幀。這些關鍵幀的能實時地處理,這個過程是在下一個關鍵幀進來之前完成。然後,用高度精確的批處理演算法處理後面的地圖構建,這個演算法如Bundle Adjustment.
Bundle Adjustment 在視覺里程導航中被證明行之有效,我們覺得采用這個方法。首先,通過立體5點構建初始地圖,然後用本地Bundle Adjustment追蹤相機最近的N個位姿,以獲取較長距離下的期望精度。當系統初始化後,我們使用本地地圖更新,我們試圖構建全域性地圖,那些特徵點可以再次被訪問,這樣就可以提供全幅地圖優化。最後,我們不採用2D追蹤而使用極值特徵搜尋。
3. 更進一步工作
系統採用UKF,使用了很少的特徵點構建地圖。
還有采用了學習演算法,預先標記點追蹤,識別特徵,在訓練階段採用經典的Bundle Adjustment 演算法,追蹤效能不錯,但沒有經過學習後,沒有後續嘗試。還有通過其他的估計方法發了論文,說更精確,更健壯,但犧牲了系統性能,處於不穩定狀態。
還有采用了SfM方法,加入了慣性感測器和魚眼透鏡,從3D位姿估計中耦合了2D特徵導航演算法,健壯性增強。
4. 地圖
地圖由M個特徵點構成,位於世界座標w下。地圖Pj中的j點,座標為Pjw=(xjw,yjw,zjw,1)T。每個座標由nj個畫素點組成。
地圖系列由N個關鍵幀。每個關鍵幀以相機為中心點的座標系,第i個關鍵幀是ki.
世界座標系與關鍵幀座標系的轉換為:Ekiw.
每個關鍵幀有4個8bpp灰度值的影象金字塔;第0層存了一幅640x480的照片,第3層子抽樣解析度是80x60。
並不是每個畫素都單獨儲存,觀察到每幀的特徵點後,只儲存這個幀的特徵點。每個地圖有一個關鍵幀,每個關鍵字有一個金字塔組合,畫素位於金字塔的層級中。
在金字塔層級中,每塊是8x8的畫素方塊;在世界座標系下,塊的大小取決於金字塔層數,到關鍵幀中心的距離,還有塊的方位。
後面的例子裡,每個地圖上有2000到6000個特徵點M,有關鍵幀N=40到120個。
5. 自主導航
在3D地圖估計方法構建後,將設計基於特徵點的自主導航系統。
導航系統獲取影象,實時估計相機位姿構建地圖。
基於這樣的估計,虛擬的增強影象可以畫在相機動畫幀的上面。
每幀畫面上,系統執行如下導航步驟:
1. 獲取新的影象幀,根據運動模型預先估計位姿;
2. 根據影象幀的位姿估計,地圖特徵點投射到照片上;
3. 根據少量的(50)粗略的特徵搜尋影象;
4. 根據這些粗略匹配更新相機位姿;
5. 根據大量的(1000)特徵點對映的影象再次搜尋;
6. 在所有匹配後,最終的關鍵幀的位姿估計就計算出來了。
5.1 擷取影象
相機可以提供640x480畫素的影象幀,速率30Hz。這些幀可以轉換成8bpp灰度,用於自主導航和增強現實顯示。
導航系統構建4層影象金字塔,每層用FAST-10 conrner detector掃描。
相機位姿的估計模型:decaying velocity model. 有點像a-b constant velocity model,但缺少測量,預估過程速度會下降,最終停下來。
5.2 相機的位姿和對映
為了將地圖上的點投影到飛機圖片上,需要將世界座標系轉換成以相機為中心的座標系C。
可以通過矩陣4x4 Ecw 與矩陣的相乘(線性變換與線性變換的乘積),獲得相機的位姿: Pjc=Ecw x Pjw (1)
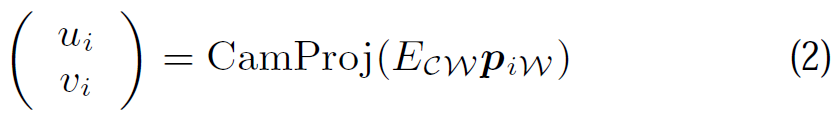
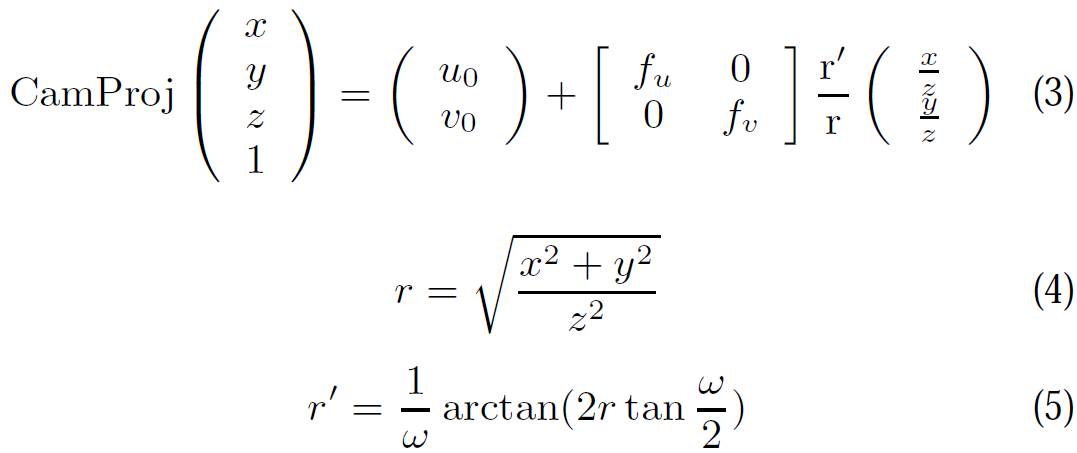
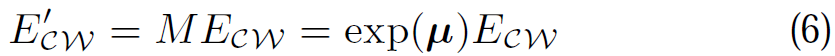
5.3 圖塊搜尋
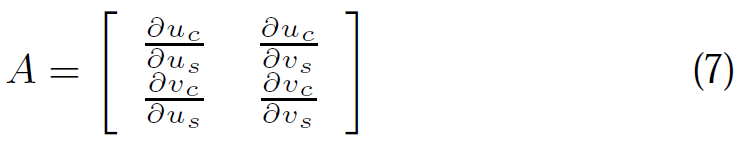
5.4 位姿更新
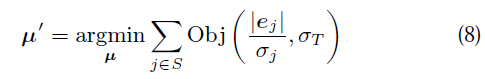
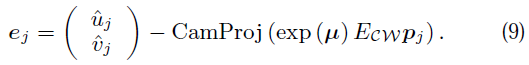
5.5 導航優化
為了增強導航系統對相機運動、圖塊搜尋和位姿更新的適應能力,我們需要做兩次。初步粗略搜尋只搜尋當前影象金字塔的當前幀的最上面一層50個點。這樣搜尋範圍就比較大。新的位姿就可以計算出來。然後,1000個影象塊繼續搜尋。更精細的搜尋將在更高一級的金字塔影象塊中。最終的位姿就是這樣一個由從粗到細的過程。
5.6 導航功能質量與錯誤恢復
6 地圖構建
6.1 地圖初始化
6.2 關鍵幀插入和極值搜尋
6.3 Bundle Adjustment
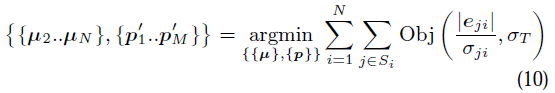
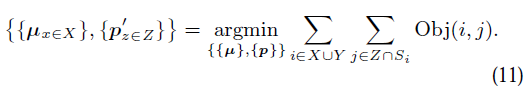
6.4 資料關聯精細化
6.5 程式執行備註
7 結果
7.1 視訊導航效能

