
倉庫規模作業系統的背景之叢集排程
前言
本文是Malte Schwarzkopf的博士論文《Operating system support for warehouse-scale computing》一個翻譯版本,融入了作者自身的經驗和理解,讀者如果想閱讀原文,可以訪問:http://people.csail.mit.edu/malte/pub/dissertations/phd-final.pdf
編寫本文的目的是提供一箇中文版本的文件,同時為自己保留一份學習筆記,供日後事件參考以及優化調整。當然,優化調整部分不能更新在公網,因為筆者同一時間在公司內網釋出了改文章,相應部分只會更新在公司內網的文章中。
叢集排程
如前節所述,叢集排程器是當今用作資料中心作業系統的基礎設施系統的關鍵部分。此外,硬體異構性和同位干擾帶來的挑戰可以通過良好的叢集級排程來解決或至少減輕。
當然,計算資源(比如機器)來排程任務(比如並行任務)不是一個新問題。在CPU排程方面存在大量的前期工作,但是作業系統 CPU排程器不同於叢集排程器:它們在上下文切換期間短時間內被呼叫,並且在做出決策時阻塞使用者空間程序。相比之下,叢集排程器與叢集工作負載一起連續執行;它的排程決策持續時間更長;並且它具有比單機CPU排程器更復雜的設計目標。
在本節中,我概述了現有叢集排程器的設計目標以及它們是如何實現的。表2.8總結了每個系統的核心設計目標。

表2.8:叢集排程器及其設計目標。✔️表示該屬性是一個設計目標,✘表示它不是一個目標並且不受支援。(✔️)表示系統可以通過其API支援該目標,內建支援。
排程程式體系結構
現有叢集排程器的體系結構主要分為:中心排程和分散式排程,圖2.9說明了我討論的方法。

圖2.9:不同叢集排程器架構的比較。灰色框表示叢集機器,彩色圓圈對應於不同應用程式的任務。
大多數早期的叢集排程器都是較大的單體:它們具有簡單、中心化的體系結構,並且通過相同的邏輯處理所有決策。通常,單體排程程式在專用機器上或作為叢集管理器的一部分執行。這種方法的優點是相對簡單:所有狀態都儲存在一個地方,並且只有一個決策實體(圖2.9a)。排程器容錯可以通過主/從熱備或通過從先前儲存的檢查點重新啟動排程器來實現。
然而,近期工作引入了分散式叢集排程器體系結構,然而目的不同:
專用框架之間的資源共享:資料中心同時執行許多基礎設施系統和應用程式(參看以前的章節),這需要跨使用者和系統劃分叢集資源。許多基礎設施系統還執行它們自己的應用程式級任務排程(例如,MapReduce分配map和reduce任務)。因此,兩級排程器有一個資源管理器來分配資源和一個程式級排程器來分配應用級任務到匹配的資源。資源管理器比單體排程器簡單,因為它忽略了應用程式語義和排程策略。相比之下,應用程式排程器使用應用指定的排程邏輯來排程任務,但是隻檢視它們分配到的資源(圖2.9b)。
Yahoo的Hadoop-on-Demand(HoD)是一個早期的兩級排程器。它結合了TORQUE資源管理器和Maui HPC排程器,從共享池中分配使用者叢集。隨後,Mesos和YARN設計了正規的兩級體系結構,通過提供(Mesos)或請求(YARN)來複用資源。筆者幾年前設計並實現的基於海量視訊、圖片的高效能運算平臺PCC(high Performance Cluster Computing)也是兩級架構,分為OS和Framwork兩層,OS層模擬作業系統提供資源管理,Framwork為不同的業務(視訊、圖片)實現針對性任務排程。
工程複雜性:叢集工作負載的多樣化需求使得管理大型組織和持續迭代單個排程器基線程式碼具有挑戰性。
Google的Omega叢集管理器因此引入了部分分散式、共享狀態、分散式邏輯排程器架構。Omega支援同一叢集內多個共存的排程器。排程器可以基於不同的實現並分散式執行,每個都處理部分工作負載。然而,不同於兩級排程器,所有排程器都包含完全共享的、弱一致性的叢集狀態副本。它們通過針對叢集狀態發出樂觀併發的事務來改變叢集狀態(圖2.9c)。事務可能產生成功的任務放置,或失敗就需要重新嘗試。Microsoft的Apollo對這個模型做了更進一步的研究,僅發現並解決叢集機器中工作端(worker-side,我的理解是相比於管理端,通用節點統稱為工作端)佇列的衝突。
對非常短的任務的可伸縮性。一些互動式查詢的分析型工作負載必須在幾秒鐘內返回資訊的,為了促進這一點,工作被分解成大量非常短暫的任務。這種小的任務粒度增加了利用率,並且減少了掉隊任務(traggler task,我的理解是由於某種原因執行速度偏離了預期的任務)對作業完成時間的影響。
短任務只存在亞秒的持續時間,因此排程開銷(無論中心式排程還是共享狀態的事務)可能很大。Sparrow完全分散式排程器通過完全避免共享狀態和協調來解決這個問題。相反,叢集機直接從排程器拉取任務以響應探測(圖2.9d)。
不同的解決方案適合不同的環境,沒有哪個架構比其他架構更好一說。
資料區域性性
資料的引用位置在計算機系統許多工程優化是關鍵,尤其是處理器中快取記憶體機制的有效性。分散式系統也有“位置”的概念:如果任務的輸入不在本機上,則必須通過網路獲取,這必然會引起延遲並增加網路利用率。為了避免這種成本,叢集排程器旨在增加對本地資料進行操作的任務數量。
Google的MapReduce優先地將map任務安排在輸入資料塊可用或者在相同葉子交換機的機器上,並且其他系統也採用類似的優化。相關研究性工作進一步完善了這個概念:延遲排程拖延任務啟動,希望任務“運動”會有更好的位置可用;Scarlett增加了普通輸入資料的副本,以資料本地化程度;Quincy權衡遷移已經執行的任務並重啟他們帶來的開銷。
早期的工作針對磁碟位置進行了優化,因為從本地磁碟讀取資料比通過網路傳輸更快。然而,資料中心網路頻寬增加了,使得本地磁碟和遠端磁碟之間的差異越來越小。然而,位置仍然很重要:許多資料處理框架和儲存系統在RAM中快取資料,使得記憶體中物件的位置成為一個重要的問題。此外,最近的機器學習工作負載對GPU具有區域性約束,並且需要仔細布置以確保其任務之間足夠的網路頻寬。即使基於NVMe快閃記憶體裝置的網路儲存(每個機器上沒有本地資料)也需要需要小心地在具有足夠CPU和網路容量的位置上佈置工作負載。
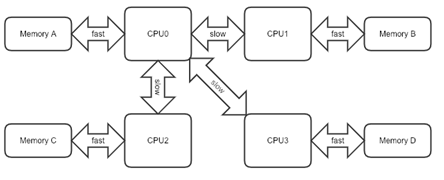
此外,機器內也有的位置概念:NUMA系統中的“相對比較遠”的記憶體訪問成本很高,PCIe裝置的位置對於高效能網路訪問很重要。關於機器內這種細粒度位置的資訊通常只對本地核心CPU排程器可用,而對叢集排程器不可用。
關於NUMA的說明:雖然記憶體直接attach在CPU上,但是由於記憶體被平均分配在了各個die上。只有當CPU訪問自身直接attach記憶體對應的實體地址時,才會有較短的響應時間(後稱Local Access)。而如果需要訪問其他CPU attach的記憶體的資料時,就需要通過inter-connect通道訪問,響應時間就相比之前變慢了(後稱Remote Access)。所以NUMA(Non-Uniform Memory Access)就此得名。如下圖所示:
約束條件
對於一些特別應用僅僅資源平等並不適合:特定硬體特性的可用性(例如基於快閃記憶體的儲存或通用GPU加速器)、軟體相容性約束(例如特定核心版本)以及同位首選項(接近關鍵服務或遠離負面干擾應用程式)全部有助於任任務排程。
因此,排程有時受到佈局限制。這樣的約束在實踐中非常常見:例如,50%的Google Borg任務具有某種簡單形式的與機器屬性相關的放置(placement,理解為任務放置在機器上執行)約束,13%的生產工作負載具有複雜的約束。
一般有三種類型的約束:
軟約束:指定“優先”位置,指示任務受益於某個屬性的存在。例如,I/O密集型工作負載(如日誌爬行)可能對具有快閃記憶體的機器具有軟約束。排程器可以選擇忽略軟約束並繼續排程任務。
硬約束:相比之下,排程器必須滿足硬約束。具有硬約束的任務直到找到滿足其要求的位置才能被排程(或者搶佔)。在快閃記憶體示例中,如果任務不能使用較慢的儲存裝置執行則此約束是適當的(例如,支援分散式事務系統的快速、持久日誌)。同樣,需要特定硬體加速器的應用程式將使用硬約束(比如基於GPU的AI應用)。
複雜約束:在本質上可以是硬約束或軟約束,但是對於排程器來說很難處理。不僅依賴於機器屬性,還依賴於機器上執行的其他任務和其他併發放置(比如某個資源最多支援多少個應用併發使用)決策的組合約束是複雜約束的典型示例。在上面提到的快閃記憶體示例中,組合約束可以指示一次只能執行一個任務使用機器上的快閃記憶體裝置。
熟悉Kubernetes的讀者不難發現親和性(affinity)與本文討論的約束非常相似,而本文提到很多次的Google Borg,Kubernetes就是他的開源版本,就要像MapReduce/GFS的開源版本是Hadoop一樣。