7.2 地圖構建狀況

7.3 與EFK SLAM合成對比分析

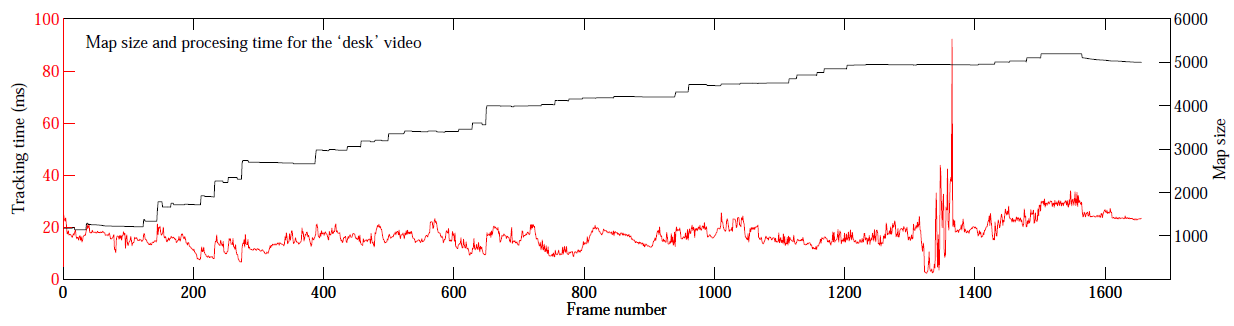
7.4 與EFK SLAM子集對比分析
7.5 手持式相機AR
8 後續工作的不足

8.1 失敗分析
8.2 地圖構建不充分
9 結論