約束減少了給定任務可用的可能放置數量,因此導致增加的排程延遲。
許多排程器支援約束,但是對於所支援的型別幾乎各不相同。例如,Sparrow和Choosy只支援硬約束,並將它們用作排程時的過濾器。另一方面,Quincy通過每個任務放置首選項支援軟約束,但不支援硬約束。 Quasar支援軟高階效能約束,但是依賴於排程器的配置和通過糾正措施滿足它們效能的預測機制。
相比之下,YARN的資源管理器支援軟約束和硬約束,alsched不僅二者都支援,也支援複雜約束。然而,tetrisched隨後也提出對軟約束的支援是足夠的,並且提供了一些很吸引人的特色。
對約束的支援是高階排程策略的表示、排程器複雜性和作業等待時間之間的權衡。由於工作負載和操作環境的不同,不同的叢集排程器做出不同的選擇。
公平
大多數倉庫規模的資料中心由單個機構運營,但是仍然執行來自不同組織單元、團隊或外部客戶的大量工作負載。這些使用者可能會採取敵對行為,以便增加它們在叢集資源中的份額。因此,叢集排程器分配共享資源,並且旨在提供公平性。
有些系統依靠任務通量趨向使用者的公平共享,資源根據使用者的公平共享提供給使用者,但是如果分配變得不公平,則執行任務不被搶佔。Hadoop Fair Scheduler(HFS)就是這樣一種基於通量的方法,它通過將MapReduce分成“作業池”(HFS)來公平地分享它。Sparrow分散式排程器使用類似的方法:任務在每個worker處經歷加權公平排隊,並且當任務以不同的速率執行時,叢集的公平共享顯現出來。
相比之下,Quincy搶佔執行任務以強制執行公平份額。它將排程問題建模為網路流優化,每當其求解器執行時強制執行更新的公平共享。為了保證進度,Quincy不會在任務執行一段時間後搶佔它們;因此,暫時的不公平仍然存在。
一些策略支援多個資源維度上的公平共享:例如,主導資源公平演算法(Dominant Resource Fairness DRF)通過確保每個使用者在所有維度上至少接收到他的合理份額來提供多維最大最小公平(max-min fairness)。DRF已經被證明具有激勵使用者共享資源和誠實地陳述其需求的特性。DRF變體也存在於關於放置約束(Choosy中的受約束最大最小公平CMMF)和分層分配委託(H-DRF)的公平分配。
雖然強公平性很吸引人,但尚不清楚它在單一機構的資料中心中有多大用處。有趣的是,許多生產系統依賴帶外(out-of-bands)機制來確保近似公平的共享。此外,即使排程器可以分配公平的資源共享,異構性和干擾也會導致看似相同的資源分配但實際差異顯著。
動態資源調整
大多數叢集排程系統假設所有作業的任務要麼具有統一的資源需求(例如,具有固定大小的MapReduce工作“槽”),要麼使用者在作業提交時指定資源需求(例如,在Borg、YARN和Mesos)。
然而,一些叢集排程器支援動態調整資源分配。這對於利用閒置資源、deadline內完成工作或應對變化的負載是有益的。
Omega的MapReduce排程器在可能的情況下試圖分配額外的資源以增加並行度;如果分配的資源沒有得到充分利用,Apollo同樣會在作業內試圖啟動額外任務。
如果SCOPE作業存在超過deadline的風險,Jockey動態地增加資源分配,如果存在餘量,則減少其資源分配。類似地,Quasar基於同位和機器型別自動申請“正確大小”的資源並選擇最佳可用資源;它增加資源分配,直到滿足使用者指定的效能約束為止。最後,Borg的“資源回收”機制動態地將任務的資源請求減少到圍繞其實際使用的邊緣值,以便減少預留過多資源並提高利用率。
這些例子強調了資源分配可以由排程器動態調整。然而,最通常的情況是,讓應用程式內省它們的效能並在必要時請求額外的資源。
總結
正如我在前面節中已經討論的,良好的排程決策對於叢集資源的有效使用至關重要。本節已經調查了許多現有的叢集排程器。我從研究它們的體系結構開始,然後討論了幾個理想的特性:支援叢集內區域性性、放置約束、公平性和動態資源調整。
然而,現有的排程器很少有能夠解決前面強調的機器異構性和工作負載干擾挑戰。然而,在叢集資源高利用率條件下實現確定性工作負載效能,叢集排程器必須:
- 整合機器級資訊和叢集級資訊,基於細粒度任務分析、機器型別和位置資訊做排程決策;
- 通過定位那些可以很好工作在一起的任務避免存在負面干擾的工作負載共享硬體;
- 靈活的、允許根據工作負載指定的排程策略,以便排程器能夠針對期望的用例進行定製。
後面的章節我會討論一個支援這些目標的新排程器。